Сохраним числовые данные из исходной таблицы во вспомогательной переменной:
to.remove <– c('Фимилия Имя', 'Класс', '№№')
X <– My_table[, !colnames(My_table) %in% to.remove]
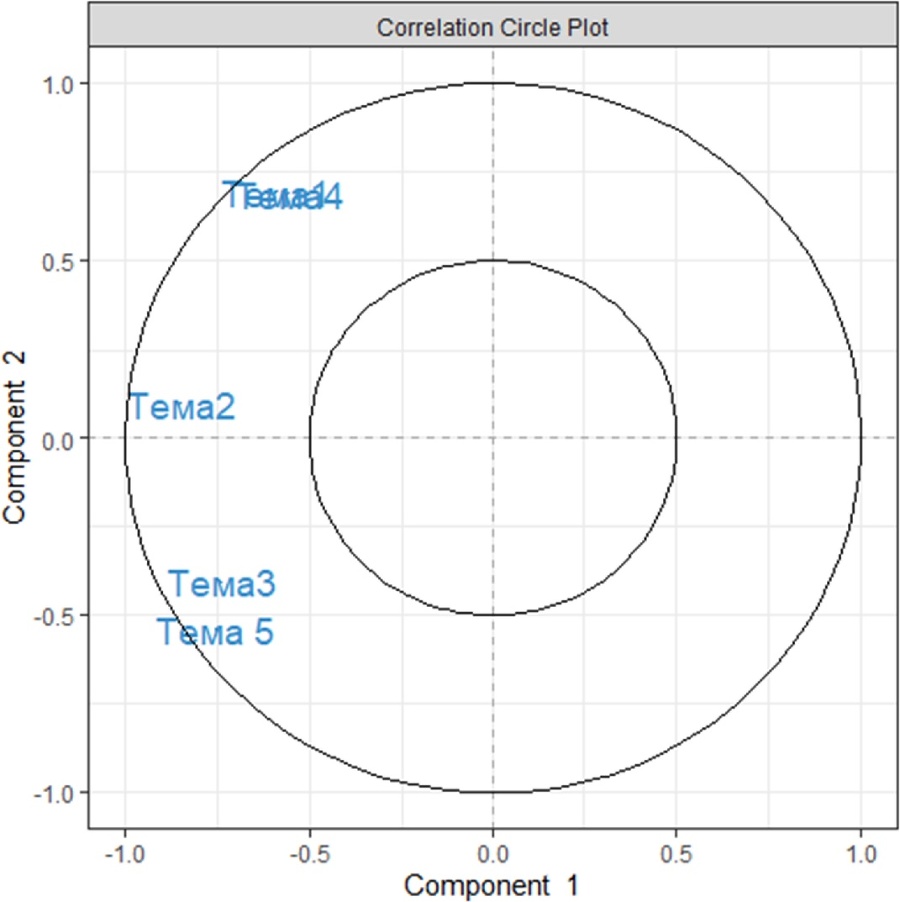
Следуя примеру выше, методы PCA могут быть применены для выбора первых пяти переменных, тесно связанных с первыми двумя компонентами в PCA. Пользователь определяет количество переменных, выбранных по каждому компоненту, например, здесь выберем пять переменных на каждом из первых двух компонентов командой keepX=c(5,5):
My_result.spca <– spca(X, keepX=c(5,5)) # 1 Запуск выбранного метода анализа
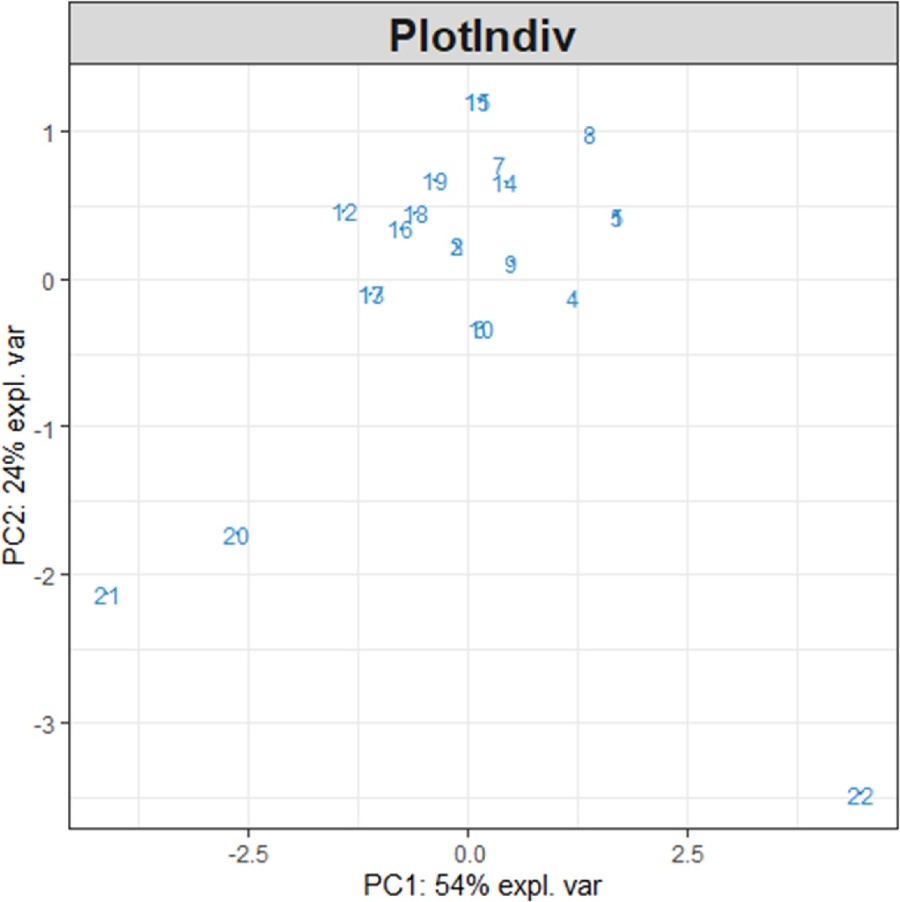
plotIndiv(My_result.spca) # 2 Визуальное представление образцов
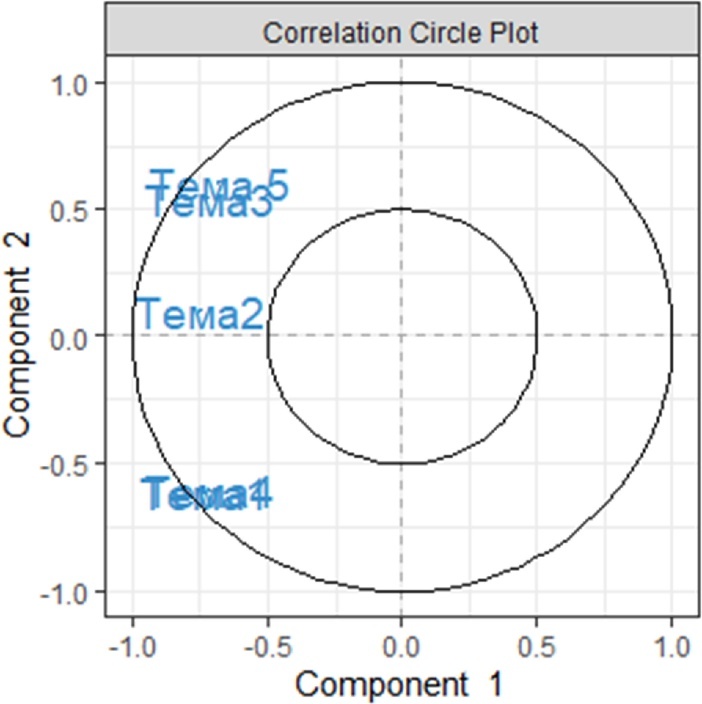
plotVar(My_result.spca) # 3 Визуальное представление переменных
Можно заметить, что сократилось количество элементов на круге корреляции. Не останавливайтесь на достигнутом, находясь в начале большого пути. Можно улучшить наглядность представляемых результатов анализа следующим образом: загляните в справочное руководство по каждой из функций используемой в примерах, введя в консоли ?pca, ?plotIndiv, ?sPCA. Для запуска сопутствующих примеров можно использовать функцию example: example(pca), example(plotIndiv), и другие.
Глава 2. Метод главных компонент (PCA)
Зададимся следующим вопросом: как определить основные источники различий в имеющихся данных, а после этого выяснить, соответствуют ли такие источники объективным условиям педагогического эксперимента или они образовались в результате предвзятости экспериментаторов? Попутно хотелось бы визуализировать основные тенденции и закономерности изменения значений между образцами, в частности, естественного характера, в соответствии с известными условиями педагогического наблюдения.
Так, например, исходные данные для анализа могут содержать таблицу с n рядами и p столбцами, соответствующими уровню успеваемости p студентов, измеренных на n курсах. Чтобы проиллюстрировать PCA, фокусируемся на уровнях успеваемости по темам, описанным в таблице данных My_table, сохранённой ранее.
