Контрфактивные суждения – это строительные кирпичи этичного поведения и научной мысли. Способность размышлять о своих действиях в прошлом и предвидеть альтернативные сценария – это основа свободной воли и социальной ответственности. Алгоритмизация контрфактивных суждений открывает думающим машинам эту возможность, и теперь они могут разделить этот (доселе) исключительно человеческий способ осмыслять мир.
Я сознательно упомянул думающие машины в предыдущем абзаце. Я пришел к этой теме, когда занимался компьютерными науками, конкретно искусственным интеллектом, что обобщает две точки отправления для большинства из моих коллег, занятых причинным анализом. Во-первых, в мире искусственного интеллекта вы по-настоящему не понимаете тему до тех пор, пока не обучите ей робота. Вот почему вы увидите, что я неустанно, раз за разом подчеркиваю важность системы обозначений, языка, словаря и грамматики. Например, меня завораживает вопрос, в состоянии ли мы выразить определенное утверждение на том или ином языке и следует ли это утверждение из других. Поразительно, сколько можно узнать, просто следуя грамматике научных высказываний! Мой акцент на язык также объясняется глубоким убеждением в том, что последний оформляет наши мысли. Нельзя ответить на вопрос, который вы не способны задать, и невозможно задать вопрос, для которого у вас нет слов. Изучая философию и компьютерные науки, я заинтересовался причинным анализом во многом потому, что мог с волнением наблюдать, как зреет и крепнет забытый когда-то язык науки.
Мой опыт в области машинного обучения тоже мотивировал меня изучать причинность. В конце 1980-х годов я осознал, что неспособность машин понять причинные отношения, вероятно, самое большое препятствие к тому, чтобы наделить их интеллектом человеческого уровня. В последней главе этой книге я вернусь к своим корням, и вместе мы исследуем, что значит Революция Причинности для искусственного интеллекта. Я полагаю, что сильный искусственный интеллект – достижимая цель, которой, к тому же не стоит бояться именно потому, что причинность – часть решения. Модуль причинного осмысления даст машинам способность размышлять над своими ошибками, выделять слабые места в своем программном обеспечении, функционировать как моральные сущности и естественно общаться с людьми о собственном выборе и намерениях.
Схема реальности
В нашу эпоху всем читателям, конечно, уже знакомы такие термины, как «знания», «информация», «интеллект» и «данные», хотя разница между ними или принцип их взаимодействия могут оставаться неясными. А теперь я предлагаю добавить в этот набор еще один термин – «причинная модель», после чего у читателей, вероятно, возникнет закономерный вопрос: не усложнит ли это ситуацию?
Не усложнит! Более того, этот термин свяжет ускользающие понятия «наука», «знания» и «данные» в конкретном и осмысленном контексте и позволит нам увидеть, как они работают вместе, чтобы дать ответы на сложные научные вопросы. На рис. 1. показана схема механизма причинного анализа, которая, возможно, адаптирует причинные умозаключения для будущего искусственного интеллекта. Важно понимать, что это не только проект для будущего, но и схема того, как причинные модели работают в науке уже сегодня и как они взаимодействуют с данными.
Механизм причинного анализа – это машина, в которую поступают три вида входных переменных – допущения, запросы и данные – и которая производит три типа выходных данных. Первая из входных переменных – решение «да/нет» о том, можно ли теоретически ответить на запрос в существующей причинной модели, если данные будут безошибочными и неограниченными. Если ответ «да», то механизм причинного анализа произведет оцениваемую величину. Это математическая формула, которая считается рецептом для получения ответа из любых гипотетических данных, если они доступны. Наконец, после того как в механизм причинного анализа попадут данные, он использует этот рецепт, чтобы произвести действительную оценку. Подобная неопределенность отражает ограниченный объем данных, вероятные ошибки в измерениях или отсутствие информации.
