Пользователь
Выведи все названия столбцов в одну строку и выполни шаги по предварительной обработке данных т.е. проверь на дубликаты, на наличие пропущенных значений и т.п. и выведи отчет по результатам предварительной обработки.
Чат:
Для выполнения этой задачи мы будем использовать библиотеку pandas.
Приведенный ниже код выполняет предварительную обработку данных и выводит отчет по результатам:
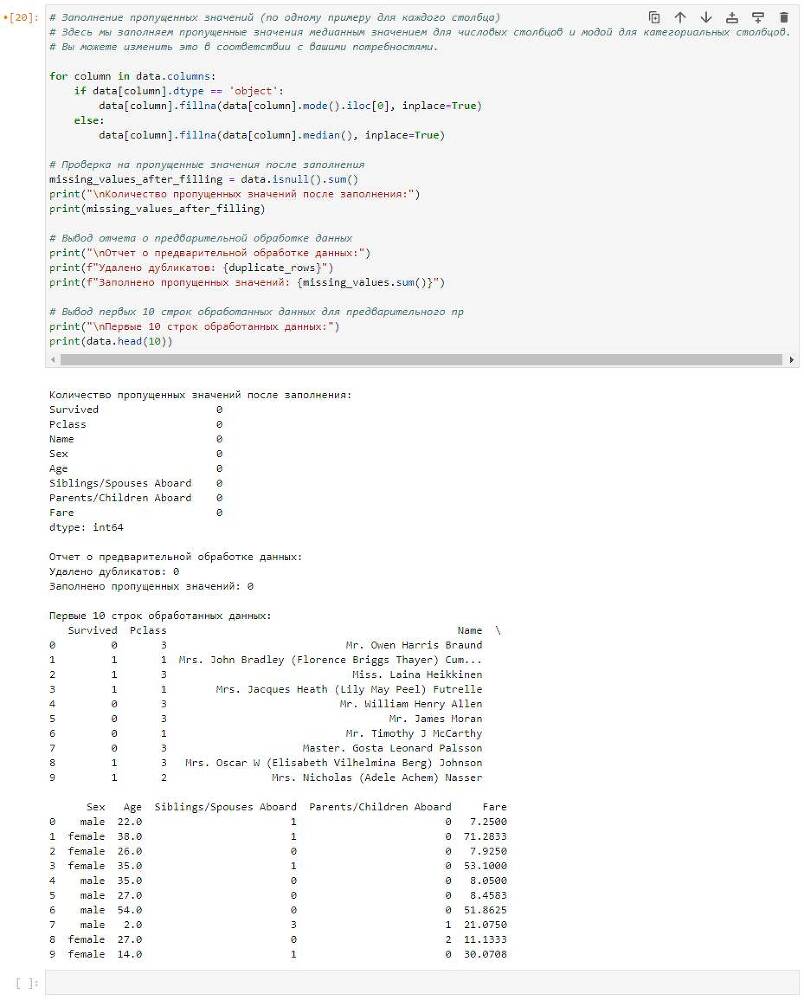
После выполнения этого кода вы получите отчет о предварительной обработке данных, включая количество удаленных дубликатов и заполненных пропущенных значений. Код также выводит первые 10 строк обработанных данных для предварительного просмотра.
Учтите, что вам нужно будет заменить 'titanic.csv' на действительный путь к файлу CSV на вашем компьютере или URL-адрес файла, если он доступен онлайн.
