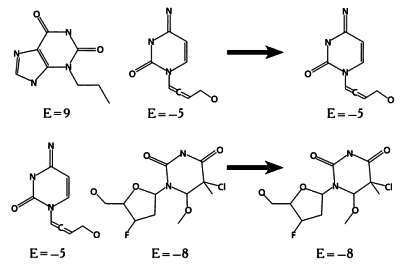
Следующий этап эволюционного алгоритма — размножение, в ходе которого на основе отобранных молекул создаются новые, сочетающие в себе свойства молекул предыдущего поколения. Так, путем скрещивания двух молекул, отобранных на предыдущем шаге, создаются две новые молекулы.
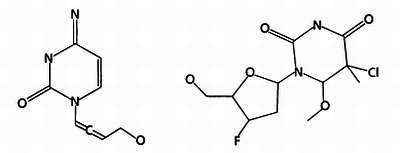
На следующей иллюстрации показано, как две молекулы делятся.
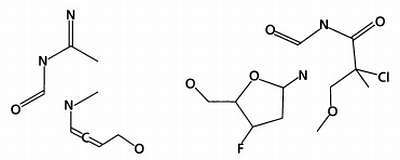
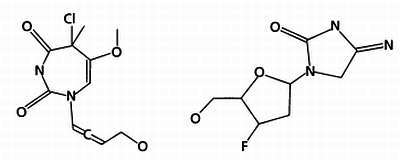
И, наконец, путем соединения частей этих молекул образуются две новые молекулы.
На этапе замещения особи первого поколения замещаются новыми, созданными на предыдущем этапе. Наиболее популярный и простой метод замещения — элитизм, при котором замещаются все молекулы предыдущего поколения за исключением одной, наиболее приспособленной. В нашем случае новое поколение будет состоять из двух молекул, полученных в результате скрещивания, и одной молекулы из предыдущего поколения с энергией взаимодействия, равной —8.
После замещения эволюционный цикл завершается и повторяется необходимое число раз. Иными словами, дальше производится оценка молекул второго поколения, затем среди них отбираются лучшие, и так далее, после чего формируется третье поколение молекул. Процесс повторяется, пока не будет достигнуто заранее определенное число поколений или популяция не сойдется, то есть 90 % особей не будут представлять собой одну и ту же молекулу.
Разумеется, мы приводим упрощенное описание процесса, а в действительности все обстоит намного сложнее. Но скажите, разве сам процесс не прекрасен?
Глава 3. Машинное обучение
Четверг, 6 мая 2010 года, 9:30 утра. Начинаются торги на американских фондовых биржах. Этот день ничем не отличался от остальных: утренняя сессия прошла без каких-либо аномалий. Но в 14:45 без явной причины некоторые самые важные рыночные котировки за несколько секунд обвалились. Даже с учетом высокой волатильности, характерной для финансовых рынков в период нестабильности, этот обвал был достаточно неожиданным: акции некоторых наиболее крупных и надежных компаний потеряли в цене более 60 %, а весь американский и, как следствие, мировой финансовый рынок обрушился за несколько минут. Индекс Доу-Джонса (один из наиболее популярных биржевых индексов) потерял 9,2 %, что стало крупнейшим падением в течение одного дня торгов за всю историю (этот день позже будет назван черным вторником). Позднее падение стабилизировалось, и индекс снизился «всего» на 3,2 %, но в результате за несколько секунд безвозвратно исчезли триллионы долларов.

Первые признаки обвала были обнаружены на Нью-Йоркской фондовой бирже.
Было предложено множество объяснений, но точная причина черного вторника до сих пор неизвестна. Согласно одной из гипотез, которую поддерживает большинство финансовых аналитиков, причиной обвала стала деятельность высокочастотных трейдеров (HFT — от англ. High Frequency Traders), однако рыночные регуляторы традиционно отвергали эту версию. Высокочастотные трейдеры — это автоматические интеллектуальные системы купли-продажи акций и финансовых инструментов, способные принимать решения в течение нескольких микросекунд. Сегодня системами высокочастотной торговли совершается 50 % всех международных финансовых операций.
Но как может информационная система, интеллектуальная или нет, принимать столь масштабные решения так быстро? Любой начинающий инвестор знает, что котировки ценных бумаг на финансовых рынках зависят от бесконечного множества социальных, экономических и политических факторов, начиная от последних заявлений финского министра занятости о регулировании труда в стране и заканчивая непредвиденным снижением спроса на сырье в связи с потеплением на юге Германии. Как может информационная система учитывать такой объем информации, чтобы принимать, казалось бы, интеллектуальные решения о покупке или продаже акций, причем всего за несколько секунд? Вот в чем вопрос.
Машинное обучение — один из главнейших столпов искусственного интеллекта. Мы не осознаем этого, но большинство сценариев, с которыми мы сталкиваемся каждый день, полностью контролируются мыслящими машинами. Но прежде чем начать работу, машины должны пройти обучение.
Пример обучения: диагностика опухолей
Диагностика опухолей — один из примеров, когда искусственный интеллект может оказаться крайне полезным. Прохождение маммографии с целью предотвращения рака груди является (или должно быть) регулярной практикой для взрослых женщин. Маммография — это всего лишь радиография молочных желез, позволяющая распознать аномалии, которые могут быть злокачественными опухолями. Поэтому всякий раз, когда радиолог при маммографии выявляет подобную аномалию, он проводит более подробный анализ, для которого требуется биопсия, или изъятие тканей из организма — намного более дорогостоящая и болезненная процедура, чем маммография.
Положительные результаты биопсии в 10 % случаев оказываются ложными — иными словами, при маммографии обнаруживается аномалия, однако биопсия не показывает никаких следов опухоли. Поэтому врачам крайне важно иметь в своем распоряжении средства, позволяющие свести к минимуму эти 10 % ложноположительных результатов, — чтобы снизить не только расходы на здравоохранение, но и стресс от обследования.
С другой стороны, наблюдаются и ложноотрицательные результаты, когда маммография не показывает никаких аномалий, но у пациента уже развилась опухоль. Крайне важно, чтобы новые средства диагностики позволяли снизить число как ложноположительных, так и ложноотрицательных случаев. Как вы узнаете чуть позже, снизить число ложноотрицательных случаев намного сложнее, чем ложноположительных, при этом последствия ложноотрицательных случаев намного серьезнее.
Представьте, что онколог анализирует результаты маммографии пациента, чтобы определить наличие признаков опухоли. В общем случае он выполняет следующие действия.
1. Анализ результатов маммографии и выявление наиболее важных параметров с целью определения новой проблемы. Множество выявленных параметров позволяет описать сложившуюся ситуацию.
2. Поиск иных результатов маммографии, обладающих похожими свойствами, которые были ранее получены самим врачом или приведены в специальной литературе.
3. Установление диагноза с учетом диагнозов для множества схожих результатов маммографии.
4. Наконец, при необходимости консультация с коллегами для подтверждения диагноза.
3. Запись диагноза в базу для последующего использования в будущем.
Описанная процедура полностью совпадает с одним из самых популярных методов прогнозирования, используемых в искусственном интеллекте, называется он «рассуждение по прецедентам», или CBR (от англ. Case-Based Reasoning). Рассуждение по прецедентам заключается в решении новых задач путем поиска аналогий с уже решенными задачами. После того как выбрано наиболее схожее решение, оно адаптируется к особенностям новой задачи, поэтому рассуждение по прецедентам помогает не только анализировать данные, но и достигать более общей цели — интеллектуального решения задач на основе анализа данных.