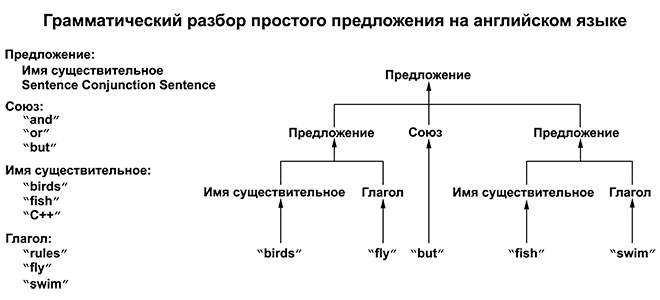
Предложение состоит из частей речи (например, имен существительных, глаголов и союзов). В соответствии с этими правилами предложение можно разложить на слова — имена существительные, глаголы и т.д. Эта простая грамматика также включает в себя семантически бессмысленные предложения, такие как “C++ fly and birds rules,” но решение этой проблемы выходит далеко за рамки рассмотрения нашей книги.
Многие читатели наверняка уже изучали такие правила в средней школе при изучении иностранных языков. Эти правила носят фундаментальный характер. В их основе лежат серьезные неврологические аргументы, утверждающие, что эти правила каким-то образом “встроены” в наш мозг!
Рассмотрим дерево грамматического разбора простого предложения на английском языке.
Сложности еще не закончились. Если вы не уверены, что все правильно поняли, то вернитесь и перечитайте раздел 6.4 с самого начала. Возможно, при втором чтении вы поймете, о чем идет речь!
6.4.2. Запись грамматики
Как выбираются грамматические правила для разбора указанных выше выражений? Самым честным ответом является “опыт”. Способ, который мы применили, просто повторяет способ, с помощью которого люди обычно записывают грамматики. Однако запись грамматики совершенно очевидна: нам необходимо лишь сделать следующее.
1. Отличать правило от лексемы.
2. Записывать правила одно за другим (последовательно).
3. Выражать альтернативные варианты (разветвление).
4. Выражать повторяющиеся варианты (повторение).
5. Распознавать начальное правило.
В разных учебниках и системах грамматического разбора используются разные соглашения и терминология. Например, иногда лексемы называют терминалами (terminals), а правила — нетерминалами (non-terminals), или продукциями (productions). Мы просто заключаем лексемы в двойные кавычки и начинаем с первого правила. Альтернативы выражаются с помощью линий. Рассмотрим пример.
Список:
"{"Последовательность"}"
Последовательность:
Элемент
Элемент "," Последовательность
Элемент:
"A"
"B"
Итак, Последовательность — это Элемент или Элемент, за которым следует разделяющая запятая и другая Последовательность. Элемент — это либо буква A, либо B. Список — это Последовательность в фигурных скобках. Можно сгенерировать следующие Списки (как?):
{A}
{B}
{A,B}
{A,A,A,A,B}
Однако то, что перечислено ниже, списком не является (почему?):
{}
A
{A,A,A,A,B
{A,A,C,A,B}
{A B C}
{A,A,A,A,B,}
Этим правилам вас в детском садике не учили, и в вашем мозге они не “встроены”, но понять их не сложно. Примеры их использования для выражения синтаксических идей можно найти в разделах 7.4 и 7.8.1.
6.5. Превращение грамматики в программу
Существует много способов заставить компьютер следовать грамматическим правилам. Мы используем простейший из них: напишем функцию для каждого грамматического правила, а для представления лексем применим класс
Token
. Программу, реализующую грамматику, часто называют программой
грамматического разбора (parser).
6.5.1. Реализация грамматических правил
Для реализации калькулятора нам нужны четыре функции: одна — для считывания лексем и по одной для каждого грамматического правила.
get_token() // считывает символы и составляет лексемы
// использует поток cin
expression() // реализует операции + и –
// вызывает функции term() и get_token()
term() // реализует операции *, / и %
// вызывает функции primary() и get_token()
primary() // реализует числа и скобки
// вызывает функции expression() и get_token()
Примечание: каждая функция обрабатывает отдельные части выражения, оставляя все остальное другим функциям; это позволяет радикально упростить каждую функцию. Такая ситуация напоминает группу людей, пытающихся решить задачу, разделив ее на части и поручив решение отдельных подзадач каждому из членов группы.
Что же эти функции должны делать в действительности? Каждая из них должна вызывать другие грамматические функции в соответствии с грамматическим правилом, которое она реализует, а также функцию
get_token()
, если в правиле упоминается лексема. Например, когда функция
primary()
пытается следовать правилу (
Выражение), она должна вызвать следующие функции:
get_token() // чтобы обработать скобки ( и )
expression() // чтобы обработать Выражение
Что должен возвращать такой грамматический анализатор? Может быть, реальный результат вычислений? Например, для выражения
2+3
функция
expression()
должна была бы возвращать
5
. Теперь понятно! Именно это мы и должны сделать! Поступая таким образом, мы избегаем ответа на один из труднейших вопросов: “Как представить выражение
45+5/7
в виде данных, чтобы его можно было вычислить?” Вместо того чтобы хранить представление этого выражения в памяти, мы просто вычисляем его по мере считывания входных данных. Эта простая идея коренным образом изменяет ситуацию! Она позволяет в четыре раза уменьшить размер программы по сравнению с вариантом, в котором функция
expression()
возвращает что-то сложное для последующего вычисления. Таким образом, мы сэкономим около 80% объема работы.
Функция
get_token()
стоит особняком: поскольку она обрабатывает лексемы, а не выражения, она не может возвращать значения подвыражений. Например,
+
и
(
— это не выражения. Таким образом, функция
get_token()
должна возвращать объект класса
Token
.