class exception {
public:
exception();
exception(const exception&);
exception& operator=(const exception&);
virtual ~exception();
virtual const char* what() const;
};
Функцию
what()
можно использовать для того, чтобы получить строку, предназначенную для представления информации об ошибки, вызвавшей исключение.
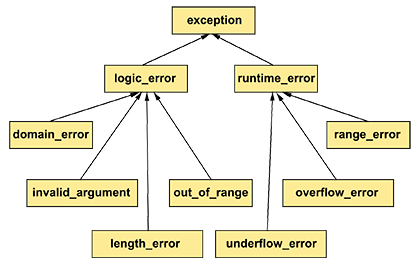
Приведенная ниже иерархия стандартных исключений может помочь вам классифицировать исключения.
Можете определить исключение, выведя его из стандартного библиотечного исключения следующим образом:
struct My_error:runtime_error {
My_error(int x):interesting_value(x) { }
int interesting_value;
const char* what() const { return "My_error"; }
};
Б.3. Итераторы
Итераторы — это клей, скрепляющий алгоритмы стандартной библиотеки с их данными. Итераторы можно также назвать механизмом, минимизирующим зависимость алгоритмов от структуры данных, которыми они оперируют (см. раздел 20.3).
Б.3.1. Модель итераторов
Итератор — это аналог указателя, в котором реализованы операции косвенного доступа (например, оператор
*
для разыменования) и перехода к новому элементу (например, оператор
++
для перехода к следующему элементу). Последовательность элементов определяется парой итераторов, задающих полуоткрытый диапазон
[begin:end]
.
Иначе говоря, итератор
begin
указывает на первый элемент последовательности, а итератор
end
— на элемент, следующий за последним элементом последовательности. Никогда не считывайте и не записывайте значение
*end
. Для пустой последовательности всегда выполняется условие
begin==end
. Другими словами, для любого итератора p последовательность
[p:p]
является пустой.
Для того чтобы считать последовательность, алгоритм обычно получает пару итераторов (
b, e
) и перемещается по элементам с помощью оператора
++
, пока не достигнет конца.
while (b!=e) { // используйте !=, а не <
// какие-то операции
++b; // переходим к последнему элементу
}
Алгоритмы, выполняющие поиск элемента в последовательности, в случае неудачи обычно возвращают итератор, установленный на конец последовательности. Рассмотрим пример.
p = find(v.begin(),v.end(),x); // ищем x в последовательности v
if (p!=v.end()) {
// x найден в ячейке p
}
else {
// x не найден в диапазоне [v.begin():v.end())
}
См. раздел 20.3.
Алгоритмы, записывающие элементы последовательности, часто получают только итератор, установленный на ее первый элемент. В данном случае программист должен сам предотвратить выход за пределы этой последовательности. Рассмотрим пример.
template<class Iter> void f(Iter p, int n)
{
while (n>0) *p++ = ––n;
vector<int> v(10);
f(v.begin(),v.size()); // OK
f(v.begin(),1000); // большая проблема
Некоторые реализации стандартной библиотеки проверяют выход за пределы допустимого диапазона, т.е. генерируют исключение, при последнем вызове функции
f()
, но этот код нельзя считать переносимым; многие реализации эту проверку не проводят.
Перечислим операции над итераторами.
Обратите внимание на то, что не каждый вид итераторов (раздел Б.3.2) поддерживает все операции над итераторами.
Б.3.2. Категории итераторов
В стандартной библиотеке предусмотрены пять видов итераторов.
С логической точки зрения итераторы образуют иерархию (см. раздел 20.10).
Поскольку категории итераторов не являются классами, эту иерархию нельзя считать иерархией классов, реализованной с помощью наследования. Если вам требуется выполнить над итераторами нетривиальное действие, поищите класс
iterator_traits
в профессиональном справочнике.
Каждый контейнер имеет собственные итераторы конкретной категории:
•
vector
— итераторы произвольного доступа;
•
list
— двунаправленные итераторы;
•
deque
— итераторы произвольного доступа;
•
bitset
— итераторов нет;
•
set
— двунаправленные итераторы;
•
multiset
— двунаправленные итераторы;
•
map
— двунаправленные итераторы;
•
multimap
— двунаправленные итераторы;
•
unordered_set
— однонаправленные итераторы;
•
unordered_multiset
— однонаправленные итераторы;
•
unordered_map
— однонаправленные итераторы;
•
unordered_multimap
— однонаправленные итераторы.