Но это бы еще не беда: не столь важно, форму какого геометрического тела примет семантическое пространство. Хуже, что точки слов тоже начинают «плавать» в меняющемся пространстве и из точек превращаются в размытые «облака», которые пересекаются и смешиваются.
Размыванию точек способствует еще одно важное обстоятельство. Вычисленные, казалось бы, точно координаты слов в пространстве на самом деле точны лишь относительно, поскольку вычисление средних оценок носит не абсолютный, а вероятностный характер. Скажем, мы опросили группу в 50 информантов и вычислили по их ответам средние оценки слов. Будут ли эти оценки точно такими же, если мы те же слова предложим другой группе в 50 человек? Вовсе не обязательно. Отдельные средние оценки могут совпадать, но в большинстве полученные числа будут близки к прежним, однако будут от них более или менее отличаться. Другими словами, средние оценки могут колебаться от эксперимента к эксперименту в каких-то пределах. Значит, в пространстве это опять-таки не точки, а «облачка».
Вот и получается, что в результате и куб не куб, и точки не точки, а некая бесформенная емкость, наполг ненная космами тумана или клубами дыма.
Но даже и это еще не все соображения, разрушающие осгудовский «семантический куб». Главное — впереди.
Работая с «семантическим дифференциалом» на материале русского языка, советские исследователи В. Петренко и Н. Павлюк независимо друг от друга обнаружили, что в нашем языке упрямо выделяется еще один фактор, еще одно измерение пространства, которого не было у Ч. Осгуда. Эта мера объединяет пучок таких шкал, как «женственное — мужественное», «нежное — грубое», «мягкое — твердое», «удобное — неудобное», «округлое — угловатое» и т. п. Фактор получил название родокомфортности и стало ясно, что качественно-признаковое пространство не обязательно трехмерно. Четвертая мера обнаружилась и в английском языке, только гораздо менее явно, поэтому-то Ч. Осгуд и не выделил ее.
Этот факт вполне объясним, если вспомнить, что в русском языке есть грамматическая категория рода, а в английском ее нет. То, что мы, русские, все предметы и явления грамматически делим на «мужчин» и «женщин», не могло не отразиться на наших признаковых оценках слов. Разумеется, мы не считаем, что дубовый стол — мужчина, а рябиновая трость — женщина. Но ведь поем: «Как бы мне, рябине, к дубу перебраться». В переводе на английский язык содержание этой песни покажется англичанину весьма странным: он не сможет взять в толк, с чего это одно дерево воспылало страстью к другому — ведь в английском и дуб и рябина одинаково «никакого» рода. Разумеется, в английском переводе можно объяснить, что дуб — это мужчина, а рябина — девушка, но эффект будет совсем не тот: логическое объяснение в художественном отношении ни в какое сравнение не идет с непосредственным воздействием самой ткани, самой плоти языка.
Наше «языковое поведение» все насквозь пронизано «родовой окраской». Мы говорим: «Нож упал — мужчина придет, упала ложка — женщина в гости спешит». В английском такая примета невозможна — ни нож, ни ложка рода не имеют. Мы можем обругать старым пнем только мужчину и никак не женщину, зато выдрой — только женщину, хотя звери-выдры есть и самцы.
Игрой на родокомфортном факторе в нашем языке выражаются тончайшие оттенки смысла, совершенно не переводимые на «безродовые» языки. Например, А. Вознесенский пишет:
Ты кричишь, что я твой изувер,
и, от ненависти хорошея,
изгибаешь, как дерзкая зверь,
голубой позвоночник и шею.
Обратите внимание, каким удивительным способом открывается в этом четверостишии, что «ты» — это женщина: только формой прилагательного дерзкая, неправильно согласованной с существительным мужского рода зверь. Неправильное словосочетание кажется тем не менее естественным, поскольку существительные такой формы могут иметь и женский род (например, дверь). Но оригинальное соединение разнородовых форм создает необычный эффект, перевести который на язык без грамматической категории рода никак нельзя.
