Это непрерывный процесс; Google всегда добавляет новые страницы в индекс или обновляет их, если они меняются. Индекс огромен, он весит более 100 млн ГБ. Для того чтобы поместить его на внешнем жестком диске объемом 1 ТБ, потребовалось бы 100 тысяч таких дисков, а если поставить их друг на друга, высота составит примерно 1,5 км.
Поиск слова
Поиск в Google работает таким образом: он принимает запрос (текст, введенный в строку поиска) и просматривает индекс, чтобы найти наиболее подходящие страницы. Как Google это делает? Самый простой способ – найти определенное ключевое слово, что-то вроде нажатия Ctrl+F или Cmd+F для поиска в гигантском документе Word. Именно так работали поисковые системы 1990-х годов: они искали запрос в своем индексе и отображали страницы с наибольшим количеством совпадений, атрибут, называющийся плотностью ключевых слов.
Как выяснилось, эту схему довольно легко обойти. Если ввести в поисковую строку «шоколадный батончик Snickers», то можно предположить, что snickers.com окажется в списке первых найденных страниц. Но если поисковая система просто считала количество повторяющихся слов «сникерс» на странице, кто-то мог бы создать «левую» страницу со словом «сникерс, сникерс, сникерс, сникерс» и т. д., и таким образом она бы оказалась в числе первых в результатах поиска. Очевидно, что такая страница окажется не очень полезной.
PageRank
Взамен алгоритма плотности ключевых слов основным нововведением Google стал алгоритм под названием PageRank, созданный Ларри Пейджем и Сергеем Брином в 1998 году в рамках работы над кандидатской диссертацией. Пейдж и Брин обратили внимание, что оценить приоритетность страницы можно, посмотрев на другие важные страницы, со ссылкой на нее. Это словно, находясь на вечеринке, узнать, что кто-то популярен, увидев этого человека, окруженного другими известными людьми. PageRank присваивает каждой странице оценку на основании других своих оценок, данных всем остальным страницам, которые дают ссылку на эту страницу. (Оценка тех страниц зависит от других страниц, которые дают на них ссылку, и т. д.; это рассчитывается с помощью линейной алгебры.)
Например, в случае создания новой страницы об Аврааме Линкольне, ее PageRank был бы очень низким. Но если бы какой-нибудь малоизвестный блог добавил ссылку на эту страницу, это повысило бы ее PageRank. PageRank больше заботится о качестве входящих ссылок, чем об их количестве, поэтому даже если десятки непопулярных блогов дадут ссылку на эту страницу, пользы будет мало. Но если бы газета New York Times (которая, скорее всего, имеет высокий PageRank) дала бы ссылку на нее, то ее PageRank взлетел бы.
Как только Google находит в своем индексе все страницы, в которых упоминается поисковый запрос, он ранжирует их по нескольким критериям, включая PageRank. У Google также есть много других критериев: он учитывает последнее обновление страницы, пропускает веб-сайты, похожие на спам (например, сайт «сникерс, сникерс, сникерс, сникерс», о котором писалось выше), учитывает местоположение (он может выдать сайт Национальной футбольной лиги, если пользователь ввел запрос «футбол» и при этом находится в США, и Английскую Премьер-лигу, если он ввел аналогичный запрос, находясь в Англии) и многое другое.
Надуть Google?
Однако у PageRank есть свои подводные камни. Подобно тому как спамеры злоупотребляют плотностью ключевых слов (как в случае со «сникерс, сникерс, сникерс, сникерс»), они начали создавать линкофермы, или страницы, содержащие тонны ссылок на сайты, не несущие полезного контента. Владельцы веб-сайтов могут платить линкофермам за добавление ссылок на страницы, что искусственно повысит их PageRank. Однако Google стала очень неплохо распознавать и игнорировать линкофермы.
Но существует еще несколько основных способов обмануть Google. Появилась целая индустрия поисковой оптимизации (SEO), помогающая владельцам веб-сайтов взломать алгоритм поиска Google и сделать так, чтобы их страницы появлялись в топе результатов поиска. Основная форма SEO – это получение большего количества страниц со ссылкой на желаемую страницу. SEO содержит множество других методов, например ввод правильных ключевых слов в название и заголовок страницы или создание перекрестных ссылок на страницы сайта.
Однако алгоритм поиска Google постоянно меняется; компания выпускает небольшие обновления более 500 раз в год. Периодически появляются серьезные обновления, и после выхода каждого из них SEO-специалисты пытаются найти способы использовать эти изменения для продвижения. Например, в 2018 году Google изменила свой алгоритм, чтобы ускорить загрузку страниц на мобильных устройствах. Ведущие специалисты предложили владельцам веб-сайтов создавать укороченные версии обычных страниц с помощью инструмента Accelerated Mobile Pages (AMP).
