// получаем извне шаблон и набор строк
// проверяем шаблон и ищем строки, содержащие этот шаблон
int main()
{
regex pattern;
string pat;
cout << "введите шаблон: ";
getline(cin,pat); // считываем шаблон
try {
pattern = pat; // проверка шаблона
cout << "Шаблон: " << pattern << '\n';
}
catch (bad_expression) {
cout << pat
<< "Не является корректным регулярным выражением\n";
exit(1);
}
cout << "Введите строки:\n";
string line; // входной буфер
int lineno = 0;
while (getline(cin,line)) {
++lineno;
smatch matches;
if (regex_search(line, matches, pattern)) {
cout << " строка " << lineno << ": " << line << '\n';
for (int i = 0; i<matches.size(); ++i)
cout << "\tmatches[" << i << "]: "
<< matches[i] << '\n';
}
else
cout << "не соответствует \n";
}
}
ПОПРОБУЙТЕ
Запустите эту программу и попробуйте применить ее для проверки нескольких шаблонов, например abc, x.*x, ( .* ), \([^)]*\) и \ w+\w+(Jr\.) ?.
23.9. Сравнение регулярных выражений
Регулярные выражения в основном используются в двух ситуациях.
• Поиск строки, соответствующей регулярному выражению в (произвольно длинном) потоке данных, — функция
regex_search()
ищет этот шаблон как подстроку в потоке.
• Сравнение регулярного выражения со строкой (заданного размера) — функция
regex_match()
ищет полное соответствие шаблона и строки.
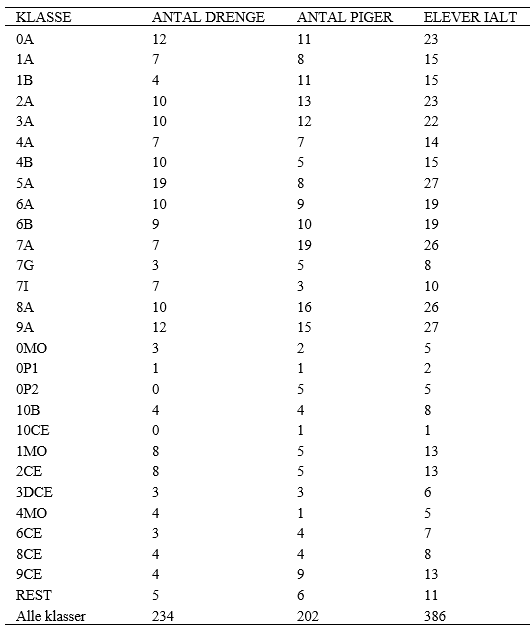
Одним из примеров является поиск почтовых индексов в разделе 23.6. Рассмотрим извлечение данных из следующей таблицы.
Эта совершенно типичная и не очень сложная таблица (количество учеников в 2007 году в средней школе, в которой учился Бьярне Страуструп) извлечена с веб страницы, на которой она выглядела именно так, как нам нужно.
• Содержит числовые поля.
• Содержит символьные поля в строках, понятных только людям, знающим контекст, из которого извлечена таблица. (В данном случае ее могут понять только люди, знающие датский язык.)
• Символьные строки содержат пробелы.
• Поля отделены друг от друга разделителем, роль которого в данном случае играет символ табуляции.
Мы назвали эту таблицу совершенно типичной и не очень сложной, но следует иметь в виду, что одна тонкость в ней все же скрывается: на самом деле мы не можем различить пробелы и знаки табуляции; эту проблему читателям придется устранить самостоятельно.
Проиллюстрируем использование регулярных выражения для решения следующих задач.
• Убедимся, что таблица сформирована правильно (т.е. каждая строка имеет правильное количество полей).
• Убедимся, что суммы подсчитаны правильно (в последней строке содержатся суммы чисел по столбцам).
Если мы сможем это сделать, то сможем сделать почти все! Например, мы смогли бы создать новую таблицу, в которой строки, имеющие одинаковые первые цифры (например, годы: первый класс должен иметь номер 1), объединены или проверить, увеличивается или уменьшается количество студентов с годами (см. упр. 10-11).
Для того чтобы проанализировать эту таблицу, нам нужны два шаблона: для заголовка и для остальных строк.
regex header( "^[\\w ]+( [\\w ]+)*$");
regex row( "^[\\w ]+(\\d+)(\\d+)(\\d+)$");
Помните, мы хвалили синтаксис регулярных выражений за лаконичность и полезность, а не за легкость освоения новичками? На самом деле регулярные выражения имеют заслуженную репутацию языка только для письма (write-only language). Начнем с заголовка. Поскольку он не содержит никаких числовых данных, мы могли бы просто отбросить первую строку, но — исключительно для приобретения опыта — попробуем провести ее структурный анализ. Она содержит четыре словарных поля (буквенно-цифровых поля”, разделенных знаками табуляции). Эти поля могут содержать пробелы, поэтому мы не можем просто использовать управляющий символ
\w
, чтобы задать эти символы. Вместо этого мы используем выражение
[\w]
, т.е. словообразующий символ (букву, цифру или знак подчеркивания) или пробел. Один или несколько словообразующих символов задается выражением
[\w]+
. Мы хотим найти тот из них, который стоит в начале строки, поэтому пишем выражение
^[\w ]+
. “Шапочка” (
^
) означает “начало строки”. Каждое из оставшихся полей можно выразить как знак табуляции, за которым следуют некие слова:
([\w]+)
. До конца строки их может быть сколько угодно:
([\w]+)*$
. Знак доллара (
$
) означает “конец строки”. Теперь напишем строковый литерал на языке C++ и получим дополнительные обратные косые черты.
"^[\\w ]+( [\\w ]+)*$"