Итак, пространство может быть и четырехмерным, а тогда геометрическая интерпретация отпадает и возможность вычисления расстояний между словами-точками становится проблематичной.
И еще одно, не менее убийственное для «семантического пространства» обстоятельство.
Оказывается, при измерении некоторых слов обнаруживается неожиданная картина — слово располагается не в одной точке шкалы, а сразу в двух противоположных точках. К примеру, слово регби по шкале «хорошее — плохое» получает среднюю оценку 2,9, то есть оценивается большинством информантов как бы «никаким». Но это вовсе не так. На самом деле примерно половина отвечающих единодушно считает, что регби — это что-то «хорошее» (видимо, им нравится эта игра), а другая половина столь же единодушно полагает, что это нечто «плохое» («это не игра, а свалка какая-то»). Но почти никто, заметьте, не посчитал регби «никаким». Значит, средняя оценка фиктивна, за усреднением она скрывает разнонаправленные тенденции. И таких слов множество: бокс, хоккей, пушка, огонь, суд, холостяк, женщина — это только несколько примеров слов «двойной оценки».
А вот слово дождь расположилось буквально на всей шкале, что и понятно: если вас спросят: «Дождь — это что-то хорошее или плохое?» — вы наверняка скажете — смотря какой, смотря где, смотря когда. У этого слова нет постоянного качественного ореола, он меняется в зависимости от ореолов слов-соседей.
Вот теперь и прикиньте, как можно расположить слова с двойными или меняющимися ореолами в любом пространстве — хоть трех-, хоть четырехмерном? Трудно что-нибудь придумать. Во всяком случае, «облака» таких слов вытягиваются почти на все пространство, как Млечный Путь.
Автоматический качественный классификатор
Создается впечатление, что в рассказе об осгудовском измерении значения получилось, как в известном анекдоте:
— Правда ли, что Том выиграл в лотерею «понтиак»?
— Да, правда. Только не Том, а Тим. И не «понтиак», а «кадиллак». И не в лотерею, а в карты. И не выиграл, а проиграл.
Но все-таки это не совсем так. Качественный ореол значения слова Ч. Осгуд действительно измерил, только геометрическое представление результатов измерений оказалось не совсем удачным. Во всяком случае, для компьютера.
Поэтому Н. Павлюк, обнаружив четвертую меру семантического пространства и убедившись в невозможности его графической интерпретации, стал искать новые пути семантических измерений. И поиски привели его к разработке простого (а значит, вполне доступного «пониманию» компьютера) и в то же время весьма эффективного способа автоматического оперирования с качественно-признаковыми ореолами слов.
Есть такая настольная игра. На игровом поле установлены разные отражатели, стенки, барьерчики, ловушки. Один или несколько шариков выскакивают на поле и движутся по нему, отражаясь от препятствий, застревая в ловушках. В конце концов шарики собираются в разных частях поля, в зависимости от чего играющими начисляются очки. Придуманный Н. Павлюком автоматический классификатор похож на эту игру. Посмотрите на рисунок.
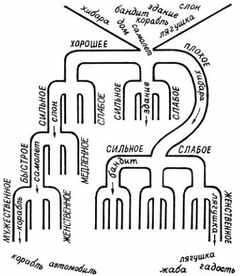
Представьте себе, что в верхнюю воронку засыпаются слова, которые распределяются по трубам этого сортировочного устройства в зависимости от наличия тех или иных характеристик. Сначала они попадают на первый уровень, где «хорошие» слова направляются налево, «плохие» — направо, а «никакие» — прямо. Теперь каждая из трех групп попадает на второй уровень. Там снова происходит сортировка: «хорошие и сильные» — направо, «хорошие и слабые» — налево, «хорошие и никакие» — прямо. Поскольку каждая из трех групп первого уровня делится еще на три группы, то групп уже получается 9. Затем третий уровень, где каждая из 9 групп делится еще на 3 в зависимости от «активности» слов. Групп уже 27. Четвертый уровень делит слова по признакам «мужественное — женственное», и групп становится 81.