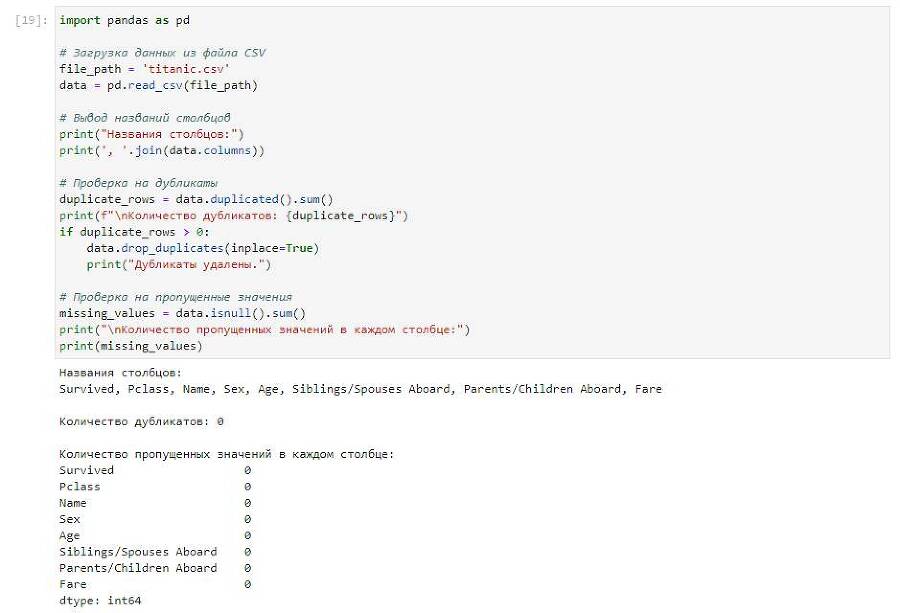
Результат:
Выполняем все рекомендации Чата и посмотрим смотрим что из этого получилось.
Внимание:
Мы заметили, что при каждом ответе ChatGPT повторяется код, который устанавливает библиотеку pandas для работы с табличными данными, и загружает данные из нашего датасета в переменную data. Чтобы избежать повторения этого кода, мы можем поступить следующим образом:
Пропустить эти строки кода и использовать только код, который расположен ниже.
Конкретизировать наши запросы, напоминая ChatGPT о том, что библиотека pandas уже установлена, и что файл titanic.csv уже загружен в переменную data.
Кроме того, мы рекомендуем напоминать ChatGPT о том, какие названия столбцов у нас есть в датасете, и какого они типа. Это поможет нам точнее работать со столбцами в нашем датасете. Для этого мы можем попросить ChatGPT вывести названия столбцов и их типы в одну строку, которую мы сможем скопировать и использовать для конкретизации наших последующих запросов.
Пользователь:
Выведи в одну строку название столбцов и тип каждого столбца
Внимание:
Мы не указали, какой именно датасет мы должны использовать в данном запросе, потому что мы формируем запрос в текущем чате обсуждения, и ChatGPT будет анализировать предыдущие шаги, чтобы понять, какой датасет мы используем. Однако, если в текущем чате было выполнено много шагов или если есть несколько альтернативных датасетов, то необходимо конкретизировать запрос, указав, какой датасет нужно использовать.
Чат:
Для вывода названия столбцов и типа каждого столбца, используйте следующий код:
Результат:
Выполняем все рекомендации Чата и посмотрим смотрим что из этого получилось.
Внимание:
Как вы заметили, мы пропустили строки кода с импортом библиотеки pandas и загрузкой данных из CSV файла. Мы воспользовались ранее предложенным советом и пропустили эти строки кода, чтобы избежать повторения одних и тех же команд.
Шаг3 Визуализация и статистический данных
Для построения различных графиков, которые могут помочь визуализировать и провести статистический анализ данных, мы просим Чат предоставить нам соответствующий код.
Такой код позволит нам быстро и удобно построить необходимые графики и провести необходимый анализ данных.
Благодаря этому мы сможем получить более глубокое понимание нашего датасета и извлечь более полезные выводы из данных.
Пользователь:
Библиотека pandas уже установлена и наш файл titanic.csv уже загружен в переменную data.
