Box plot – это график, который показывает распределение данных и позволяет выявлять выбросы. Выбросы – это значения, которые сильно отличаются от остальных значений в выборке. Выбросы могут означать, что данные содержат ошибки, ошибки измерения или аномальные значения. Также выбросы могут быть результатом редкого события или непредвиденных условий, которые необходимо учитывать при анализе данных.
Гистограмма – это график, который показывает распределение данных по определенным интервалам или классам. Она может помочь понять форму распределения данных, например, нормальное, скошенное или мультимодальное распределение. Bar plot – это график, который используется для сравнения количественных данных между несколькими категориями. Он может показать, какие категории имеют более высокие или более низкие значения, и помочь выявить различия в данных между категориями. Выводы из гистограммы или bar plot могут помочь понять, какие категории или значения в данных являются наиболее значимыми или важными для анализа.
Внимание:
Как вы уже заметили, ChatGPT не только предоставляет вам код с решением, но и может подробно консультировать вас, объяснять сложные термины и помогать сделать выводы и заключения.
Это значительно упрощает процесс обучения и решения задач, позволяя вам получать не только готовые решения, но и понимать, как они работают и почему они правильны. Это очень полезно для тех, кто только начинает изучать программирование или машинное обучение, так как помогает закрепить теоретические знания на практике.
Шаг 4 Построение модели машинного обучения
Далее в книге мы предоставляем код, который поможет вам построить модель машинного обучения на основе подготовленного датасета и обучить ее предсказывать значения столбца "Survived" (выживший). С помощью этой модели вы сможете оценить вероятность своего выживания, если бы вы оказались на Титанике в тот роковой день.
Пользователь:
Библиотека pandas, matplotlib, seaborn уже установлены и наш файл titanic.csv уже загружен в переменную data.
Файл titanic.csv содержит следующие столбцы:
Survived: int64, Pclass: int64, Name: object, Sex: object, Age: float64, Siblings/Spouses Aboard: int64, Parents/Children Aboard: int64, Fare: float64
Столбец Survived – это целевая переменная, которую необходимо научится предсказывать на основании переменных Pclass, Name, Sex, Age, Siblings/Spouses Aboard, Parents/Children Aboard, Fare
Построй модель на языке python и обучи ее.
Предобработка данных на проверку дублей, пустых значений уже выполнена.
Чат:
Поскольку предобработка данных уже выполнена, приступим к построению и обучению модели. В качестве модели я выберу случайный лес (Random Forest) из библиотеки sklearn.
Сначала разделим данные на обучающую и тестовую выборки, а затем обучим модель.
Теперь, когда модель обучена, вы можете использовать её для предсказания выживаемости на новых данных.
Пример:
Таким образом, вы можете использовать обученную модель для предсказания выживаемости на основе данных о пассажирах.
Внимание:
Как вы заметили на представленном выше скриншоте, пользователь использовал слово "продолжай". Мы используем это слово в случае, когда по каким-то неизвестным нам причинам ChatGPT не завершает свой ответ до конца и обрывается на полпути.
Написание слова "продолжай" воспринимается чатом как инструкцию продолжить с того места, где он остановился. Однако, если мы напишем это слово, когда чат уже завершил свою мысль, то он воспримет это как просьбу дать нам еще примеров или информации по данному запросу.
Результат:
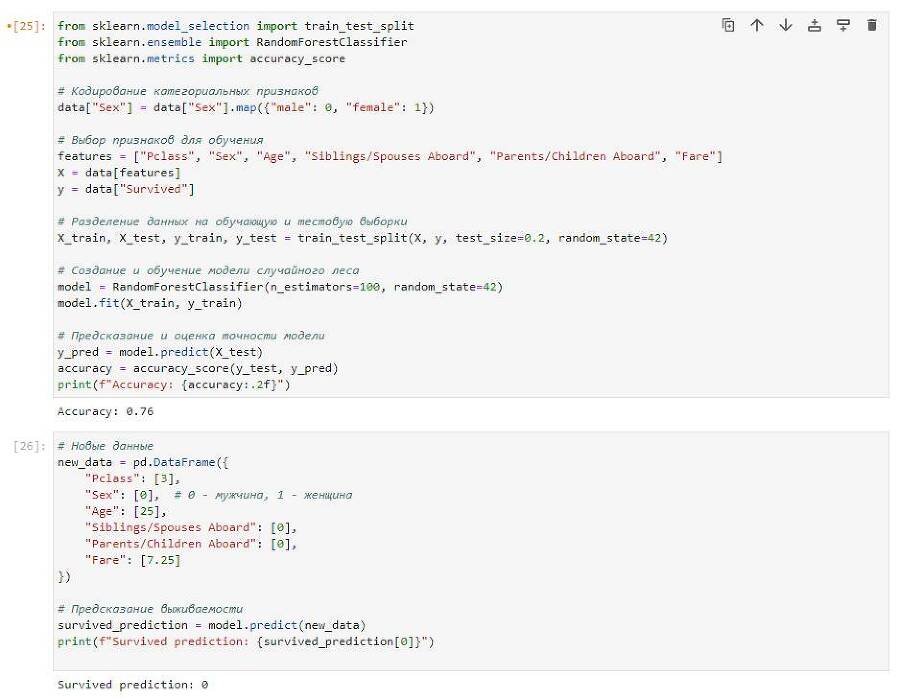
Выполняем все рекомендации Чата и посмотрим смотрим что из этого получилось.
