* * *
Как следует из названия, один из этих методов является прямым, а другой — обратным, однако оба используют один принцип. Представьте, что мы хотим отобрать характеристики, точнее всего описывающие тенденции голосования на парламентских выборах. Имеем пять известных характеристик выборки: покупательная способность, родной город, образование, пол и рост избирателя. Будем использовать для анализа тенденций нейронную сеть. Применив жадный прямой отбор, выберем первую переменную в задаче и смоделируем данные с помощью нейронной сети, используя только эту переменную. После того как модель построена, оценим точность прогноза и сохраним полученную информацию. Повторим аналогичные действия для всех остальных переменных по отдельности. По завершении анализа выберем переменную, для которой были получены лучшие результаты, и повторим моделирование с последующей оценкой модели, но уже для двух переменных. Предположим, что лучшие результаты были получены для переменной «образование». Проверим все возможные сочетания переменных, в которых первой переменной будет «образование». Получим модели «образование и родной город», «образование и пол», «образование и рост». И вновь, проанализировав четыре сочетания, выберем лучшее из них, к примеру «образование и покупательная способность», после чего повторим описанные выше действия уже для трех переменных, две из которых будут фиксированы. Этот процесс будет повторяться до тех пор, пока с добавлением очередной переменной точность новой модели относительно предыдущей, содержащей на одну переменную меньше, не перестанет возрастать.
Жадное обратное исключение проводится прямо противоположным образом: в качестве исходной выбирается модель, содержащая все переменные, затем из нее последовательно исключаются переменные так, чтобы качество модели не ухудшалось.
Как можно догадаться, этот метод является не слишком интеллектуальным: он не гарантирует, что будет найдено наилучшее сочетание переменных, а также предполагает значительный объем вычислений, поскольку на каждом этапе необходимо выполнять моделирование заново.
Ввиду важных недостатков существующих методов отбора характеристик на специализированных конференциях постоянно предлагаются новые методы. Они обычно описываются тем же принципом, что и метод главных компонент, то есть заключаются в поиске новых переменных, которые замещают исходные и повышают плотность информации. Подобные переменные называются латентными. Они используются во множестве дисциплин, однако наибольшее распространение получили в общественных науках. Такие характеристики, как качество жизни в обществе, доверие участников рынка или пространственное мышление человека, — латентные переменные, которые нельзя измерить напрямую. Они измеряются и выводятся по результатам совокупного анализа других, более осязаемых характеристик. Латентные переменные обладают еще одним преимуществом: они сводят несколько характеристик в одну, тем самым уменьшая размерность модели и упрощая работу с ней.
Визуализация данных
Визуализация данных — дисциплина, изучающая графическое представление данных, как правило многомерных. Эта дисциплина стала популярной вскоре после образования современных государств, способных систематически собирать данные о развитии экономики, общества и производственных систем. В действительности визуализация данных и анализ данных — смежные дисциплины, так как многие средства, методы и понятия, используемые для упрощения визуализации, возникли в рамках анализа данных, и наоборот.
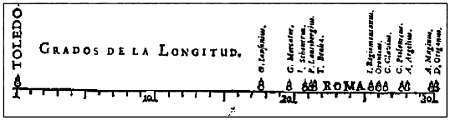
Возможно, автором первой известной визуализации статистических данных был Михаэль ван Лангрен, который в 1644 году изобразил на диаграмме 12 оценок расстояния между Толедо и Римом, предложенных 12 разными учеными. Слово «ROMA» («РИМ») указывает оценку самого Лангрена, а маленькая размытая стрелка, изображенная под линией примерно в ее центре, — корректное расстояние, вычисленное современными методами.
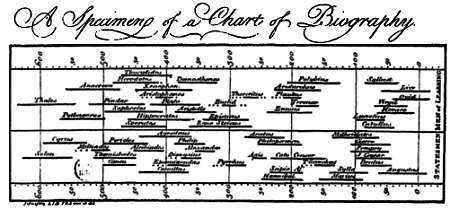
Еще в XVIII веке Джозеф Пристли составил диаграмму, где изобразил, в какое время жили некоторые выдающиеся деятели античности.
В том же столетии, благодаря трудам Иммануила Канта, который утверждал, что именно представление делает объект возможным, а не наоборот, стало понятно, что нельзя вести споры о знаниях или реальности, не учитывая, что эти самые знания и реальность создает человеческий разум. Так представление и визуализация данных заслуженно заняли важнейшее место в науке.
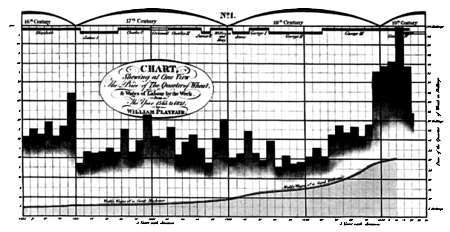
Позднее, во время Промышленной революции, начали появляться более сложные методы представления данных. В частности, Уильям Плейфэр создал методы, позволяющие представить изменение объемов производства, связав их с колебаниями цен на пшеницу и с величиной заработной платы при разных правителях на протяжении более 250 лет.
Благодаря вычислительной технике специалисты в сфере визуализации данных начали понимать, каким должно быть качественное представление данных для их быстрой интерпретации. Один из важнейших моментов, которые следует принимать во внимание (помимо самих данных, модели представления и графического движка, используемого для визуализации), — ограниченные способности восприятия самого аналитика, конечного потребителя данных. В мозгу аналитика происходят определенные когнитивные процессы, в ходе которых выстраивается ментальная модель данных. Однако эти когнитивные процессы страдают из-за ограниченности нашего восприятия: так. большинство из нас неспособны представить себе больше четырех или пять измерений. Чтобы упростить построение моделей, необходимо учитывать все эти ограничения. Качественная визуализация данных должна представлять информацию в иерархическом виде с различными уровнями подробностей. Также визуализация должна быть непротиворечивой и не содержать искажений. В ней следует свести к минимуму влияние данных, которые не содержат полезной информации или могут вести к ошибочным выводам. Рекомендуется дополнять визуализацию иными статистическими данными, указывающими статистическую значимость различной информации.
Для достижения всех этих целей используются стратегии, подобные рассмотренным в главе, посвященной анализу данных. Первая из них заключается в снижении размерности с помощью уже описанных методов, в частности, путем ввода латентных переменных. Вторая стратегия состоит в снижении числа выборок модели путем их разделения на значащие группы. Этот процесс называется кластеризацией (английское слово «кластер» можно перевести как «гроздь», «пучок»).
Кластерный анализ состоит в разделении множества результатов наблюдений на подмножества — кластеры, так, чтобы все результаты, принадлежащие к одному кластеру, обладали некими общими свойствами, необязательно очевидными. Кластеризация данных значительно упрощает их графическое представление, а также позволяет специалистам по визуализации понять изображаемые данные. Существует множество алгоритмов кластеризации, и каждый из них обладает особыми математическими свойствами, которые делают его пригодным для тех или иных типов данных.
Распознавание образов
В главе об анализе данных нельзя обойти стороной тему распознавания образов как одну из основных целей анализа. Для распознавания образов можно использовать все описанные выше средства: нейронные сети, метод опорных векторов, метод главных компонент и другие. Как вы видите, распознавание образов имеет непосредственное отношение к машинному обучению.