Денис Соломатин
mixOmics для гуманитариев
Введение
«Живые смыслы не оцифровать», тем не менее, реалии цифровой эпохи таковы, что всё настойчивее стремимся вникнуть в тайны мироздания пользуясь предоставляемым математикой инструментарием и описать увиденное на языке цифр. Само по себе это не хорошо и не плохо, не стоит лишь забывать и об эмоциональной, чувственной составляющей жизни человека. В связи со сказанным на передний план выходят различные «омики», изучающие то всеобъемлющее, что буквально создаёт нас, формируя основу нашей жизни. В частности, например: геном – как совокупность данных обо всех наших генах; транскриптом – постоянно меняющийся набор считываемых из генома данных; протеом – все производимые нашим организмом белки; эпигеном – условия, в которых живёт организм, формирующие своеобразный регуляторный уровень над генами; микробиом – бактерии, с которыми мы живём; метагеном – совокупный геном сообщества организмов, живущих вместе; коннектом – совокупность нервных связей живого организма; социом – как совокупность социальных связей индивида. Созданием в определённом смысле этого слова новых членов общества занимается и система образования, именно поэтому на наш взгляд оказывается уместным в ходе статистической обработки педагогической информации использование mixOmics – пакета прикладных программ, функций и процедур R, разрабатываемого и поддерживаемого отделением математики и статистики Мельбурнского университета (Австралия), а также Институтом математики Университета Тулузы (Франция), с передовыми достижениями которых можно ознакомиться на сайте http://mixomics.org
В фундаментальной работе Грабарь М. И., Краснянская К. А. (Применение математической статистики и педагогических исследованиях. Непараметрические методы. М., «Педагогика», 1977. 136 с. с ил. Науч.-исслед. ин-т содержания и методов обучения Акад. пед. наук СССР), на стр.4 констатировали печальный факт: «Любое изложение общей теории проверки статистических гипотез неизбежно должно предполагать у читатели очень серьезную математическую подготовку, каковой, к сожалению, не обладают большинство исследователей-педагогов». С наступлением цифровой эпохи и распространением доступных инструментальных средств статистической обработки информации отмеченный недостаток можно нивелировать и обратить в достоинство. Предполагается, что читатель уже знаком с изложенными в предыдущей части настоящего пособия азами работы R, – языка программирования для статистической обработки данных и работы с графикой, а также свободной программной среды вычислений с открытым исходным кодом в рамках проекта GNU. Поэтому во второй части сконцентрируемся на использовании ключевых функций пакета mixOmics для анализа педагогических данных. Если возникнут какие-либо проблемы с пониманием излагаемого материала, настоятельно рекомендуется вернуться и перечитать предыдущую часть пособия. Выбранный набор инструментов включает в себя многовариантные методы статистического анализа, предпочтение которым отдаётся в зависимости от обрабатываемых или собираемых педагогических данных, например, с целью апробации результатов, дискриминантного анализа, слияния двух или более наборов данных. mixOmics – это набор инструментов R, посвященный исследованию и слиянию различных наборов данных с определенным акцентом на выборе переменных. Пакет в настоящее время включает в себя порядка двадцати многовариантных методов. Первоначально все методы были разработаны для данных «омиков», однако их применение не ограничивается только такими данными. Другие приложения возникают как правило в тех случаях, когда переменные-предикторы (то есть переменные, по значениям которых составляются прогнозы) непрерывны.