Файл titanic.csv содержит следующие столбцы:
Survived: int64, Pclass: int64, Name: object, Sex: object, Age: float64, Siblings/Spouses Aboard: int64, Parents/Children Aboard: int64, Fare: float64
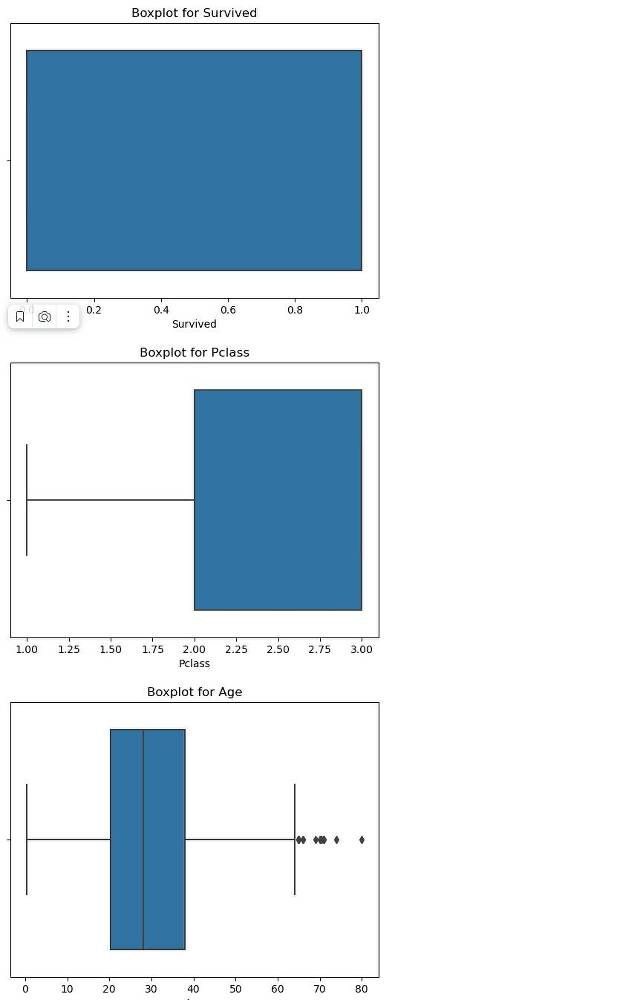
