Ссылки:
1) Машинное обучение для людей: https://vas3k.ru/blog/machine_learning/
2) Русское датасаенс коммьюнити: https://ods.ai
Источник фото
4 Распознавание цифр без нейросетей
Продолжаю изучать нейронные сети (НС). Если вам неинтересны технические детали НС (ну, вдруг), а в посте ищете только смехуечки, промотайте текст до середины (фразы "тупой комп"), там пара абзацев для гуманитариев.
Итак, прочитал еще пару статей. Многое прояснилось, но вопросы остались. Сигмоидная функция f(х) = 1/(1+e^-х). По описанию страшная вещь! А по факту – просто преобразователь данных. Чтобы значения от [-ထ..+ထ] преобразовать в [0..1].
Нейрон смещения – тот же преобразователь, чтобы сдвинуть функцию (полученные значения) влево или вправо по оси х. Т.е. из диапазона [0..1] перейти, например, в диапазон [3..4].
Но главное, я по-прежнему не понимаю как на физическом уровне устроен процесс обучения и распознавания НС.
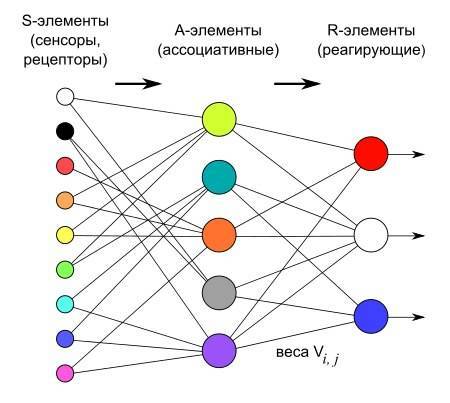
Работу НС обычно описывают так. Есть НС с 3мя слоями: входным, средним и выходным. Присваиваем нейронам среднего слоя случайные веса. Подаем на входной слой образец для обучения. Накладываем каждую точку входного изображения на входной слой. Если на нейроне входного слоя есть сигнал, умножаем его на вес связанного нейрона из 2-го слоя и передаем на 3-ий выходной слой. Выходной слой суммирует пришедшие сигналы со 2-го слоя и пропускает его через функцию активации (ту самую сигмоиду) чтобы преобразовать сигнал в [0..1].
По сигналу 0 или 1 НС говорит на фото кошка или таки собака. Если НС ошиблась, вычисляем "методом градиентного спуска" какие веса должны быть у нейронов 2-го слоя, чтобы минимизировать ошибку. Меняем веса нейронов через "метод обратного распространения ошибки". Подаем на вход НС все больше данных, НС учится, мутки мутятся, ошибка уменьшается и НС всё лучше распознает данные.
Вроде понятно, но что конкретно? Как сделать НС с нуля? Как она научится распознавать изображение? Зачем расставлять случайные веса нейронов (приносить шум в систему) в начале обучения? Зачем менять веса нейронов на каждой итерации через градиентный спуск? Разве НС не будет перенастраиваться каждый раз и запоминать последний образец? Как методом обратного распространения ошибки менять веса всех нейронов так, чтобы общая вероятность распознавания НС увеличивалась после каждой итерации? Разве возможно уменьшать выходную ошибку f_error(х) если она зависит от кучи параметров х1…хn, а сами параметры х не должны влиять друг на друга?
В общем, я не понял как создать НС с нуля. Поэтому решил сделать промежуточное грубое решение исходя из того, что ясно на данный момент.
В чудесном новом мире датасаенс и нейронных сетей есть свой аналог простейшего приложения HelloWorld, как это принято в остальном ИТ. Задача состоит в том, чтобы написать программу, которая распознает рукописные цифры 0..9. Всего-то.
Я уж было решил взять тетрадь в клеточку, написать по страничке каждую цифру, отсканировать и создать таким образом набор данных для распознавания. Но тут открыл для себя прекрасный сайт kaggle.com с кучей бесплатных датасетов, конкурсами и datascience-кудесницами. Оттуда скачал *.csv датасет MNIST с 60+10 тыс рукописных цифр в размере 28х28 точек собранных из сканов контрольных работ американских школьников.