Пользователь:
Что означает Accuracy: 0.76 и Survived prediction: 0
Чат:
Accuracy: 0.76 означает, что точность вашей модели составляет 76%. Точность (accuracy) – это доля правильно классифицированных объектов от общего количества объектов. В данном случае, модель правильно предсказала выживаемость пассажиров в 76% случаев на тестовой выборке. Это одна из метрик оценки качества классификации.
Survived prediction: 0 относится к примеру с новыми данными о пассажире. Значение 0 указывает на то, что модель предсказывает, что этот пассажир не выживет в случае кораблекрушения. В данной задаче классификации значение 0 соответствует классу "не выжил", а значение 1 соответствует классу "выжил".
Пользователь:
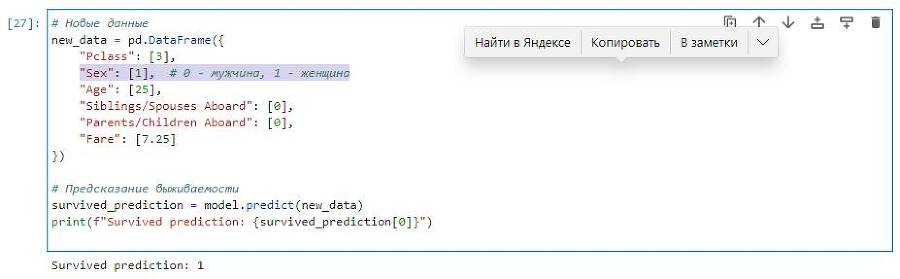
Давайте попробуем сделать изменения в коде самостоятельно, без запросов в ChatGPT. Мы заменим значения для предсказания на свои собственные, вместо мужчины мы подставим женщину, а все остальные параметры оставим без изменений.
Результат:
Выполняем все изменения и посмотрим смотрим что из этого получилось.
Получается, что женщина с теми же параметрами выжила. Это неудивительно, учитывая тот факт, что на борту спасательных шлюпок в первую очередь спасали женщин и детей. Мы можем сделать вывод, что пол пассажира был одним из факторов, влияющих на выживаемость в данном случае.
Пользователь:
Как добиться более высокой точности модели?
Чат:
Для достижения более высокой точности модели можно выполнить следующие шаги:
Инжиниринг признаков:
Создайте новые признаки на основе существующих данных. Например, вы можете создать признак "IsAlone" (один путешествует), если количество родственников на борту (Siblings/Spouses Aboard + Parents/Children Aboard) равно нулю.
data["IsAlone"] = (data["Siblings/Spouses Aboard"] + data["Parents/Children Aboard"]).apply(lambda x: 1 if x == 0 else 0)
Отбор признаков:
Оцените значимость признаков и исключите незначимые или шумные признаки из обучения.
Оптимизация гиперпараметров:
Подберите оптимальные значения гиперпараметров модели, например, используя поиск по сетке (GridSearchCV) или случайный поиск (RandomizedSearchCV) из sklearn.
Дополнительно – рекомендации автора:
Для более полного понимания метрик машинного обучения, их разнообразия и правильного выбора в различных ситуациях, мы рекомендуем ознакомиться с книгой того же автора под названием "Оценка качества моделей машинного обучения: выбор, интерпретация и применение метрик".
Также, если вам необходимо овладеть процессом машинного обучения для табличных данных и узнать, какие вопросы стоит задавать чат-боту при обработке таких данных, мы рекомендуем прочитать книгу этого же автора "Табличное Мастерство: Осваиваем Модели Машинного Обучения для Анализа Табличных Данных". Обе книги помогут вам овладеть профессиональными навыками в области машинного обучения и эффективно применять их на практике.
Выводы
Мы успешно прошли полный процесс машинного обучения на языке Python, начиная с загрузки и предобработки данных, их визуализации, разделения на обучающую и тестовую выборки, обучения модели и тестирования ее на данных, а также объяснения результатов и возможных дальнейших шагов.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «ЛитРес».
Прочитайте эту книгу целиком, купив полную легальную версию на ЛитРес.