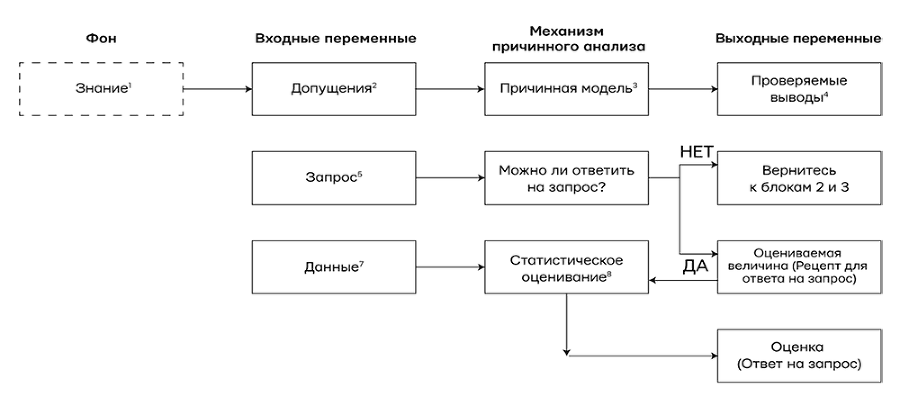
Рис. 1. Как механизм причинного анализа связывает данные со знанием причин, чтобы дать ответы на интересующие нас запросы. Блок, обозначенный пунктиром, не входит в механизм, но необходим для его построения. Также можно нарисовать стрелки от блоков 4 и 9 к блоку 1, но я решил сделать схему проще.
Чтобы объяснить схему подробнее, я пометил блоки цифрами от 1 до 9, и теперь прокомментирую их на примере запроса «Какой эффект лекарство D оказывает на продолжительность жизни L?»
1. «Знание» обозначает следы опыта, которые делающий умозаключения получил в прошлом. Это могут быть наблюдения из прошлого, действия в прошлом, а также образование и культурные традиции, признанные существенными для интересующего нас запроса. Пунктир вокруг «Знания» обозначает, что оно имеется в виду делающим умозаключения и не находит выражения в самой модели.
2. Научное исследование всегда требует упрощать допущения, т. е. утверждения, которые исследователь признает достойными, чтобы сформулировать их на основе доступного знания. Большая его часть остается подразумеваемой исследователем, и в модели запечатлены только допущения, которые получили формулировку и таким образом обнаружили себя. В принципе, их реально вычленить из самой модели, поэтому некоторые логики решили, что такая модель представляет собой всего лишь список допущений. Специалисты по компьютерным наукам делают здесь исключение, отмечая, что способ, избранный для представления допущений, в состоянии сильно повлиять на возможность правильно их сформулировать, сделать из них выводы и даже продолжить или изменить их в свете новой убедительной информации.
3. Причинные модели записываются в разной форме. Это могут быть диаграммы причинности, структурные уравнения, логические утверждения и т. д. Я убежденный приверженец диаграмм причинности почти во всех случаях – прежде всего из-за их прозрачности, но также из-за конкретных ответов, которые они дают на многие вопросы, которые нам хотелось бы задать. Для этой диаграммы определение причинности будет простым, хотя и несколько метафорическим: переменная X – причина Y, если Y «слушает» X и приобретает значение, реагируя на то, что слышит. Например, если мы подозреваем, что продолжительность жизни пациента L «прислушивается» к тому, какое лекарство D было принято, то мы называем D причиной L и рисуем стрелку от D к L в диаграмме причинности. Естественно, ответ на наш вопрос о D и L, вероятно, зависит и от других переменных, которые тоже должны быть представлены на диаграмме вместе с их причинами и следствиями (здесь мы обозначим их совокупно как Z).
4. Эта практика слушания, предписанная путями в причинной модели, обычно приводит к наблюдаемым закономерностям или зависимостям в данных. Подобные закономерности называются проверяемыми выводами, потому что они могут быть использованы для проверки модели. Это утверждение вроде «Нет путей, соединяющих D и L», которое переводится в статистическое утверждение «D и L независимы», т. е. обнаружение D не влияет на вероятность L. Если данные противоречат этому выводу, то модель нужно пересмотреть. Чтобы это сделать, требуется еще один механизм, которые получает входные переменные из блоков 4 и 7 и вычисляет «степень пригодности», или степень, до которой данные совместимы с допущениями модели. Чтобы упростить диаграмму, я не стал показывать второй механизм на рис. 1.
5. Запросы, поступающие в механизм причинного анализа, – это научные вопросы, на которые мы хотим ответить. Их необходимо сформулировать, используя термины причинности. Скажем, что такое P (L | do (D))? Одно из главных достижений Революции Причинности состоит в том, что она сделала этот язык научно прозрачным и математически точным.