if (h<*p)
{
high = p;
h = *p;
}
return high;
}
Теперь можно написать следующий код:
double* jack_high = high(jack_data,jack_data+jack_count);
vector<double>& v = *jill_data;
double* jill_high = high(&v[0],&v[0]+v.size());
Он выглядит получше. Мы не ввели слишком много переменных и написали только один цикл (в функции
high()
). Если мы хотим найти наибольший элемент, то можем посмотреть на значения
*jack_high
и
*jill_high
. Рассмотрим пример.
cout << "Максимум Джилл: " << *jill_high
<< "; максимум Джека: " << *jack_high;
Обратите внимание на то, что функция
high()
использует тот факт, что вектор хранит данные в массиве, поэтому мы можем выразить наш алгоритм поиска максимального элемента в терминах указателей, ссылающихся на элементы массива.
ПОПРОБУЙТЕ
В этой маленькой программе мы оставили две потенциально опасные ошибки. Одна из них может вызвать катастрофу, а другая приводит к неправильным ответам, если функция
high()
будет использоваться в других программах. Универсальный прием, который описывается ниже, выявит обе эти ошибки и покажет, как их устранить. Пока просто найдите их и предложите свои способы их исправления.
Функция
high()
решает одну конкретную задачу, поэтому она ограничена следующими условиями.
• Она работает только с массивами. Мы считаем, что элементы объекта класса
vector
хранятся в массиве, но наряду с этим существует множество способов хранения данных, таких как списки и ассоциативные массивы (см. разделы 20.4 и 21.6.1).
• Ее можно применять только к объектам класса
vector
и массивам типа
double
, но не к векторам и массивам с другими типами элементов, например
vector<double*>
и
char[10]
.
• Она находит элемент с максимальным значением, но с этими данными можно выполнить множество других простых вычислений.
Попробуем обеспечить более высокую общность вычислений над нашими наборами данных.
Обратите внимание на то, что, решив выразить алгоритм поиска наибольшего элемента в терминах указателей, мы “случайно” уже обобщили решение задачи: при желании мы можем найти наибольший элемент массива или вектора, но, помимо этого, можем найти максимальный элемент части массива или вектора. Рассмотрим пример.
// ...
vector<double>& v = *jill_data;
double* middle = &v[0]+v.size()/2;
double* high1 = high(&v[0], middle); // максимум первой
// половины
double* high2 = high(middle, &v[0]+v.size()); // максимум второй
// половины
// ...
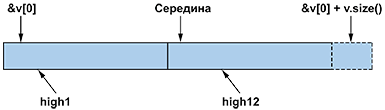
Здесь указатель
high1
ссылается на максимальный элемент первой половины вектора, а указатель
high2
— на максимальный элемент второй половины. Графически это можно изобразить следующим образом:
В качестве аргументов функции
high()
мы использовали указатели. Этот механизм управления памятью относится к слишком низкому уровню и уязвим для ошибок. Мы подозреваем, что большинство программистов для поиска максимального элемента в векторе написали бы нечто вроде следующего:
double* find_highest(vector<double>& v)
{
double h = –1;
double* high = 0;
for (int i=0; i<v.size(); ++i)
if (h<v[i])
{
high = &v[i];
h = v[i];
}
return high;
}
Однако это не обеспечивает достаточно гибкости, которую мы “случайно” уже придали функции
high()
, — мы не можем использовать функцию
find_highest()
для поиска наибольшего элемента в части вектора. На самом деле, “связавшись с указателями”, мы достигли практической выгоды, получив функцию, которая может работать как с векторами, так и с массивами. Помните: обобщение может привести к функциям, которые позволяют решать больше задач.
20.2. Принципы библиотеки STL
Стандартная библиотека языка С++, обеспечивающая основу для работы с данными, представленными в виде последовательности элементов, называется STL. Обычно эту аббревиатуру расшифровывают как “стандартная библиотека шаблонов” (“standard template library”). Библиотека STL является частью стандарта ISO C++. Она содержит контейнеры (такие как классы
vector
,
list
и
map
) и обобщенные алгоритмы (такие как
sort
,
find
и
accumulate
). Следовательно, мы имеем право говорить, что такие инструменты, как класс
vector
, являются как частью библиотеки STL, так и стандартной библиотеки. Другие средства стандартной библиотеки, такие как потоки
ostream
(см. главу 10) и функции для работы строками в стиле языка С (раздел B.10.3), не являются частью библиотеки STL. Чтобы лучше оценить и понять библиотеку STL, сначала рассмотрим проблемы, которые мы должны устранить, работая с данными, а также обсудить идеи их решения.
Существуют два основных вычислительных аспекта: вычисления и данные. Иногда мы сосредоточиваем внимание на вычислениях и говорим об инструкциях
if
, циклах, функциях, обработке ошибок и пр. В других случаях мы фокусируемся на данных и говорим о массивах, векторах, строках, файлах и пр. Однако, для того чтобы выполнить полезную работу, мы должны учитывать оба аспекта. Большой объем данных невозможно понять без анализа, визуализации и поиска “чего-нибудь интересного”. И наоборот, мы можем выполнять вычисления так, как хотим, но такой подход оказывается слишком скучным и “стерильным”, пока мы не получим некие данные, которые свяжут наши вычисления с реальностью. Более того, вычислительная часть программы должна элегантно взаимодействовать с “информационной частью.