Насколько велик ваш геном?
Мы рассматривали ваш геном как базу данных из 20 тысяч белок-кодирующих генов, но это еще и физический объект – последовательность нуклеотидных пар A-T и Ц-Г, которые представляют собой ступеньки винтовой лестницы ДНК, занимающие физическое пространство. Давайте сначала рассмотрим нуклеотиды, а затем – само пространство. Ваш геном состоит примерно из 3 миллиардов спаренных нуклеотидов. Бактериальные геномы куда скромнее и обычно не превышают нескольких миллионов пар нуклеотидов (п. н.). У возбудителей туберкулеза и холеры, например, по 4 миллиона п. н., а у L. delbrueckii – около 2,3 миллиона. Но люди не особо выделяются и по этому параметру. Геном мыши сравним по размеру с вашим, а геном плодовой мушки примерно в 25 раз меньше. Меньше и геном риса: всего около 430 миллионов п. н. (Если это кажется вам странным – ведь у риса же так много генов, – не переживайте, вскоре мы к этому вернемся.) Зато особенно велики геномы саламандр, включающие от 14 до 120 миллиардов п. н. ДНК двоякодышащих рыб состоит из 130 миллиардов п. н., а геном растения Paris japonica – из колоссальных 150 миллиардов, то есть он в 50 раз больше человеческого и, вероятно, может считаться рекордсменом по размеру. Казалось бы, его превосходит геном одноклеточной амебы Polychaos dubium, составленный из 670 миллиардов п. н., но это спорное число, поскольку определялось устаревшими методами. (Я поражен, что никто еще не пересмотрел ДНК этого существа. Если вы читаете эти строки и располагаете свободным временем с секвенатором в придачу – дерзайте!) Как и в случае с числом генов, прямой связи между размером генома и сложностью организма не прослеживается7.
Считая гены и оценивая размеры геномов, мы обнаруживаем удивительную вещь. Как мы отметили, у человека 3 миллиарда пар нуклеотидов и около 20 тысяч генов, кодирующих уникальные белки. Размеры белков сильно варьируют, но в среднем человеческий белок содержит примерно 400 аминокислот, каждая из которых определяется тремя нуклеотидами ДНК. Следовательно, для создания 20 тысяч уникальных белков необходимо около 20 000 × 400 × 3 = 24 000 000 п. н. Но в человеческом геноме не 24 миллиона спаренных нуклеотидов, а 3 миллиарда. Этот геном в 100 с лишним раз больше содержащейся в нем белок-кодирующей ДНК! Так сложилось, что мы узнали длину человеческого генома раньше, чем его нуклеотидную последовательность и число генов в нем, и столь малое количество белок-кодирующих генов по сравнению с ожидаемым от генома такого размера стало для нас сюрпризом. У риса разница не столь велика, но все равно достигает порядка. Как правило, бо́льшая часть генома непосредственно не кодирует белки. Что же тогда она делает? Во многом это остается загадкой до сих пор. Некоторые участки генома транскрибируются в РНК, но потом не транслируются в аминокислотные цепочки. К ним относятся, как отмечалось раньше, независимо работающие молекулы РНК, а также сегменты РНК, которые вырезаются в ходе сплайсинга из транскрипта, синтезированного РНК-полимеразой, до его трансляции рибосомой. Впрочем, значительная часть некодирующей ДНК даже не транскрибируется в РНК, но может влиять на считывание генов, например, формируя места вроде промоторов.
Прежде чем углубиться в тему избыточности генома, давайте получше проработаем его физическую сторону. В начале этого раздела мы спросили: «Насколько велик ваш геном?» – и дали биологически точный, но физически неудовлетворительный ответ: в нем 3 миллиарда спаренных нуклеотидов[23]. Но насколько же он большой? Если вытянуть каждую из двух копий вашего генома, содержащихся почти во всех ваших клетках, в одну линию, длина этой линии достигнет метра. Диаметр клеточного ядра, где хранится ДНК, составляет всего несколько микрометров (миллионных долей метра).