Цель PCA заключается в том, чтобы уменьшить размерность данных, сохраняя при этом как можно больше информации, насколько это возможно. «Информация» здесь обусловлена дисперсией. Идея заключается в создании попарно несвязанных между собой вспомогательных переменных, называемых главными компонентами (PC), которые являются линейной комбинацией исходных (возможно, коррелирующих между собой) переменных (например, тематика контрольных работ и так далее).
Уменьшение размерности достигается за счет отображения исходных данных в пространство, порождаемое главными компонентами (PC). На практике это означает, что каждому образцу присваивается координата по каждому новому измерению PC – эта координата рассчитывается как линейная комбинация исходных переменных, с некоторыми весовыми коэффициентами. Вес каждой из исходных переменных хранится в так называемых векторах нагрузки, связанных с каждым образцом. Размер данных уменьшается за счет проецирования данных в подпространство меньшей размерности, порождаемое PC, при одновременном охвате крупнейших источников различий между образцами.
Главные компоненты получены таким образом, чтобы их дисперсия была максимальной. С этой целью вычисляются собственные векторы и собственные значения матрицы дисперсии-ковариации, часто с помощью алгоритмов линейного разложения значения, когда количество переменных достаточно велико. Данные, как правило, центруют (опцией center = TRUE), а иногда и масштабируют (scale = TRUE) при вызове метода. Масштабирование рекомендуется применять в том случае, если дисперсия неоднородна по переменным.
Первая главная компонента (PC1) определяется линейной комбинацией исходных переменных, что объясняет наибольшее количество вариаций. Вторая главная компонента (PC2) затем определяется как линейное сочетание исходных переменных, на которые приходится наибольшее количество оставшегося объема вариаций ортогонального (несвязанного) с первым компонентом. Последующие компоненты определяются также для других размерностей PCA. Таким образом, пользователь должен сообщить, сколько информации объясняется первыми ПК, поскольку они используются для графического представления выходов PCA.
Сначала загружаем данные. Чтобы загрузить свои собственные данные можно воспользоваться следующей командой:
My_result.pca <– pca(X) # 1 Запуск выбранного метода анализа
plotIndiv(My_result.pca) # 2 Визуальное представление образцов
plotVar(My_result.pca) # 3 Визуальное представление переменных
Если запустить PCA этим минимальным кодом, то будут использоваться следующие значения по умолчанию:
1. ncomp = 2: лишь первые две главные компоненты рассчитываются и используются при построении диаграмм;
2. center = TRUE: данные отцентрованы (среднее значение равно 0);
3. scale = FALSE: данные не масштабируются. Если установить scale = TRUE, то алгоритм стандартизирует каждую переменную (дисперсия станет равной 1).
Другие параметры также могут быть настроены дополнительно, с полным списком настроек можно ознакомиться вызвав ?pca.
В примере, показанном выше, две пары тем не являются значительно отличающимися визуально, поэтому конкретные образцы должны быть дополнительно исследованы, тогда участок корреляционного круга, содержащий много переменных, можно будет легко интерпретировать. Ниже будет показано, как улучшить полученные диаграммы, чтобы облегчить интерпретацию результатов.
Диаграммы можно настроить с помощью многочисленных опций в plotIndiv и plotVar. Даже если PCA не принимает во внимание какую-либо информацию об известном членстве в группе каждой выборки, можно включить такую информацию в выборку для визуализации любого «естественного» кластера данных, который может быть обусловлен педагогической спецификой и условиями отбора группы.