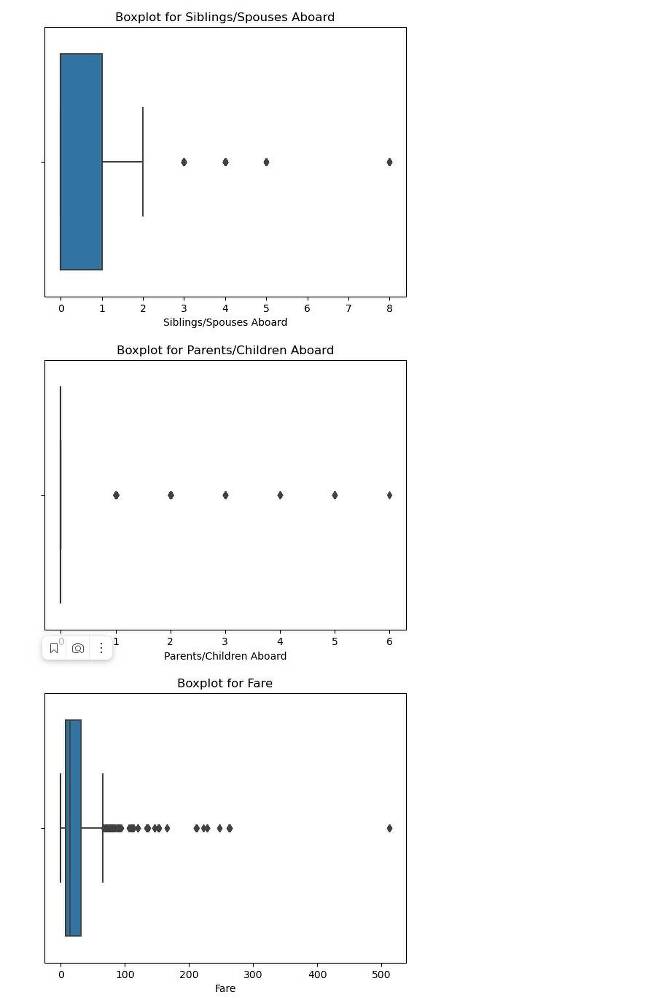
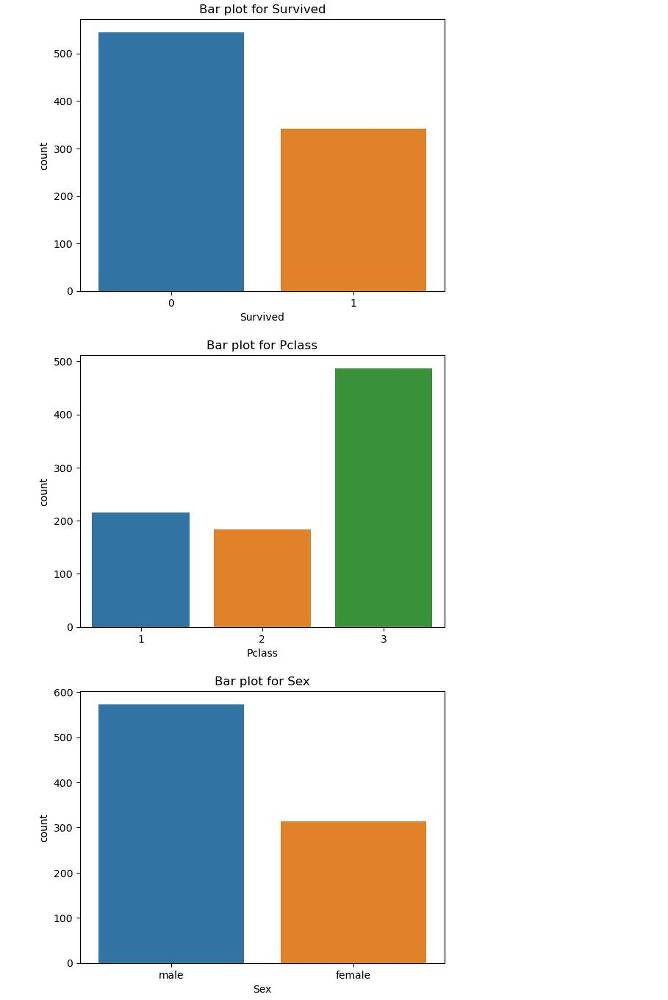
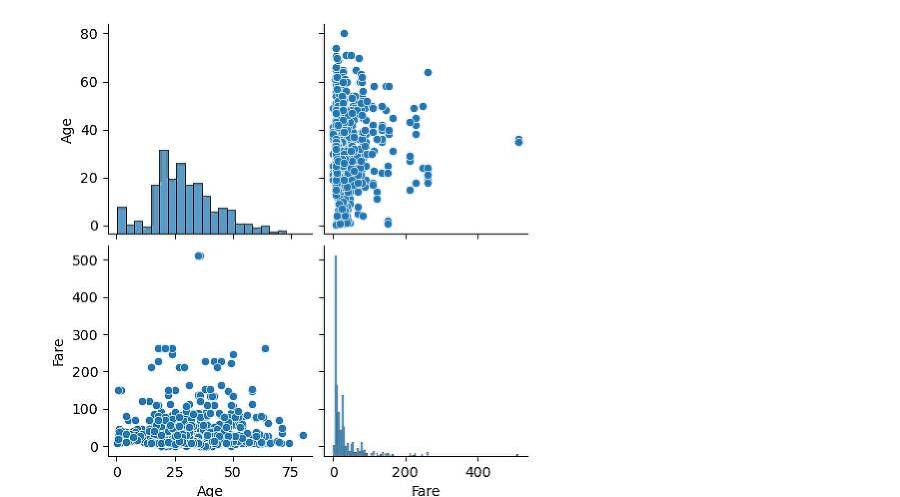
Выполни визуализацию данных построив гистограмму, box plot, bar plot, scatter plot и корреляционную матрицу.