Реализовал простой алгоритм. Назвал его "метод вероятностного накопления". La méthode de l'accumulation de probabilité (fr). На всякий случай забью название, вдруг докторскую еще по ней защищать.
Суть в том, чтобы в режиме обучения для каждой цифры просуммировать веса каждой точки ее изображения для всех тренировочных образов. После тренировки НС у нас будут 10 матриц 28х28 с весами каждой точки для цифр 0..9.
В режиме распознавания подаем на вход скан цифры и определяем пересечения с матрицами цифр 0..9. Если точка закрашена в образце и матрице, суммируем вес из матрицы. Если в образце точка закрашена, а в матрице нет, вычитаем штрафные очки. Это защита от кейса "закрасим всю область черным и получим цифру 8". Матрица с максимальной суммой считается распознанной цифрой 0..9.
В общем долго объяснять, а кода получилось всего ничего ~100 строк. См. код в скринах и ссылку в конце.
Можно улучшить алгоритм. Если точка не попала в пересечение, находить ближайшую и добавлять ее вес с неким коэффициентом. Можно делать изображения черно-белыми (сейчас серое). При совпадении точек умножать ее вес на вес из матрицы и др.
Но даже с исходными условиями получилось довольно неплохо. НС корректно определило цифру в 57% случаев при тренировке 5 тыс изображений и 5тыс для теста.
Правда на вики пишут, если правильно построить НС, можно добиться 99.8% корректно распознанных цифр. На кривой козе к Тьюрингу не подъедешь.
В общем, надо копать тему дальше. Есть инструменты обучения НС более высокого порядка – Google/TensorFlow, Microsoft/Azure, Amazon/AWS, Яндекс/DSVM. Где нужно задать только данные и параметры обучения и можно использовать НС не зная какие алгоритмы в ней работают. Но все-таки хочу знать что у этой штуки под капотом. Без этого пегого дудочника не напишешь и в техкранч не попадешь.
Как я сказал выше, основная проблема в том, что я не понимаю как НС должна работать "по-настоящему". Что бесит – даже создатели НС, той же DeepBlue (побила Каспарова в шахматах) или AlphaGo (разгромила чемпиона мира по ГО) не могут внятно объяснить, как работает их НС и почему она сделала определенный ход.
Еще смешнее с появившимися последнее время интеллектуальными голосовыми/чат помощниками – Сири, Алисой и Олегом. На жалобу клиентки, что ей не удается войти в моб банк по отпечатку пальца, Олег посоветовал отрезать ей пальцы.
Лол, кек. А что в итоге? Авторы Олега не смогли объяснить его кровожадность. Типа, Олег еще учится, потом станет умнее. Имхо, это не ИИ, а просто перебор фраз, части которых использовались в похожем контексте, а Олег тупо их склеил в примерно осмысленную фразу. Это не интеллектуальный помощник, а буллшит генератор. По развитию Олег не ушел от ELIZA, видел такую программу поддерживающую разговор с человеком еще в 1996 г (создана в 1966 г!).
Это же алгоритм и тупой комп! Что ему дали, то он и посчитал. В ИТ нет ответа "я кнопочку нажала и все пропало, не знаю что произошло". Всегда есть конкретная причина у всего и всегда есть ответ на поставленный вопрос. Может трудно получить ответ, но он всегда есть.
Математика – точная наука, не то что эти ваши гуманитарные сопли:
– География – бессмысленное заучивание списка стран и столиц.
– История – зазубривание списка фактов и сознательное искажение этих фактов в угоду текущей повестке.
– Литература – изучение контента, написанного алкоголиками, самоубийцами и депрессивными интеллигентами, не нашедших своего места в жизни и рефлексирующих над проблемами давно утративших актуальность.
{kind=link}