Ваши клетки умещают метр ДНК в пространство, которое занимает одну тысячную одной тысячной этой длины. Не удивительно ли это? Такой вопрос, возможно, кажется вам глупым – само собой, удивительно. Однако я могу смотать 50 метров пряжи в клубок диаметром несколько сантиметров, и это никого не удивит. Здесь все упирается в механику – в жесткость ДНК: на что она похожа больше – на пряжу или на сталь? (Надеюсь, вы удивились бы, смотай я 50 метров оплетенного стального кабеля в клубок диаметром несколько сантиметров, даже если бы кабель был не толще нитки.)
Сгибается ли ДНК?
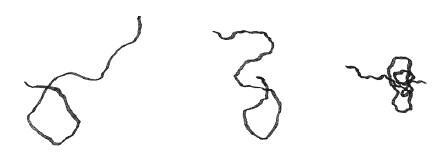
Оценка жесткости материалов – отдельная тема, грозящая погрузить нас в глубины материаловедения и отвлечь от биофизики. К счастью, существует концептуально простая модель жесткости полимеров – длинных молекул-цепочек, – которая позволяет нам судить о размере генома. Представьте три отдельные нити разной жесткости, одинаковые по длине при распрямлении, но в свободном состоянии склонные сворачиваться в аморфные клубки.
Интуитивно мы понимаем, что самая расправленная нить, состоящая из протяженных участков плавных изгибов, будет наиболее жесткой (на рисунке она левая). А нить, скрученная туже остальных (правая), скорее всего, окажется самой мягкой.
Давайте оценим протяженность, на которой молекула кажется прямой, – иными словами, то типичное расстояние, которое нам нужно пройти по нити, прежде чем окажемся лицом в другую сторону. Это расстояние тем больше, чем жестче молекула. Представьте, что муравей бежит по сухой макаронине: направление его движения со временем особо не меняется. Для такой макаронины типичная длина прямолинейного участка очень велика. Теперь представьте вареную макаронину, брошенную на стол. Муравей бежит по ней, часто петляя и поворачивая, а следовательно, длина прямых участков в этом случае, вероятно, не превысит и пары сантиметров.
Теперь мысленно разобьем естественно извитую молекулу на прямолинейные участки, длина каждого из которых соответствует типичной протяженности прямых в этой молекуле, и соединим их узлами, случайно задающими направление соседних отрезков (см. рисунок).
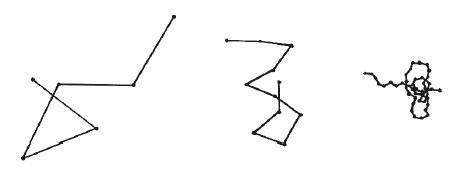
У нас получилось то, что физики и математики называют случайным блужданием. Представьте человека, который делает шаги в совершенно случайном направлении: один – на север, другой – на юго-запад, следующий – на северо-запад и так далее. Казалось бы, пытаться предугадать, где случайно блуждающий человек окажется после нескольких шагов, – совершенно пустая затея, ведь направление каждого шага случайно. Спрогнозировать движение отдельного блуждающего действительно невозможно. Но если представить множество случайных блужданий или понаблюдать за множеством случайно блуждающих, средний результат будет вполне определенным: после 25 шагов случайно блуждающий человек окажется в среднем в 5 шагах от исходной точки; после 49 шагов – в 7 шагах; после 100 – в 10; а после N шагов – в числе шагов, равном квадратному корню из N. (Это справедливо как для более привычного людям блуждания в двух измерениях, так и для блуждания в трех измерениях – например, если не шагать, а плавать.)
Случайные блуждания возникают в бесчисленном множестве ситуаций. Экономисты видят их в стремительных взлетах и падениях фондовых рынков. По типу случайных блужданий часто моделируют траектории плавающих бактерий и пути распространения случайных мутаций в популяции. Подобных примеров мы находим все больше и больше. Эти траектории – классический сюжет в обсуждении прогнозируемой случайности, поскольку надежные усредненные характеристики здесь сосуществуют с волей слепого случая. Кроме того, случайные блуждания, которым свойственна странная зависимость пройденного расстояния от количества шагов, позволяют нам познакомиться с масштабированием. Как мы узнаем во второй части книги, физические характеристики не обязательно увеличиваются пропорционально размеру: подобно упомянутому квадратному корню, между ними часто возникают неожиданные зависимости.