Как выбрать подходящую метрику качества модели?
Выбор подходящей метрики качества модели зависит от типа задачи, для которой модель была обучена. Например, метрики качества модели для задачи классификации будут отличаться от метрик качества модели для задачи регрессии. Также необходимо учитывать особенности данных, на которых модель будет применяться, и целей проекта.
Для выбора подходящей метрики качества модели необходимо задаться несколькими вопросами:
Какую задачу решает модель? (классификация, регрессия, кластеризация, обнаружение аномалий и т.д.)
Какие особенности данных нужно учитывать? (размер датасета, баланс классов, наличие выбросов и т.д.)
Какие цели нужно достигнуть? (максимизация точности, минимизация ошибок, оптимизация скорости и т.д.)
Выбор подходящей метрики качества модели может быть сложной задачей, поэтому необходимо тщательно изучать свойства и особенности каждой метрики и выбирать ту, которая наилучшим образом соответствует задаче и целям проекта.
Например, для задачи классификации можно использовать метрики качества, такие как точность (accuracy), точность (precision), полнота (recall), F-мера (F1-score) и ROC AUC. Точность (accuracy) определяет долю правильных ответов, которые модель дает для всех классов. Точность (precision) определяет долю истинно положительных ответов относительно всех положительных ответов, а полнота (recall) определяет долю истинно положительных ответов относительно всех положительных результатов. F-мера (F1-score) является гармоническим средним между точностью и полнотой, а ROC AUC измеряет способность модели различать между классами.
Для задач регрессии могут использоваться метрики качества, такие как среднеквадратическая ошибка (MSE), корень среднеквадратической ошибки (RMSE), средняя абсолютная ошибка (MAE), коэффициент детерминации (R-squared) и другие.
Для задач кластеризации могут использоваться метрики качества, такие как коэффициент силуэта (silhouette coefficient), индекс Калински-Харабаса (Calinski-Harabasz index), индекс Дэвиса-Болдина (Davies-Bouldin index) и другие.
Для задач обнаружения аномалий можно использовать метрики, такие как показатель точности (precision), показатель полноты (recall), F-меру (F1-score), площадь под кривой операционной характеристики получателя (AUROC) и другие.
Для задач обнаружения объектов метрики качества могут включать среднюю точность (mAP), коэффициент пересечения (IoU), точность (precision), полноту (recall) и другие.
В данной книге мы рассмотрим более подробно каждую метрику и ее применение в различных задачах машинного обучения. Мы также рассмотрим способы интерпретации метрик и примеры их использования на практике. Мы надеемся, что это поможет вам лучше понимать, как выбрать подходящую метрику качества модели и как правильно интерпретировать ее результаты.
Метрики качества модели для задач классификации
Метрики качества модели для задач классификации, такие как Accuracy, Precision, Recall, F1-score, ROC AUC, Log Loss и Confusion Matrix (Матрица ошибок), применяются в различных жизненных ситуациях, где необходимо оценить производительность алгоритмов классификации. Вот несколько примеров:
Медицинская диагностика: В медицине алгоритмы классификации могут использоваться для диагностики заболеваний, определения стадий рака, предсказания риска развития определенных заболеваний или идентификации патогенов. Метрики, такие как Accuracy, Precision, Recall, F1-score, ROC AUC и Confusion Matrix, могут быть использованы для оценки эффективности этих алгоритмов и улучшения точности диагностики.
Фильтрация спама: В системах фильтрации спама алгоритмы классификации используются для определения спам-писем и разделения их от легитимных сообщений. Метрики, такие как Accuracy, Precision, Recall, F1-score, ROC AUC и Log Loss, могут быть использованы для оценки производительности этих систем и определения того, насколько хорошо они фильтруют спам.
Определение мошенничества: В банковской и финансовой сфере алгоритмы классификации используются для обнаружения подозрительных транзакций, мошенничества с кредитными картами или неправомерного использования. Метрики, такие как Accuracy, Precision, Recall, F1-score, ROC AUC и Confusion Matrix, могут быть использованы для оценки производительности этих систем и определения областей для дальнейшего улучшения.
Рекомендательные системы: В рекомендательных системах, таких как интернет-магазины, потоковые сервисы и социальные сети, алгоритмы классификации используются для предоставления персонализированных предложений пользователям. Метрики, такие как Accuracy, Precision, Recall, F1-score и ROC AUC, могут помочь оценить эффективность рекомендаций и улучшить качество предложений.
Текстовый анализ и анализ тональности: В области анализа текста алгоритмы классификации используются для определения темы, жанра или эмоциональной окрас ки текста. Метрики, такие как Accuracy, Precision, Recall, F1-score, ROC AUC и Confusion Matrix, могут быть использованы для оценки эффективности этих алгоритмов и улучшения качества анализа.
Распознавание изображений: В задачах распознавания изображений, таких как определение объектов на фотографиях, классификация видов животных или распознавание лиц, алгоритмы классификации играют ключевую роль. Метрики, такие как Accuracy, Precision, Recall, F1-score, ROC AUC и Confusion Matrix, могут быть использованы для оценки производительности этих систем и определения областей для дальнейшего улучшения.
Классификация новостей: В задачах классификации новостей алгоритмы классификации используются для определения темы статьи, источника информации или оценки достоверности новости. Метрики, такие как Accuracy, Precision, Recall, F1-score, ROC AUC и Confusion Matrix, могут быть использованы для оценки эффективности этих алгоритмов и улучшения качества анализа.
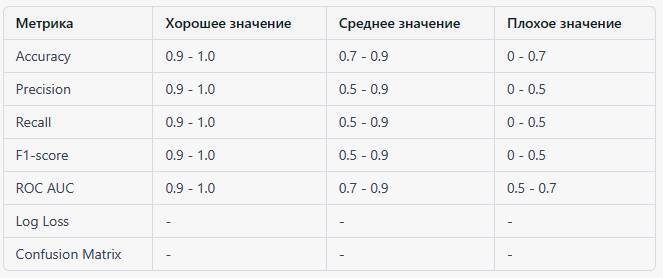
Для некоторых метрик качества модели для задач классификации возможно определить хорошие, средние и плохие значения. Однако для других, таких как Log Loss и Confusion Matrix, такие диапазоны не могут быть определены без контекста и масштаба данных. Тем не менее, я представлю таблицу значений для некоторых из метрик:
Для Log Loss и Confusion Matrix не существует фиксированных границ для хороших, средних и плохих значений, потому что они зависят от контекста и масштаба данных. Оценка Log Loss должна проводиться в сравнении с другими моделями на том же наборе данных, а Confusion Matrix должна быть анализирована для определения различных видов ошибок, которые допускает модель.
Важно учитывать, что эти диапазоны являются общими ориентирами и могут варьироваться в зависимости от конкретной области применения и задачи. Например, в критически важных областях, таких как медицинская диагностика, требуется более высокая точность и полнота, чем в менее критических сценариях, таких как рекомендации контента.
Метрика Accuracy (Точность)
Метрика Accuracy (Точность) является одной из наиболее базовых и понятных метрик для оценки качества работы алгоритма классификации. Она измеряет долю правильно классифицированных объектов относительно общего числа объектов в наборе данных.
Метрика Accuracy рассчитывается следующим образом:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
где:
TP (True Positives) – количество правильно классифицированных положительных объектов;
TN (True Negatives) – количество правильно классифицированных отрицательных объектов;
FP (False Positives) – количество неправильно классифицированных положительных объектов (ложные срабатывания);
FN (False Negatives) – количество неправильно классифицированных отрицательных объектов (пропущенные срабатывания).