Так, например, следующая команда включает информацию о классе в группах выборки аргументом группирования:
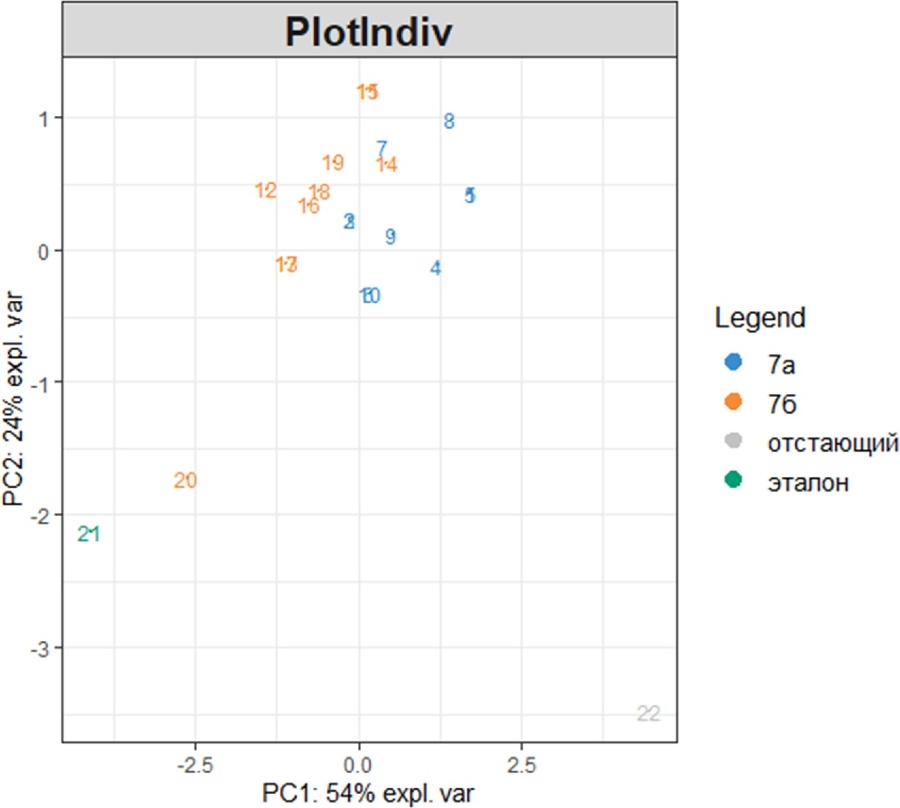
plotIndiv(My_result.pca, group = My_table$Класс,
legend = TRUE)
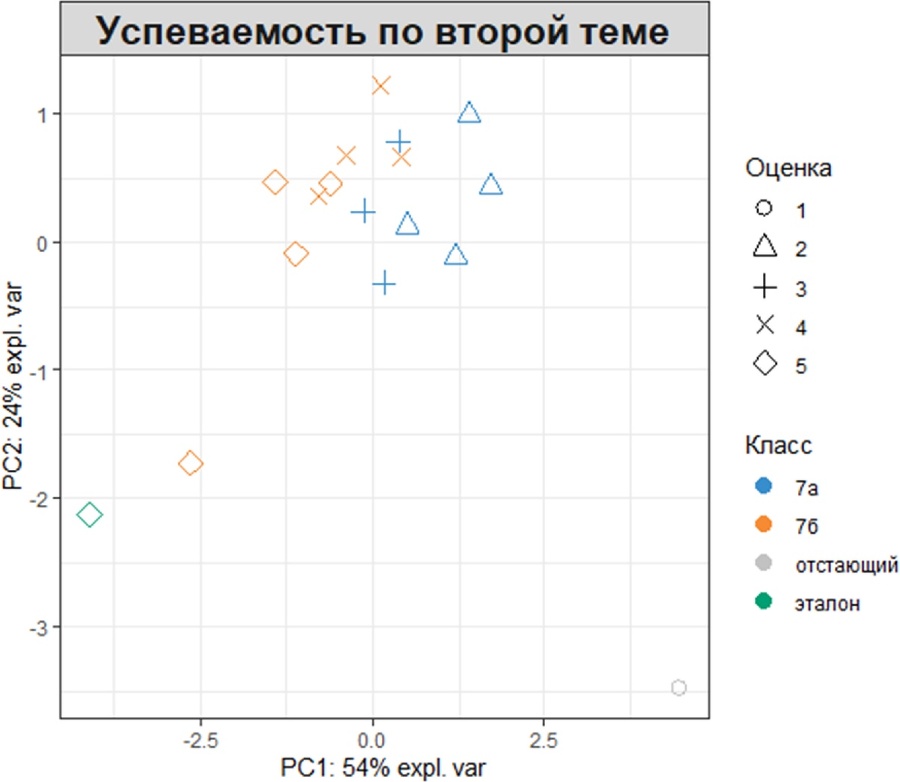
Кроме того, два фактора могут отображаться с использованием как цветов (аргумент group), так и символов (аргумент pch). Например, отобразим класс и оценки, полученные по второй теме, изменив при этом название и легенду диаграммы:
plotIndiv(My_result.pca, ind.names = FALSE,
group = My_table$'Класс',
pch = as.factor(My_table$'Тема2'),
legend = TRUE, title = 'Успеваемость по второй теме',
legend.title = 'Класс', legend.title.pch = 'Оценка')
Путем добавления информации, связанной с классом и оценкой появляется возможность увидеть кластер наблюдений успеваемости близких к эталонному образцу (зелёный ромб в левом нижнем углу), в то время как образцы с низкой успеваемостью (синие треугольники) оказались сгруппированы отдельно, но явно обнаруживается эффект разделения обучающихся на классы.
Чтобы отобразить результаты на других компонентах, можно изменить аргумент comp при условии, что было запрошено достаточно компонент для расчета. Приведём второй пример PCA с тремя компонентами, в котором третий компонент по оси PC3 четко разграничивает обучающихся по классам:
My_result.pca2 <– pca(X, ncomp = 3)