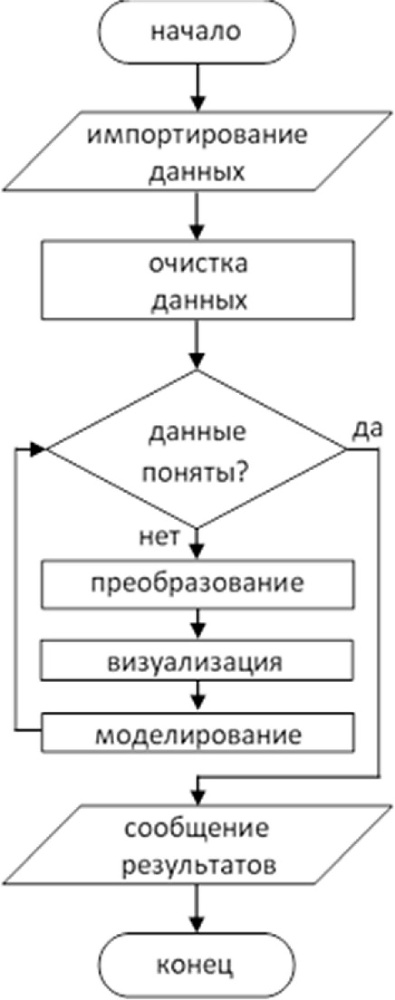
В пакете mixOmics, сильный акцент делается на графическое представление, чтобы лучше интерпретировать и понять отношения между различными типами данных визуализируют структуру корреляции как на выборочных значениях, так и на шкале интервалов. А начинается использование рассматриваемого пакета со ввода данных. Напомним блок-схему основного алгоритма статистической обработки педагогических и социальных данных, концептуально выкристаллизовавшегося к концу предыдущей части книги:
Как видим, обработка начинается со ввода данных, их предварительного импортирования и очистки. К предварительной обработке данных перед анализом данных с помощью mixOmics предъявляются следующие требования:
Различные типы педагогических данных могут быть изучены и интегрированы с mixOmics. Методы могут обрабатывать показатели успеваемости, измеренные в непрерывном масштабе или полученные на основе данных подсчета, которые становятся непрерывными данными после предварительной обработки и нормализации.
Пакет mixOmics не справляется с нормализацией, так как он универсален и охватывает широкий спектр данных. До начала анализа предполагается, что наборы данных были нормализованы с использованием соответствующих методов нормализации педагогических данных и предварительно обработаны, когда это возможно.
В то время как методы mixOmics могут обрабатывать большие массивы данных (несколько десятков тысяч переменных-предикторов), рекомендуется предварительно фильтровать данные до менее чем 10 000 переменных-предикторов на набор данных, например, с помощью медианного абсолютного отклонения, удалив пренебрежимо малые значения в наборах данных или путем удаления предикторов почти нулевой дисперсии. Такой шаг направлен на уменьшение вычислительного времени в процессе настройки параметров.
Методы mixOmics используют разложения матриц. Таким образом, числовая матрица данных или фреймы данных имеют n наблюдений или образцов в строках и p предикторов или переменных в столбцах.
В текущей версии mixOmics, ковариации, которые могут запутать анализ не включены в методы статистического анализа. Рекомендуется корректировать наборы этих ковариаций заранее, используя соответствующие унивариантные или многовариантные методы для удаления информационного шума.
Перечислим теперь основные методологические и теоретические основы, которые необходимо знать, чтобы эффективно применять mixOmics:
• Индивидуальные наблюдения или образцы: экспериментальные группы, на которых собиралась информация, например, обучающиеся, студенты, олимпиадные задания и прочее.
• Переменные, предикторы: считываемые измерения на каждом образце, например, успеваемость, посещаемость, решаемость задач, творческая самореализация и так далее.
• Дисперсия: измеряет уровень распылённости одной переменной. Как правило оценивается дисперсия целых компонентов, а не считываемых переменных. Высокая дисперсия указывает на то, что точки данных очень отличаются от среднего, и друг от друга (разбросаны).
• Ковариация: измеряет прочность взаимосвязи между двумя переменными, то есть являются ли они ковариантами друг друга. Высокое значение ковариации указывает на сильную связь, например, посещаемость и успеваемость у отдельных обучающихся часто различаются примерно одинаково; в общем случае, самые низкие и самые высокие значения коэффициента ковариации не имеют нижнего или верхнего предела.
• Корреляция: нормализованная версия ковариации, значения которой ограничены отрезком от -1 до 1.
• Линейная комбинация: разные переменные могут объединяться в одну путем умножения каждой из них на коэффициент и сложения полученных результатов. Линейная комбинация успеваемость a и посещаемости b может быть 2∙a – 1,5∙b с коэффициентами 2 и -1,5, присвоенных успеваемости и посещаемости соответственно.
• Компонент: искусственная переменная, построенная из линейной комбинации наблюдаемых переменных в данном наборе данных. Переменные коэффициенты оптимально определяются на основе какого-то статистического критерия. Например, в основном компоненте анализа определяются коэффициенты (основного) компонента, с тем чтобы максимизировать дисперсию компонента.