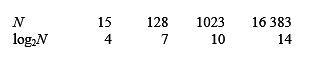// ассоциативного
// массива
cout << "Intel is in the Dow\n";
Перемещаться по ассоциативному массиву легко. Мы просто должны помнить, что ключ называется
first
, а значение —
second
.
typedef map<string,double>::const_iterator Dow_iterator;
// записывает цену акции для каждой компании, входящей в индекс
// Доу - Джонса
for (Dow_iterator p = dow_price.begin(); p!=dow_price.end(); ++p) {
const string& symbol = p–>first; // тикер
cout << symbol << '\t'
<< p–>second << '\t'
<< dow_name[symbol] << '\n';
}
Мы можем даже выполнить некоторые вычисления, непосредственно используя ассоциативный контейнер. В частности, можем вычислить индекс, как в разделе 21.5.3. Мы должны извлечь цены акций и веса из соответствующих ассоциативных массивов и перемножить их. Можно без труда написать функцию, выполняющую эти вычисления с любыми двумя ассоциативными массивами
map<string,double>
.
double weighted_value(
const pair<string,double>& a,
const pair<string,double>& b
) // извлекает значения и перемножает
{
return a.second * b.second;
}
Теперь просто подставим эту функцию в обобщенную версию алгоритма
inner_product() и получим значение индекса.
double dji_index =
inner_product(dow_price.begin(), dow_price.end(),
// все компании
dow_weight.begin(), // их веса
0.0, // начальное значение
plus<double>(), // сложение (обычное)
weighted_value); // извлекает значение и веса,
// а затем перемножает их
Почему целесообразно хранить такие данные в ассоциативных массивах, а не в векторах? Мы использовали класс map, чтобы связь между разными значениями стала явной. Это одна из причин. Кроме того, контейнер
map
хранит элементы в порядке, определенном их ключами. Например, при обходе контейнера
dow
мы выводили символы в алфавитном порядке; если бы мы использовали класс
vector
, то были бы вынуждены сортировать его. Чаще всего класс
map
используют просто потому, что хотят искать значения по их ключам. Для крупных последовательностей поиск элементов с помощью алгоритма
find()
намного медленнее, чем поиск в упорядоченной структуре, такой как контейнер
map
.
ПОПРОБУЙТЕ
Приведите этот пример в рабочее состояние. Затем добавьте несколько компаний по своему выбору и задайте их веса.
21.6.4. Алгоритм unordered_map()
Для того чтобы найти элемент в контейнере
vector
, алгоритм
find()
должен проверить все элементы, начиная с первого и заканчивая искомым или последним элементом вектора. Средняя сложность этого поиска пропорциональна длине вектора (
N); в таком случае говорят, что алгоритм имеет сложность
O(
N).
Для того чтобы найти элемент в контейнере map, оператор индексирования должен проверить все элементы, начиная с корня дерева и заканчивая искомым значением или листом дерева. Средняя сложность этого поиска пропорциональна глубине дерева. Максимальная глубина сбалансированного бинарного дерева, содержащего
N элементов, равна
log2N, а сложность поиска в нем имеет порядок
O(
log2N), т.е. пропорциональна величине
log2N. Это намного лучше, чем
O(
N).
Реальная сложность поиска зависит от того, насколько быстро нам удастся найти искомые значения и какие затраты будут связаны с выполнением операции сравнения и итераций. Обычно следование за указателями (при поиске в контейнере map) несколько сложнее, чем инкрементация указателя (при поиске в контейнере vector с помощью алгоритма
find()
).
Для некоторых типов, особенно для целых чисел и символьных строк, можно достичь еще более высоких результатов поиска, чем при поиске по дереву контейнера
map
. Не вдаваясь в подробности, укажем, что идея заключается в том, что по ключу мы можем вычислить индекс в контейнере
vector
. Этот индекс называется
значением хеш-функции (hash value), а контейнер, в котором используется этот метод, —
хеш-таблицей (hash table). Количество возможных ключей намного больше, чем количество ячеек в хеш-таблице. Например, хеш-функция часто используется для того, чтобы отобразить миллиарды возможных строк в индекс вектора, состоящего из тысячи элементов. Такая задача может оказаться сложной, но ее можно решить. Это особенно полезно при реализации больших контейнеров
map
. Основное преимущество хеш-таблицы заключается в том, что средняя сложность поиска в ней является (почти) постоянной и не зависит от количества ее элементов, т.е. имеет порядок
O(1). Очевидно, что это большое преимущество для крупных ассоциативных массивов, например, содержащих 500 тысяч веб-адресов. Более подробную информацию о хеш-поиске читатели могут найти в документации о контейнере
unordered_map
(доступной в сети веб) или в любом учебнике по структурам данных (ищите в оглавлении
хеш-таблицы и
хеширование).