I suppose that each language has its own ability to produce prefixation and that this ability doesn’t change seriously during all stages of its history.
Also I suppose that prefixation ability demonstrates itself in any circumstances, i.e.: it is manifested by any means: by means of original morphemes existing in a certain language or by borrowed morphemes.
If a language has certain prefixation ability it is shown anyway. That’s why I don’t make difference between original and borrowed affixes.
Also for current consideration is not principal whether this or that affix is derivative or relative: if we take into account relative affixes only, then, for instance, Japanese is a language without prefixes.
That’s why we should define prefixes not by its derivative or by its relative role but by its positions inside word form, prefix is any morpheme that meets the following requirements:
1) it can be placed only left from nuclear position;
2) it never can be placed upon nuclear position;
3) between this morpheme and nuclear can’t be placed any meaningful morpheme with its clitics (i.e.: between nuclear root and prefix can’t be placed a meaningful morpheme with its auxiliary morphemes).
I am specially to note that there are no so called semi-prefixes. If a morpheme can be placed in nuclear position it is meaningful morpheme and any combinations with it should be considered as compounds.
Thus can be resumed the following:
1) Each language has its own ability to produce prefixation and this ability doesn’t change seriously during all stages of its history.
2) Prefixation ability is manifested by any means: by means of original morphemes existing in a certain language or by borrowed morphemes. That’s why the method doesn’t suppose distinction between original and loaned affixes.
3) Genetically related languages are supposed to have rather close values of Prefixation Ability Index.
2.1.3. PAI calculation algorithm
How Prefixation Ability Index (here and further in this text abbreviation PAI is used) can be measured?
Value of PAI is portion of prefixes among affixes of a language.
Hence, in order to estimate portion/percentage of prefixes of a certain language we should do the following:
1) Count total number of prefixes;
2) Count total number of affixes;
3) Calculate the ratio of total number of prefixes to the total number of affixes.
Why is it important to count total number of prefixes and then calculate the ratio to the total number of affixes but not to estimate PAI by frequency of prefix forms in a random text?
A certain language can have quite high value of PAI but in a particular text word forms with prefixes can be of low frequency. Our task is to estimate portion of prefixes in grammar but not portion of prefix forms in a random text. Prefixes/World index estimated by Greenberg was exactly that estimation of prefix forms frequency in a text (Greenberg 1960).
Of course, that index also can give some general notion of prefixation ability of a language, though it is extremely rough and inaccurate since in a randomly chosen text can be very little amount of words with prefixes: the longer text is the more precision is the conclusion but anyway error of such estimation still remains very high; while when we count all exiting affixes of a certain language potential error is extremely low and even if we occasionally forget some affixes it doesn’t influence seriously on our results.
Moreover I am to note that despite Greenberg made great work on the field of typology he didn’t actually use those results in his research; he was an adept of megalocomparison and made his conclusions basing on “mass comparison” of lexis but not on structural correlations; his interest in typology was a “glass beads game” and was separated from his actual field of studies.
To those who think, that it’s impossible to estimate number of morphemes since living language always changes, I am to tell that living language doesn’t invent new morphemes every day, especially auxiliary morphemes. The fact that learning a language we can use descriptions of its grammar written some decades ago is the best proof that grammar is a very conservative level of any language.
Hence, we can estimate total number of affixes of a living language as far as we can get its description where all stable forms are represented. And there is no need to care of what can be in a certain language in future, i.e.: we consider current stage of living language and don’t care of possible future stages since they simply don’t exist yet.
As for possibility of count, I am to tell that even set of words is countable set while set of morphemes and especially auxiliary morphemes is not just countable set but also is finite set.
2.1.4. PAI method testing: from a hypothesis toward a theory
In order to test PAI hypothesis I paid attention to some languages of firmly assembled stocks: Austronesian, Indo-European and Afroasiatic.
2.1.4.1. PAI of languages of Austronesian stock
Polynesian group
Eastern Polynesian Subgroup
Hawaiian 0.82 (calculated after Krupa 1979)
Maori 0.88 (calculated fater Krupa 1967)
Tahitian 0.66 (calculated after Arakin 1981)
Samoan-Tokelauan subgroup
Samoan 0.5 (calculated after Arakin 1973)
Tongic subgroup
Niuean 0.8 (calculated after Polinskaya 1995)
Tongan 0.78 (calculated after Fell 1918)
Philippine group
South Mindanao subgroup
T’boli 0.72 (calculated after Porter 1977)
Northern Luzon subgroup
Pangasinan 0.6 (calculated after Rayner 1923)
Malayo-Sumbawan group
Malay subgroup
Indonesian 0.53 (calculated after Ogloblin 2008)
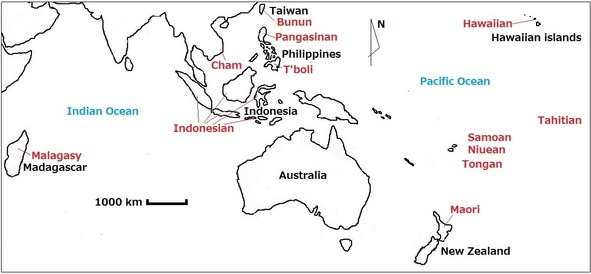
Pic. 2. Map representing location of Austronesian languages mentioned in current chapter: languages are marked by red, place names are maked by black.
Chamic subgroup
Cham 0.6 (calculated after Aymonier 1889; Alieva, Bùi 1999)
Formosan group
Bunun 0.8 (calculated after De Busser 2009)
Eastern Barito group
Malagasy 0.74 (calculated after Arakin 1963)
2.1.4.2. PAI of languages Indo-European stock
German group