В деревьях решений прунинг может быть осуществлен путем удаления узлов или поддеревьев, которые вносят малый вклад в точность модели или создают слишком сложные структуры. Может быть применен как во время построения дерева (преждевременный прунинг), так и после его построения (отсроченный прунинг). Применение прунинга помогает снизить вероятность переобучения, улучшая обобщающую способность дерева.
Итак, и регуляризация, и прунинг являются техниками для упрощения моделей машинного обучения и предотвращения переобучения, но они применяются к разным типам моделей и используют разные подходы.
Интерпретируемость: Многие традиционные методы машинного обучения, такие как линейные модели или деревья решений, являются интерпретируемыми, что означает, что их результаты и принципы работы легче объяснить и понять. Нейронные сети, особенно глубокие сети, часто считаются "черными ящиками" из-за их сложной структуры и большого количества параметров, что затрудняет интерпретацию их предсказаний.
В целом, выбор между методами машинного обучения и нейронными сетями зависит от специфики задачи, доступных данных, вычислительных ресурсов и требований к интерпретируемости модели. В некоторых случаях использование нейронных сетей может привести к значительному улучшению результатов, в то время как в других случаях традиционные методы машинного обучения могут быть более подходящими и эффективными.
Статистический анализ данных и методы машинного обучения
Методы машинного обучения и статистический анализ являются инструментами для изучения и анализа данных, и выбор между ними зависит от конкретной задачи, целей и доступных данных. Вот несколько примеров, когда стоит использовать машинное обучение или статистический анализ:
Использование статистического анализа:
Описательная статистика: Если вам нужно просто описать основные характеристики данных, такие как среднее, медиана, стандартное отклонение и т. д., статистический анализ может быть достаточным.
Исследование взаимосвязей: Если цель состоит в изучении взаимосвязи между переменными и выявлении статистически значимых связей, такие методы, как корреляционный анализ или регрессионный анализ, могут быть подходящими.
Тестирование гипотез: В случае, когда вам нужно проверить определенную гипотезу о данных, такую как сравнение средних значений двух групп, статистические тесты могут быть использованы для этой цели.
Использование машинного обучения
Прогнозирование: Если задачей является прогнозирование значений одной переменной на основе других переменных, машинное обучение может обеспечить более точные и надежные прогнозы по сравнению со статистическими методами.
Классификация и кластеризация: Если вам нужно разделить данные на группы на основе их характеристик или выявить скрытые закономерности в данных, методы машинного обучения, такие как деревья решений, случайный лес, k-средних и другие, могут быть подходящими.
Работа с большими данными: Если у вас есть большие объемы данных или данные с большим количеством признаков, машинное обучение может быть более подходящим инструментом для анализа данных, поскольку оно способно обрабатывать такие данные и выявлять сложные закономерности.
Важно отметить, что статистический анализ и машинное обучение не взаимоисключающие подходы. На практике они часто используются совместно для анализа данных, и один подход может дополнять другой. Например, статистический анализ может быть использован на начальном этапе проекта для получения базового понимания данных и выявления потенциальных связей между переменными. Затем машинное обучение может быть применено для создания более сложных моделей и прогнозов.
В некоторых случаях, когда данные содержат линейные зависимости, и задача не требует высокой точности прогнозирования, можно использовать статистические методы, такие как линейная регрессия. Однако, если данные имеют сложные нелинейные зависимости или если требуется высокая точность прогнозов, машинное обучение может быть более подходящим инструментом.
В целом, выбор между статистическим анализом и машинным обучением зависит от специфики задачи, доступных данных и целей исследования. Важно помнить, что эти подходы могут дополнять друг друга и быть использованы совместно для достижения лучших результатов.
Задачи, решаемые с помощью анализа табличных данных
Анализ табличных данных с использованием машинного обучения позволяет решать различные задачи, такие как:
Регрессия – предсказание непрерывной переменной на основе входных данных.
Примеры: прогнозирование цен на жилье, автомобилей или акций и т.п.
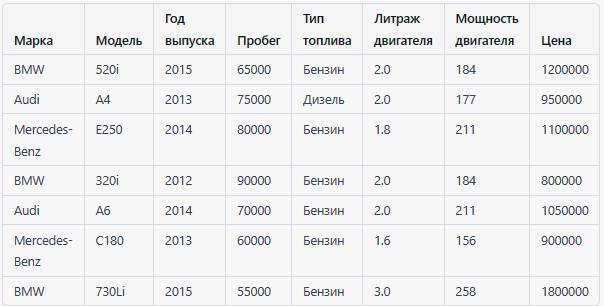
Вот пример табличных данных, используемых для регрессии цен на автомобили:
В этом примере каждая строка представляет автомобиль, а столбцы содержат информацию о его марке, модели, годе выпуска, пробеге, типе топлива, литраже двигателя, мощности двигателя и цене.
