Manual of comparative linguistics
Prefixation Ability Index (PAI) and Verbal Grammar Correlation Index (VGCI)
Alexander Akulov
Dedicated to the memory
of Prof. Alexander B. Valiotti
© Alexander Akulov, 2015
Created with intellectual publishing system Ridero
1. Why typology but not lexis should be the base of genetic classification of languages
In contemporary linguistics can be seen an obsession of proving relationship of certain languages by comparison of lexis and an obsession to separate typology from comparative linguistics. The main problem of all such hypotheses is that they are not based on any firmly testable methods but just on certain particular points of view and on “artist sees so” principle. Tendency to think that typology should be separated from historical linguistics was inspired by Joseph Greenberg in the West and by Segrei Starostin and Nostratic tradition in USSR/Russia. Despite followers of Nostractics insist that their methods differ from those of Greenberg actually their methods are almost the same: they take word lists, find some look-alike lexemes1 and on the base of these facts conclude about genetic relationship of certain languages. Followers of Greenberg and Starostin consider typological studies as rather useless “glass beads game”. Typological items are never considered as a system by adepts of megalocomparison2; usually some randomly chosen typological items are taken outside of their appropriate contexts. For instance, active or ergative typology, or the fact of so called isolating or polysintetic typology (i.e.: items that are not usual for native languages of researchers and that shock researchers’ minds) are considered as interesting exotic items, while no attention is paid to holistic and systematic analysis of language structures. Such approach makes typology be a “curiosity store” but not a tool of comparative linguistics, however, initially, according to founding-fathers of linguistics, it is typology that should be the main tool of comparative linguistics. According to the mythology created by adepts of megalocomparison comparative linguistics has actually little connection with typology and makes its statements with use of lexicostatistical “hoodoo”. Megalocomparativists often object on this critics saying that they also pay attention to structural issues and they also compare morphemes beside lexis. However, we know very well what actually means megalocomparative comparison of morphemes: it means analysis in a lexical way, i.e.: only material components are compared so there is no difference between such comparison of material components of morphemes and comparison of lexemes. The cause of it is the fact that megalocomparativists ignore that any morpheme consists of three components: meaning, position and material expression and reduce morpheme to their material implementation. Almost no attention is paid to the fact that grammar is first of all positional distribution of certain meanings. There is a presupposition that genetic relationship of two languages can be proved by discovering of look-alike lexemes of so called basic vocabulary and by detecting certain “regular phonetic correspondence”. However, yet Atoine Meillet pointed on the fact that lexical and phonetic correspondences can appear due to borrowings and can’t be proves of relationship:
Grammatical correspondences provide proof, and they alone prove rigorously, but only if one makes use of the details of the forms and if one establishes that certain particular grammatical forms used in the languages considered go back to a common origin. Correspondences in vocabulary never provide absolute proof, because one can never be sure that they are not due to loans (Meillet 1954: 27).
Correspondence in vocabulary and regular phonetic correspondence can be between any randomly chosen languages. For instance it is possible to find some regular correspondence between Japanese and Cantonese and even “prove” their relationship: boku Japanese personal pronoun “I” used by males – Cantonese buk “servant”, “I”; Japanese bō “stick” – Cantonese baang “stick”; Japanese o-taku “your family”, “your house” or “your husband” – Cantonese zaak “house”; Japanese taku “swamp” in compounds – Cantonese zaak “swamp”; Japanese san “three” – Cantonese sam; Japanese shin “forest” used in compounds – Cantonese sam “forest”; Japanese roku “six” – Cantonese lük; Japanese ran “orchid” – Cantonese laan “orchid”. If there would be no other languages of so called Buyeo3 stock4 and no languages of Chinese stock we would have no ability to single those words as items borrowed from Southern Chinese dialects since they have same regular and wide use as well as words of Japanese origin. In the case of Japanese and Cantonese we know history of correspondent stocks rather well and have many firm evidences that Japanese isn’t a relative of Chinese stock.
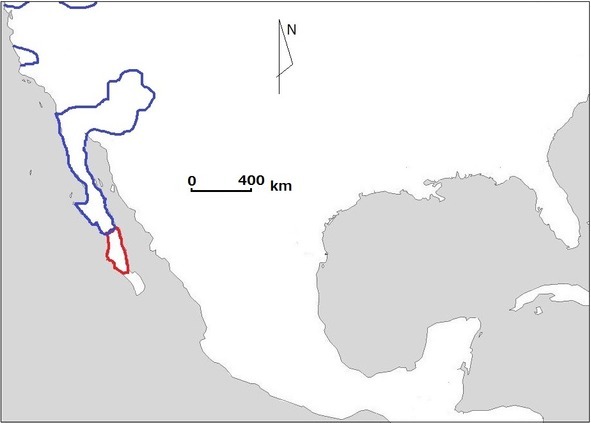
If someone thinks that the example of Japanese and Cantonese is just a weird joke, then everyone can take a look at the procedure that was used by Greenberg in order to prove that Waikuri language belonged to Hokan stock5: the conclusion was based on comparison of FOUR (!) words only (Poser, Campbell 1992: 217 – 218). Also we should keep in mind that Greenberg actually didn’t care much about precise phonetic correspondence and superficial likeness was rather sufficient for him.
Pic.1. Map representing location of hypothetical Hokan stock (blue) and Waicuri language (red)
Phonetic correspondences themselves can be even between completely unrelated languages and so a stock can’t be proved by regular correspondences, but regular correspondences should be proven by existence of a stock since true regular phonetic correspondences exist only inside stocks.
Then, it was Swadesh yet who warned that comparison of vocabularies can’t be proof of genetic relationship of languages and some other methods should be used for it, i.e.: analysis of structures. Swadesh method is method of estimation of approximate time of divergence of languages which have been already proved to be relatives. However, Swadesh’s warning has been well forgotten. Also we should keep in mind that even so called basic lexicon is actually culturally determined (Hoijer 1956) and borrowings can be inside it (above considered example of Japanese and Cantonese).
Moreover, we should keep in mind the fact that there are thousands of languages which history is completely unknown and which are described only in their current phase and so there is no ability to distinguish borrowings in their lexicon and so it’s completely impossible to say anything about their genetic relationship basing on methodology of comparison of lexis.
Methodology that ignores structural/grammatical issues allows different scholars to make completely different conclusions about the same language, for instance: Sumerian is thought to be a relative of Kartvelian stock (Nicholas Marr), of Uralic stock (Simo Parpola), of Sino-Tibetan (Jan Braun), of Mon-Khmer (Igor M. Diakonoff) or even of Basque (Aleksi Sahala). Another notable example is Ainu that is attributed to Altaic (James Patrie), to Austronesian (Murayama Shichirō), to Mon-Khmer (Alexander Vovin)6. The most notable fact is that all such attempts coexist and all are considered by public as rather reliable in the same time, obviously it looks much a like a plot for a vaudeville sketch rather than a serious matter of a science.