Чат:
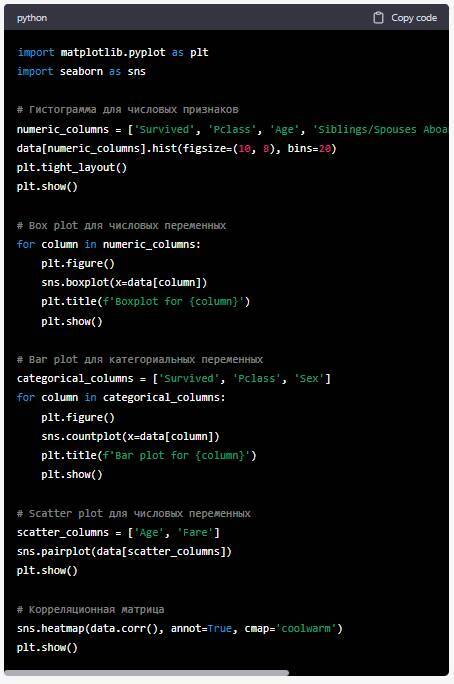
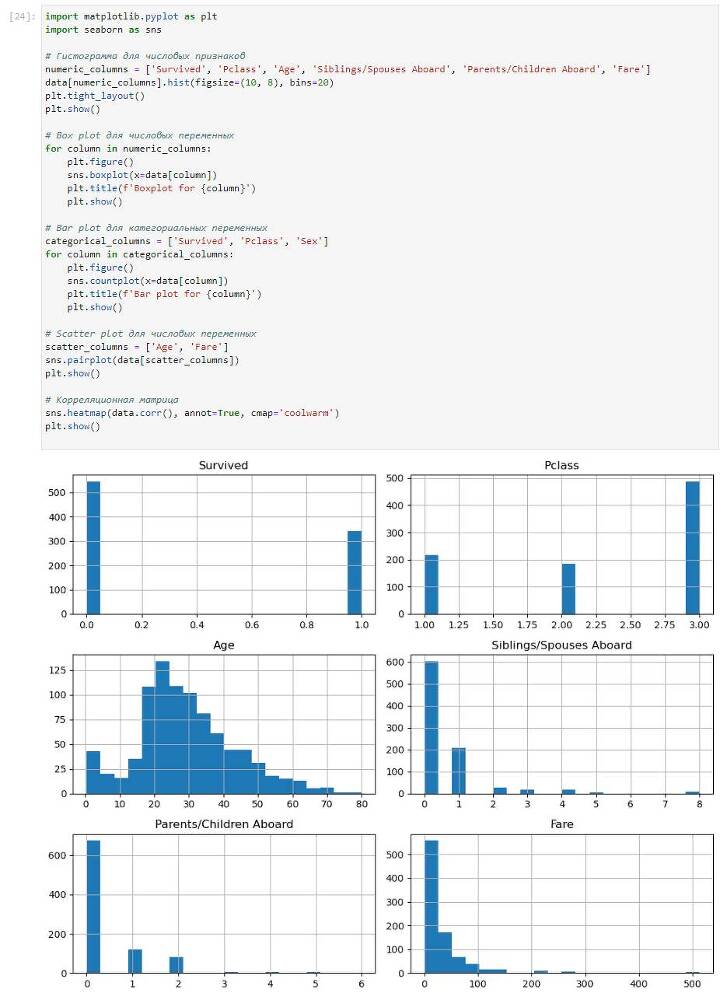
Если данные уже загружены в переменную data, вы можете использовать следующий код для визуализации данных с помощью гистограмм, box plot, bar plot, scatter plot и корреляционной матрицы:
Этот код создаст графики визуализации, включая гистограммы, box plot, bar plot, scatter plot и корреляционную матрицу для различных столбцов данных. Гистограммы и box plot используются для числовых переменных, в то время как bar plot используется для категориальных переменных. Scatter plot и корреляционная матрица позволяют наблюдать взаимосвязь между числовыми переменными.