Цель – предсказать цену автомобиля на основе его характеристик, например, для оценки стоимости при продаже или покупке. Эти данные могут быть использованы для создания модели машинного обучения, которая автоматически предсказывает цену автомобиля на основе его характеристик.
Классификация – определение категории или класса объекта на основе входных данных.
Примеры: определение кредитного риска, диагностика заболеваний или фильтрация спама.
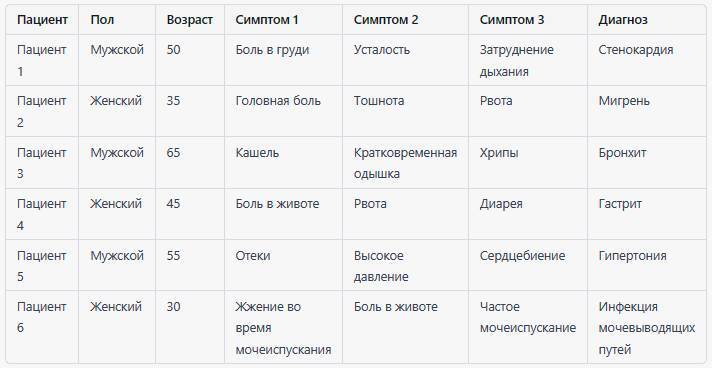
Вот пример табличных данных, используемых для классификации диагнозов пациентов:
В этом примере каждая строка представляет пациента, а столбцы содержат информацию о его поле, возрасте, симптомах и диагнозе.
Цель – определить диагноз пациента на основе симптомов, например, для правильного назначения лечения. Эти данные могут быть использованы для создания модели машинного обучения, которая автоматически классифицирует диагноз пациента на основе его симптомов.
Кластеризация – группировка объектов на основе их схожести или близости друг к другу.
Примеры: сегментация клиентов, выявление аномалий в данных и т.п.
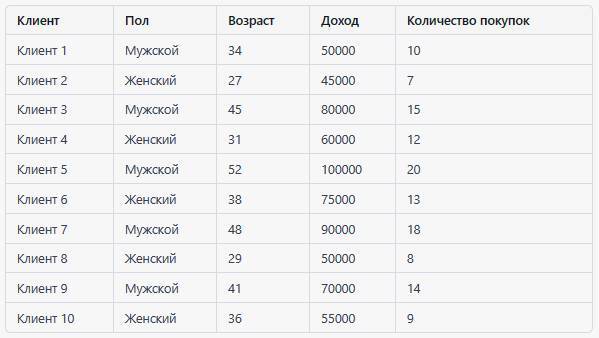
Вот пример табличных данных, используемых для кластеризации клиентов:
В этом примере каждая строка представляет клиента, а столбцы содержат информацию о его поле, возрасте, доходе и количестве покупок.
Цель – разбить клиентов на группы на основе их схожести, например, для улучшения маркетинговых кампаний или персонализированного обслуживания. Эти данные могут быть использованы для создания модели машинного обучения, которая автоматически разбивает клиентов на группы (кластеры) на основе их характеристик.
Ранжирование – упорядочивание объектов по определенному критерию или степени предпочтения.
Примеры: рекомендательные системы, поисковые движки или оценка релевантности рекламы.
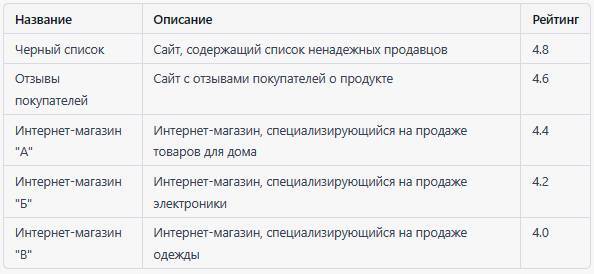
Вот пример табличных данных, используемых для ранжирования результатов поиска:
В этом примере каждая строка представляет собой результат поиска, а столбцы содержат информацию о названии, описании и рейтинге соответствующего результата.
Цель – упорядочить результаты поиска по убыванию рейтинга, чтобы пользователю было легче найти наиболее релевантные результаты. Эти данные могут быть использованы для создания модели машинного обучения, которая автоматически ранжирует результаты поиска на основе описания и рейтинга.