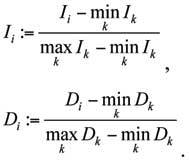Пусть p ≥ s, тогда примем следующее определение.
Определение 3. Будем говорить, что распределение количества товара по группам качества сегментировано, если для соответствующего ему вектора (M1, M2, …, Mp) и вектора распределения совокупного размера сбережений потребителей (N1, N2, …, Ns) выполнено условие:
M1 = N1, M2 = N2, …, Ms = Ns.
Теорема. При фиксированном распределении совокупного размера сбережений потребителей N(t) значение GDP(t) в (5) достигает максимума тогда и только тогда, когда распределение количества товара по группам качества M(t) сегментировано.
Схема доказательства
Для удобства доказательства далее будем представлять сумму (5) как сумму ненулевых слагаемых, упорядоченных по убыванию, где каждое слагаемое соответствует цене IC, которую заплатил отдельный потребитель. Число слагаемых очевидно равно числу потребителей и фиксированно.
Необходимость. Предположим, что M(t) не сегментировано и GDP(t) достигает своего максимального значения. Тогда существует i, 1 ≤ i ≤ s такой, что M1 = N1, …, Mi ≠ Ni. Рассмотрим два случая:
Mi < Ni
В данном случае число слагаемых в (5) со значением ICi меньше, чем для случая сегментированного M(t) (если бы Mi = Ni). В то же время число слагаемых со значениями IC > ICi такое же, а слагаемых со значениями IC < ICi больше – при одном и том же общем числе слагаемых. Следовательно, значение (5) в указанном случае меньше, чем в случае сегментированного M(t).
Mi > Ni
В данном случае слагаемые в (5) со значением ICi не встретятся, вместо этого будет большее число слагаемых с IC < ICi. При фиксированном числе слагаемых значение (5) меньше, чем в случае сегментированного M(t).
Достаточность. Пусть M(t) сегментировано. В соответствии с алгоритмом покупки товара и в силу сегментированности M(t), в сумме (5) будет N1 слагаемых с максимальным возможным значением IC1 (число таких слагаемых уже нельзя увеличить, а можно только уменьшить, уменьшив общую сумму), N2 слагаемых со значением IC2 (их число также нельзя увеличить) и т. д. до Ns слагаемых с значением ICs. Таким образом, получается, что сумма (5) принимает максимально возможное для себя значение.
Результаты работы имитационной модели
Сравнение результатов модели и предметных данных
Для соотнесения результатов имитационной модели и данных по странам проведем нормировку показателей средней компетентности Ii в стране i и ВВП на душу населения Di для результатов, полученных с помощью имитационной модели и данных из работы (Lynn, Vanhanen, 2002):
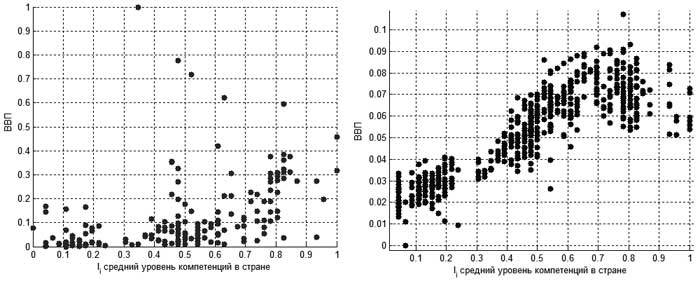
На рисунке 2 проиллюстрированы два набора данных после нормировки:
• данные по реальным странам (слева), полученные из (Lynn, Vanhanen, 2002);
• данные имитационной модели (справа), полученные в момент модельного времени t = 25, когда характер зависимости, изображенной на рисунке 2, не меняется в течение более 10 тактов. Ниже, при расчетах параметров модели, рассматриваются данные на этом такте времени.
Визуально на рисунке 2 мы можем отметить наличие роста мат. ожидания и дисперсии Di при росте значения Ii. Оценим статистически степень влияния фактора Ii на Di отдельно по данным для стран из (Lynn, Vanhanen, 2002) и отдельно по данным, полученным в имитационной модели.
Рис. 2. Иллюстрация данных Ii и Di, полученных из (Lynn, Vanhanen, 2002) (слева) и имитационной модели (справа)
Для оценки степени влияния Ii на Di посредством однофакторного дисперсионного анализа проверим наличие статистической зависимости показателя Di от уровней фактора Ii (групп различных значений) (Кобзарь, 2006). Разобьем значения Ii на три равные непересекающиеся группы (три уровня фактора Ii: «низкий», «средний» и «высокий»), сформируем три выборки значений Di для соответствующего уровня фактора Ii. Рассчитаем уровень значимости p гипотезы Н0:
«Все три выборки принадлежат одной генеральной совокупности или разным генеральным совокупностям с равными средними арифметическими» (если гипотеза H0 неверна, то параметр Ii оказывает существенное влияние на Di).
Уровень значимости p есть вероятность необоснованно (ошибочно) отвергнуть (считать неверной) гипотезу H0. Проведем расчеты отдельно для данных из работы Линна и для данных, полученных из имитационной модели.
Анализ данных из работы Линна показывает, что вероятность необоснованного отклонения нулевой гипотезы крайне мала: ≈9,44 .10–9 (см. таблицу 1). Следовательно с большой степенью уверенности (1 – p ≈ 1) можно утверждать, что значения параметра Di зависят от значений параметра Ii на основе данных, собранных в (Lynn, Vanhanen, 2002).
Таблица 1[5]

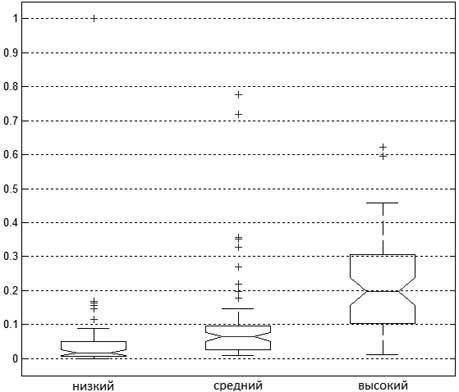
Оценим характер влияния Ii на Di. На рисунке 3 проиллюстрируем результат обработки данных из (Lynn, Vanhanen, 2002) в виде графика box plot («ящик с усами»). На этом рисунке вдоль оси Ох размещены три уровня фактора Ii: «низкий», «средний» и «высокий» в соответствующем порядке. Для каждого из трех уровней фактора Ii нарисован «ящик с усами» (фигура синего цвета – «ящик», пунктирные вертикальные прямые – «усы»). Горизонтальная линия («талия» у ящика) обозначает медиану выборки значений параметра Di, соответствующих уровню фактора Ii («низкий», «средний» и «высокий»). Как видно из рисунка 3, уровням фактора Ii соответствуют следующие значения медианы Di: «низкий» – 0,017, «средний» – 0,065, «высокий» – 0,2. Нижняя и верхняя границы каждого из ящиков иллюстрируют первую и третью квантили q1 и q3 для выборки Di соответственно[6]. Длина усов каждого из ящиков определяются значениями: нижняя – 9-й процентили, верхняя – 91-й процентили. Данные, выходящие за пределы усов (выбросы), отображаются на графике в виде крестиков.