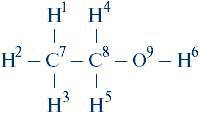Рассматриваются три аспекта их действия. Так, по фармакологическому эффекту все препараты можно подразделить на 217 групп; алфавитный их перечень возглавляют «Агрегации тромбоцитов активаторы», замыкают – «эритропоэза стимуляторы», а между ними находим «антидепрессанты», «жажды стимуляторы», «противобактериальные», «снотворные» и т.д. Некоторые группы подразделяются на более мелкие, например, «противокашлевые» на «противокашлевые наркотические» и «противокашлевые ненаркотические»; все три входят в число упомянутых 217.
Другой способ классификации – по механизмам биологического действия: «аденилатциклазы активаторы», «гормонов антагонисты»... «серотонинподобные»... и так далее, вплоть до трудночитаемого «UDP-N-ацетилглюкозамингликопротеид N-ацетилглюкозами-нилтрансферазы ингибиторы»; всего 309 групп. Преобладают активаторы и ингибиторы различных ферментов.
Наконец, принята и классификация по месту действия (168 групп): «вестибулярный аппарат», «железы слюнные», «мозг спинной», «протопласт бактерий»... «ухо»... «яйца насекомых». С помощью такого словаря-систематики тем самым определено, какие виды биологической активности вообще существуют. Комбинируя термины, входящие в три описанных перечня, можно определять более узкие группы проявлений биологической активности. Например, сосудорасширяющие препараты – это те, которые принадлежат одновременно группе «спазмолитики» первого перечня и «гладкая мускулатура артерий» третьего перечня.
Очевидно, предполагается, что по мере накопления новых данных тезаурус будет систематически пополняться и видоизменяться.
При разработке языка для описания структуры химического соединения приходится сталкиваться с проблемами совсем иного рода.
Уж формулы как будто чуть ли не сами должны лезть в ЭВМ. Они-то, ЭВМ, в конце концов, и созданы для восприятия формул: один из наиболее популярных языков программирования – фортран образует свое название от английского FORmula TRANslation – «перевод формул».
К сожалению, речь идет вовсе не о структурных формулах, употребляемых в химии. То есть, конечно, можно в конце концов заставить ЭВМ работать и с такими формулами, но для этого понадобится создать соответствующий язык.
Таких языков было предложено несколько – в зависимости от особенностей задач, которые предстояло решать.
Какую информацию нужно ввести в машину для того, чтобы однозначно описать структуру какого-либо соединения? Пусть это будет, скажем, молекула этилового спирта.
Во-первых, должен быть дан перечень образующих ее атомов; пронумеруем их каким-нибудь образом. Например, номера (индексы) от 1 до 6 присвоим атомам водорода, 7 и 8 – углерода, 9 – кислорода:
Во-вторых, перечислим существующие в молекуле валентные связи; это можно сделать, указав пары индексов атомов, между которыми такие связи существуют: (1,7), (2,7), (3,7), (4,8), (5,8), (6,9), (7,8), (8,9). В рассмотренной молекуле этанола все связи одинарные; при необходимости можно, однако, привести отдельные наборы пар индексов, которые определяют положение одинарных, двойных, тройных связей.
Вот, казалось бы, и вся премудрость. Действительно, информация, представленная в такой форме, четко и однозначно описывает именно структуру молекулы этилового спирта. Беда, однако, в том, что такое описание может быть осуществлено очень многими способами. В самом деле, мы произвели нумерацию атомов в молекуле совершенно произвольным образом: сначала пронумеровали все атомы водорода, затем – углерода и кислорода. Но ведь ничто не мешает пронумеровать их в обратной последовательности, или по мере перемещения от одного конца молекулы к другому, или еще каким-нибудь образом. Каждый раз мы получим точное описание именно молекулы этанола; все такие описания будут совершенно эквивалентны.
Таким образом, каждая структурная формула может быть записана в ЭВМ многими, часто очень многими способами. Нетрудно даже было бы выписать пару формул с несколько устрашающим обилием факториалов, но не станем этого делать. Достаточно сказать, что для сравнительно немудреной и скромной по размерам молекулы этанола это число составит около четырех тысяч.
Если, таким образом, попытаться теперь составить словарь описанного нового языка – точнее, русско-«новоязычный» словарь, против русского термина «этанол» оказалось бы четыре тысячи синонимов, причем синонимов совершенно равнозначных, не различающихся никакими смысловыми оттенками в отличие от того, как это обычно бывает в «настоящих» языках.
Нечего и говорить о том, сколь неудобен в работе такой словарь; а ведь избранная нами в качестве примера молекула этанола – одна из простейших органических молекул; число же синонимов в принятом нами описании лавинообразно растет с увеличением размеров молекулы. Уже для знакомой нам пальмитиновой кислоты, тоже далеко не чемпиона по размерам и сложности строения среди интересующих нас соединений, выписать все синонимы просто нет технической возможности; для этого понадобилось бы гораздо больше бумаги, чем ее произведено за всю историю человечества.
По счастью, в составлении подобных словарей нет нужды, хотя отмеченная особенность рассмотренного языка описания химических структур создает немалые трудности при его использовании в процедурах прогнозирования биологической активности химических соединений по их формуле.
Пример из детского сада
Их разработано очень много, этих процедур, и сами авторы обычно признают, что все они весьма, весьма далеки от совершенства. При этом имеются в виду два обстоятельства: сравнительно невысокая надежность получаемых предсказаний и чисто эмпирический характер, отсутствие в применяемых алгоритмах явных представлений о конкретных молекулярных механизмах, лежащих в основе того или иного вида биологической активности.
В третьей главе были, правда, вкратце рассмотрены подходы, базирующиеся именно на таких представлениях, изучающие требования, предъявляемые рецептором к пространственной структуре молекулы биологически активного соединения, взаимодействие отдельных функциональных групп рецептора и биорегулятора и т.п. Однако работы этого направления лишь самые, самые первые ласточки. Они касаются очень немногих, очень узких групп аналогов природных биорегуляторов, для которых в силу благоприятного стечения обстоятельств вообще оказалось возможным применение таких аналитических приемов (как говорят: «ищем не там, где потеряли, а там, где светло»). Да и надежность получаемых при этом оценок также далеко не стопроцентная.
Область применения эмпирических процедур анализа связи «структура – активность» (или, как часто говорят, структурно-функциональных отношений) – вещества сравнительно простые, состоящие из десятков атомов. Это и понятно, поскольку все такие процедуры – вероятностные, основанные на соотнесении каких-то характерных признаков молекулы, степени выраженности ее биологической активности в какой-то тестовой системе. Чем крупнее молекула, тем большим числом признаков она характеризуется. Значительная их часть окажется при этом несущественной с точки зрения наличия или отсутствия данного вида биологической активности, а для выявления в этой ситуации немногих существенных признаков нужны данные об активности очень большого числа сходных по структуре молекул. На самом деле все обстоит как раз наоборот: сведений, относящихся к более сложным молекулам, относительно мало, хотя бы потому просто, что их труднее синтезировать.
Впрочем, это уже начался разговор о сути методов анализа связи «структура – активность».
Для реализации подавляющего большинства таких методов необходимо, однако, решить еще одну техническую проблему: создать банки данных по биологическим активностям химических соединений. Это наиболее сложная часть подготовительного этапа, очень трудоемкая и дорогостоящая. Нужно «перевести» на принятые языки сведения о структуре вещества, его биологической активности, для многих процедур требуются еще и данные о физико-химических свойствах. Все эти данные вводятся в память ЭВМ; для организации их размещения и последующего извлечения для обработки создаются специальные пакеты программ.