Как Spotify рекомендует музыку?
Утром каждого понедельника Spotify отправляет своим слушателям список из 30 треков, которые волшебным образом идеально соответствуют их вкусам. Этот плейлист под названием Discover Weekly мгновенно стал популярным: в течение шести месяцев после запуска, в июне 2015 года, он был прислан более 1,7 млрд раз. Но как Spotify настолько хорошо удается узнать предпочтения своих 200 млн пользователей?
Spotify действительно нанимает специалистов, которые вручную создают открытые плейлисты, но подготовить их для всех 200 млн пользователей никоим образом невозможно. Вместо этого Spotify применяет алгоритм, который запускается каждую неделю.
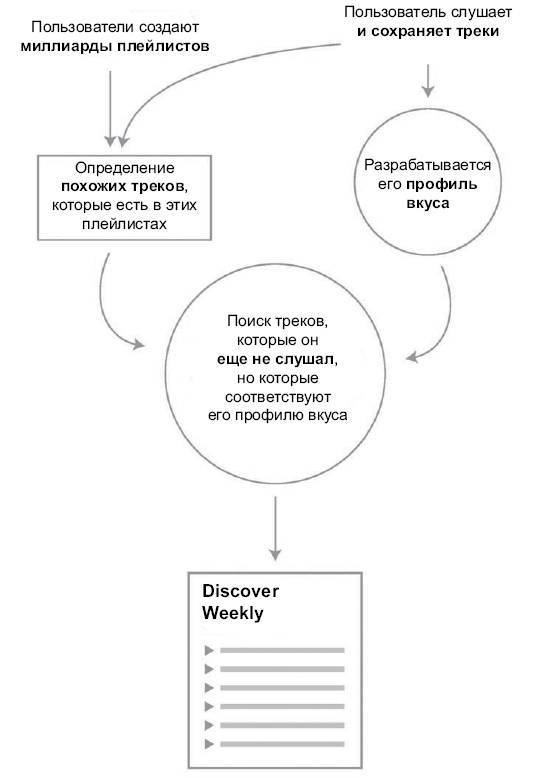
Алгоритм Discover Weekly начинает свою работу с изучения двух основных моментов. Для начала он просматривает все треки, которые прослушал пользователь и которые ему настолько понравились, что он добавил их в библиотеку или плейлист. Эта программа достаточно умна, чтобы понять, что если трек переключили в течение первых тридцати секунд, то, вероятно, он не понравился. Затем алгоритм рассматривает все плейлисты, созданные другими людьми, предполагая, что каждый из них объединен какой-то общей темой; например, может быть плейлист для бега или плейлист Beatles.
Получив эти данные, Spotify использует два метода поиска треков, которые могут понравиться. Первый метод предполагает сравнение двух наборов данных, чтобы выяснить, какие из новых треков относятся к тем, которые нравятся пользователю. Предположим, что кто-то создал плейлист из восьми треков и семь из них есть в библиотеке пользователя. Ему, скорее всего, нравится такая музыка, поэтому Discover Weekly может порекомендовать тот трек, которого нет в его библиотеке.
Алгоритм Spotify для автоматической рекомендации музыки. Источник: Quartz
Эта методика называется «совместная (коллаборативная) фильтрация», и именно ее использует Amazon, чтобы предложить товары, которые могут заинтересовать клиента, исходя из его истории покупок и покупок миллионов других пользователей. Список рекомендуемых фильмов, которые предлагает Netflix, видео, предлагаемые YouTube, и список возможных друзей на Facebook – все это возможно благодаря совместной фильтрации.
Совместная фильтрация становится все более полезной, так как сервис получает больше пользователей. В нашем примере, если у Spotify появляется больше пользователей, то программе легче найти человека с похожим вкусом и, следовательно, легче предложить рекомендацию. Но, по мере роста пользовательской базы, работа таких алгоритмов может стать медленнее и требовать большого объема вычислений.
Второй метод, который использует Spotify для создания плейлиста, – это «профиль вкуса». На основе только тех треков, которые прослушал пользователь и которые ему понравились, Spotify определяет, какие жанры (например, инди-рок или R&B) и поджанры (например, Chamber Pop или New Americana) он предпочитает, и рекомендует музыку этих жанров. Это другая форма стратегии Spotify – предлагать треки на основании ранее прослушанных.