Выполнение кода создаст графики, которые помогут вам лучше понять распределение данных, взаимосвязь между переменными и выявить возможные выбросы или аномалии в данных.
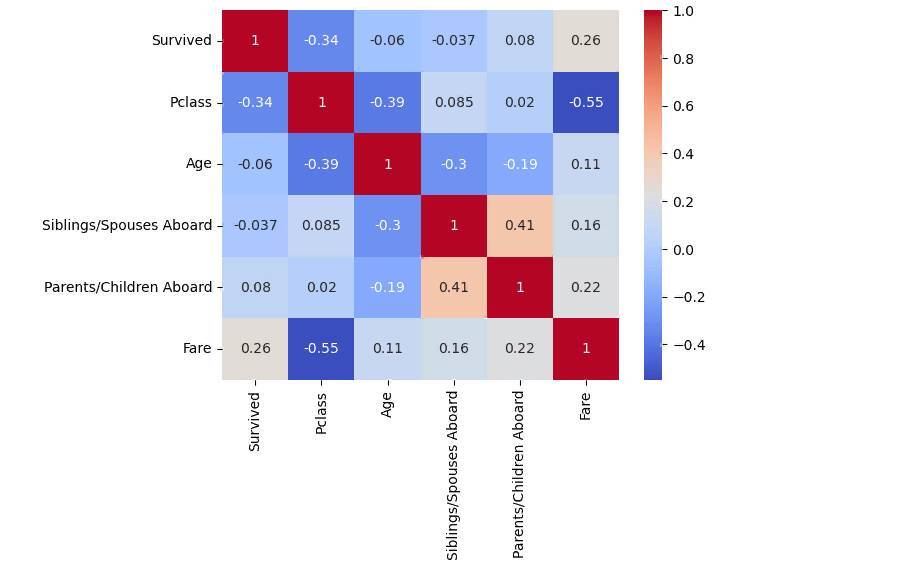
Результат:
Выполняем все рекомендации Чата и посмотрим смотрим что из этого получилось.
Пользователь:
Ты можешь анализировать графики?
как их загрузить тебе для анализа?
Чат:
К сожалению, как AI, я не могу напрямую анализировать изображения или графики, загруженные пользователем. Однако, если у вас есть вопросы о том, как интерпретировать графики или какие выводы можно сделать на основе графиков, я могу помочь вам с объяснениями и рекомендациями.
Вы можете задать вопросы, касающиеся графиков, и я постараюсь дать вам подробные ответы и объяснения.
Примеры вопросов могут быть следующими:
Как интерпретировать корреляционную матрицу?
Что такое выбросы на box plot, и что они могут означать для данных?
Какие выводы можно сделать из гистограммы или bar plot?
Пожалуйста, задайте свои вопросы, и я с радостью помогу вам разобраться в анализе графиков.
Пользователь:
Как интерпретировать корреляционную матрицу?
Что такое выбросы на box plot, и что они могут означать для данных?
Какие выводы можно сделать из гистограммы или bar plot?
Чат:
Корреляционная матрица – это таблица, которая показывает корреляционные коэффициенты между парами переменных. Корреляционные коэффициенты – это числовые значения, которые измеряют степень связи между двумя переменными.
Коэффициент корреляции может принимать значения от -1 до 1. Коэффициенты, близкие к 1, означают положительную корреляцию, т.е. если значение одной переменной увеличивается, то увеличивается и значение другой переменной. Коэффициенты, близкие к -1, означают отрицательную корреляцию, т.е. если значение одной переменной увеличивается, то значение другой переменной уменьшается. Коэффициенты, близкие к 0, означают отсутствие корреляции между переменными.