Следует подчеркнуть, что реализации функций
to_string()
и
from_string()
используют класс
stringstream
для выполнения всей работы. Это наблюдение было использовано для определения универсальной операции конвертирования двух произвольных типов с согласованными операциями
<<
и
>>
.
struct bad_lexical_cast:std::bad_cast
{
const char* what() const { return "bad cast"; }
};
template<typename Target,typename Source>
Target lexical_cast(Source arg)
{
std::stringstream interpreter;
Target result;
if (!(interpreter << arg) // записываем arg в поток
|| !(interpreter >> result) // считываем result из потока
|| !(interpreter >> std::ws).eof()) // поток пуст?
throw bad_lexical_cast();
return result;
}
Довольно забавно и остроумно, что инструкция
!(interpreter>>std::ws).eof()
считывает любой пробел, который может остаться в потоке
stringstream
после извлечения результата. Пробелы допускаются, но кроме них в потоке ввода может не остаться никаких других символов, и мы должны реагировать на эту ситуацию, как на обнаружение конца файла. Итак, если мы пытаемся считать целое число
int
из объекта класса
string
, используя класс
lexical_cast
, то в результате выражения
lexical_cast<int>("123")
и
lexical_cast<int>("123")
будут считаться допустимыми, а выражение
lexical_cast<int>("123.5")
— нет из-за последней пятерки.
Довольно элегантное, хотя и странное, имя
lexical_cast
используется в библиотеке
boost
, которую мы будем использовать для сравнения регулярных выражений в разделах 23.6–23.9. В будущем она станет частью новых версий стандарта языка С++ .
23.3. Потоки ввода-вывода
Рассматривая связь между строками и другими типами, мы приходим к потокам ввода-вывода. Библиотека ввода-вывода не просто выполняет ввод и вывод, она осуществляет преобразования между форматами и типами строк в памяти. Стандартные потоки ввода-вывода обеспечивают возможности для чтения, записи и форматирования строк символов. Библиотека
iostream
описана в главах 10-11, поэтому просто подведем итог.
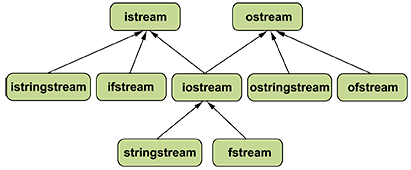
Стандартные потоки организованы в виде иерархии классов (см. раздел 14.3).
В совокупности эти классы дают нам возможность выполнять ввод-вывод, используя файлы и строки (а также все, что выглядит как файлы и строки, например клавиатуру и экран; см. главу 10). Как указано в главах 10-11, потоки
iostream
предоставляют широкие возможности для форматирования. Стрелки на рисунке обозначают наследование (см. раздел 14.3), поэтому, например, класс
stringstream
можно использовать вместо классов
iostream
,
istream
или
ostream
.
Как и строки, потоки ввода-вывода можно применять и к широким наборам данных, и к обычным символам. Снова следует подчеркнуть, что, если вам необходимо работать с вводом-выводом символов Unicode, лучше всего спросить совета у экспертов; для того чтобы стать полезной, ваша программа должна не просто соответствовать правилам языка, но и выполнять определенные системные соглашения.
23.4. Ассоциативные контейнеры
Ассоциативные контейнеры (ассоциативные массивы и хеш-таблицы) играют ключевую роль (каламбур) в обработке текста. Причина проста — когда мы обрабатываем текст, мы собираем информацию, а она часто связана с текстовыми строками, такими как имена, адреса, почтовые индексы, номера карточек социального страхования, место работы и т.д. Даже если некоторые из этих текстовых строк можно преобразовать в числовые значения, часто более удобно и проще обрабатывать их именно как текст и использовать его для идентификации. В этом отношении ярким примером является подсчет слов (см. раздел 21.6). Если вам неудобно работать с классом
map
, пожалуйста, еще раз прочитайте раздел 21.6.
Рассмотрим сообщение электронной почты. Мы часто ищем и анализируем сообщения электронной почты и ее регистрационные записи с помощью какой-то программы (например, Thunderbird или Outlook). Чаще всего эти программы скрывают детали, характеризующие источник сообщения, но вся информация о том, кто его послал, кто получил, через какие узлы оно прошло, и многое другое поступает в программы в виде текста, содержащегося в заголовке письма. Так выглядит полное сообщение. Существуют тысячи инструментов для анализа заголовков. Большинство из них использует регулярные выражения (как описано в разделе 23.5–23.9) для извлечения информации и какие-то разновидности ассоциативных массивов для связывания их с соответствующими сообщениями. Например, мы часто ищем сообщение электронной почты для выделения писем, поступающих от одного и того же отправителя, имеющих одну и ту же тему или содержащих информацию по конкретной теме.
Приведем упрощенный файл электронной почты для демонстрации некоторых методов извлечения данных из текстовых файлов. Заголовки представляют собой реальные заголовки RFC2822 с веб-страницы www.faqs.org/rfcs/rfc2822.html. Рассмотрим пример.
xxx
xxx
––––
From: John Doe <[email protected]>
To: Mary Smith <[email protected]>
Subject: Saying Hello
Date: Fri, 21 Nov 1997 09:55:06 –0600
Message–ID: <[email protected]>
This is a message just to say hello.
So, "Hello".
––––
From: Joe Q. Public <[email protected]>