• Структура вида Имя/Размерность, где Имя - это атом, а Размерность - целое число. Эта запись определяет предикат с функтором Имя, число аргументов которого равно Размерность. Так spy сорт/2 вызвало бы установку контрольных точек на целевые утверждения предиката сорт с двумя аргументами.
• Список. В этом случае список должен заканчиваться пустым списком '[]', а каждый элемент списка сам должен быть допустимым аргументом для предиката spy. Пролог установит контрольные точки во всех местах, указанных в списке. Так spy[copт/2, присоединить/3] вызвал бы установку контрольных точек на предикат сорт с двумя аргументами и на предикат присоединить с тремя аргументами.
debugging
Встроенный предикат debugging позволяет увидеть, какие контрольные точки установлены на текущий момент. В качестве подобного эффекта выполнения целевого утверждения debugging печатается список всех контрольных точек.
nodebug
Целевое утверждение nodebug вызывает устранение всех контрольных точек, установленных на текущий момент.
nospy
Подобно spy, nospy является префиксным оператором. Предикат nospy является более селективным, чем nodebug, так как вы можете точно указать, какие контрольные точки должны быть удалены. Это достигается путем указания аргумента, задаваемого в точности в такой же форме, как и для предиката spy. Так, целевое утверждение nospy[обр/2, присоединить/3] приведет к тому, что будут удалены все контрольные точки с предиката обр с двумя аргументами и с присоединить с тремя аргументами.
ГЛАВА 7. ЕЩЕ НЕСКОЛЬКО ПРИМЕРОВ ПРОГРАММ
В каждом разделе этой главы рассматривается некоторое конкретное применение Пролога. Мы советуем вам прочитать все разделы. Не огорчайтесь, если вы не поймете назначение какой-либо программы потому, что незнакомы с данной конкретной областью применения. Например, оценить значение символьного дифференцирования смогут лишь читатели, уже знакомые с дифференциальным исчислением. Тем не менее прочтите этот раздел, потому что программа нахождения символьных производных показывает, как установление соответствия между образцами используется при преобразовании структур одного вида (арифметическое выражение) в структуры другого вида. Самое главное – добиться понимания техники программирования на Прологе, находящейся в распоряжении программиста, независимо от конкретной прикладной задачи.
Мы надеемся, что набор задач достаточен, чтобы удовлетворить вкусам большинства читателей. Естественно, что все выбранные задачи относятся к таким областям, которые хорошо укладываются в те способы представления явлений реального мира, которые предлагает Пролог. Например, здесь отсутствует задача расчета потока тепла через трубу прямоугольного сечения. Правда, такие задачи тоже можно решать с помощью Пролога, однако выразительность и силу Пролога невыгодно демонстрировать на задачах, которые сводятся лишь к многократным повторениям вычислений над массивом чисел. Хотелось бы также рассмотреть и большие Пролог-программы, вроде тех, что используются в исследованиях по искусственному интеллекту для распознавания фраз естественного языка. К сожалению, цель такой книги как эта, не позволяет рассматривать программы, размеры которых превышают страницу текста и которые могут быть предложены лишь специально подготовленному читателю.
7.1. Словарь в виде упорядоченного дерева
Предположим, что мы хотим установить отношения между элементами информации с тем, чтобы использовать их, когда потребуется. Например, толковый словарь ставит в соответствие слову его определение, а словарь иностранного языка ставит в соответствие слову на одном языке слово на другом языке. Мы уже познакомились с одним способом составления словаря: с помощью задания фактов. Если нам нужно составить таблицу выигрышей на скачках, проводившихся на Британских островах в течение 1938 г., то мы можем просто определить факты вида выигрыши(Х, Y), где X - кличка лошади, a Y – количество гиней (денежных единиц), выигранных этой лошадью. Следующая база данных может рассматриваться как часть этой таблицы:
Выигрыши(abaris,582).
Выигрыши(careful,17).
Выигрыши(jingling_silvee,300).
Bыигрыши(majola,356).
Если мы хотим узнать, какую сумму выиграла лошадь по кличке maloja, нам нужно просто правильно построить вопрос и Пролог даст нам ответ:
?- Bыигрыши(maloja, X).
X=356
Напомним, что Пролог просматривает базу данных сверху вниз. Это значит, что если база данных нашего словаря упорядочена в алфавитном порядке, как в приведенном выше примере, то на поиск суммы выигрыша для ablaze Пролог затратит меньше времени, чем на поиск суммы выигрыша для zoltan. Однако хотя Пролог способен просмотреть свою базу данных гораздо быстрее, чем вы сможете просмотреть напечатанную таблицу, неразумно просматривать таблицу с начала до конца, если известно, что данные искомой лошади расположены в самом конце. Точно так же, хотя в Прологе имеются специальные средства быстрого просмотра базы данных, он не всегда проходит так быстро, как хотелось бы. В зависимости от размеров таблицы и от того, сколько информации хранится о каждой лошади, Прологу может потребоваться на просмотр таблицы неприемлемо большое время.
По этим и другим причинам специалисты по информатике потратили немало сил на поиски хороших способов организации хранения таких данных, как таблицы и словари. Сам Пролог использует некоторые из этих методов внутри себя при организации хранения своих собственных фактов и правил, но иногда их полезно использовать и в наших программах. Мы рассмотрим один такой метод организации словаря, который называется методом упорядоченного дерева. Метод упорядоченного дерева является одновременно и эффективным способом использования словаря и средством демонстрации того, насколько полезны списки структур.
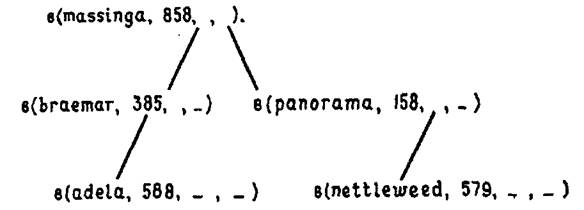
Рис. 7.1.
Упорядоченное дерево состоит из некоторого числа структур, называемых узлами, причем каждому входу словаря соответствует один узел. Каждый узел содержит четыре компоненты. Сюда входят два связанных с узлом элемента данных, как в предикате выигрыши в вышеприведенном примере. Один из этих элементов называется ключом, его имя определяет место в словаре (кличка лошади в нашем примере). Другой элемент используется для хранения какой-либо другой информации о данном объекте (сумма выигрыша в нашем примере). Кроме того, каждый узел содержит ссылку (наподобие ссылки на хвост списка) на узел со значением ключа, которое лексикографически (по алфавиту) меньше, чем имя, являющееся ключом данного узла, а также еще одну ссылку на узел со значением ключа лексикографически большим, чем имя, являющееся ключом данного узла. Будем использовать структуру, которую обозначим как в(Л,В,М, Б) (в - сокращение от «выигрыши»), где Л – кличка лошади (атом), используемая в качестве ключа, В – сумма выигрыша в гинеях (целое), М – структура, соответствующая лошади, кличка которой меньше, чем та, что хранится в Л, а Б – структура, соответствующая лошади, кличка которой больше, чем значение в Л. Когда для М и Б нет соответствующих структур, мы не будем их конкретизировать. Для небольшого множества лошадей указанная структура, будучи записанной в виде дерева, могла бы иметь вид, как представлено на рис. 7.1.
Если записать ее на Прологе в ступенчатом виде, учитывая ширину страницы, то она могла бы выглядеть так: