Когда используется такая модель, вся входная и выходная информация может рассматриваться как потоки байтов (символы), обрабатываемые средствами библиотеки ввода-вывода. Наша работа как программистов, создающих приложения, сводится к следующему.
1. Настроить потоки ввода-вывода на соответствующие источники и адресаты данных.
2. Прочитать и записать их потоки.
Практические детали передачи символов с устройства и на устройство находятся в компетенции библиотеки ввода-вывода и драйверов устройств. В этой и следующей главах мы увидим, как создать систему ввода-вывода, состоящую из потоков форматированных данных, с помощью стандартной библиотеки языка С++.
С точки зрения программиста существует много разных видов ввода и вывода.
• Потоки (многих) единиц данных (как правило, связанных с файлами, сетевыми соединениями, записывающими устройствами или дисплеями).
• Взаимодействие с пользователем посредством клавиатуры.
• Взаимодействие с пользователем посредством графического интерфейса (вывод объектов, обработка щелчков мыши и т.д.).
Эта классификация не является единственно возможной, а различия между тремя видами ввода-вывода не так отчетливы, как может показаться. Например, если поток вывода символов представляет собой HTTP-документ, адресуемый браузеру, то в результате возникает нечто, очень напоминающее взаимодействие с пользователем и способное содержать графические элементы. И наоборот, результаты взаимодействия посредством пользовательского графического интерфейса можно представить в программе в виде последовательности символов. Однако эта классификация соответствует нашим средствам: первые две разновидности ввода-вывода обеспечиваются стандартными библиотечными потоками ввода-вывода и непосредственно поддерживаются большинством операционных систем. Начиная с главы 1 мы использовали библиотеку
iostream
и будем использовать ее в данной и следующей главах. Графический вывод и взаимодействие с пользователем посредством графического интерфейса обеспечиваются разнообразными библиотеками. Этот вид ввода-вывода мы рассмотрим в главах 12–16.
10.2. Модель потока ввода-вывода
Стандартная библиотека языка С++ содержит определение типов
istream
для потоков ввода и
ostream
— для потоков вывода. В наших программах мы использовали стандартный поток
istream
с именем
cin
и стандартный поток
ostream
с именем
cout
, поэтому эта часть стандартной библиотеки (которую часто называют библиотекой
iostream
) нам уже в принципе знакома.
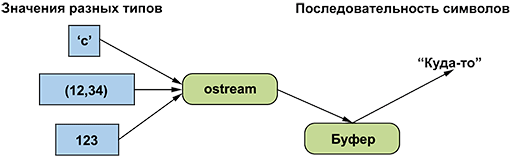
Поток
ostream
делает следующее.
• Превращает значения разных типов в последовательности символов.
• Посылает эти символы “куда-то” (например, на консоль, в файл, основную память или на другой компьютер).
Поток
ostream
можно изобразить следующим образом.
Буфер — это структура данных, которую поток
ostream
использует для хранения информации, полученной от вас в ходе взаимодействия с операционной системой. Задержка между записью в поток
ostream
и появлением символов в пункте назначения обычно объясняется тем, что эти символы находятся в буфере. Буферизация важна для производительности программы, а производительность программы важна при обработке больших объемов данных.
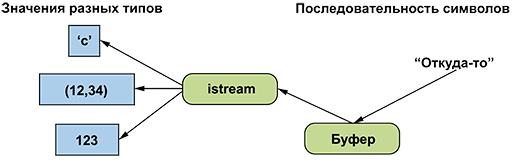
Поток
istream
делает следующее.
• Превращает последовательности символов в значения разных типов.
• Получает эти символы “откуда-то” (например, с консоли, из файла, из основной памяти или от другого компьютера).
Поток
istream
можно изобразить следующим образом.
Как и поток
ostream
, для взаимодействия с операционной системой поток
istream
использует буфер. При этом буферизация может оказаться визуально заметной для пользователя. Когда вы используете поток
istream
, связанный с клавиатурой, все, что вы введете, останется в буфере, пока вы не нажмете клавишу <Enter> (ввести и перейти на новую строку), и если вы передумали, то можете стереть символы с помощью клавиши <Backspace> (пока не нажали клавишу <Enter>).
Одно из основных применений вывода — организация данных для чтения, доступного людям. Вспомните о сообщениях электронной почты, академических статьях, веб-страницах, счетах, деловых отчетах, списках контактов, оглавлениях, показаниях датчиков состояния устройств и т.д. Потоки
ostream
предоставляют много возможностей для форматирования текста по вкусу пользователей. Аналогично, большая часть входной информации записывается людьми или форматируется так, чтоб люди могли ее прочитать. Потоки
istream
обеспечивают возможности для чтения данных, созданных потоками
ostream
. Вопросы, связанные с форматированием, будут рассмотрены в разделе 11.2, а ввод информации, отличающейся от символов, — в разделе 11.3.2. В основном сложность, связанная с вводом данных, обусловлена обработкой ошибок. Для того чтобы привести более реалистичные примеры, начнем с обсуждения того, как модель потоков ввода-вывода связывает файлы с данными.
10.3. Файлы
Обычно мы имеем намного больше данных, чем способна вместить основная память нашего компьютера, поэтому большая часть информации хранится на дисках или других средствах хранения данных высокой емкости. Такие устройства также предотвращают исчезновение данных при выключении компьютера — такие данные являются персистентными. На самом нижнем уровне файл просто представляет собой последовательность байтов, пронумерованных начиная с нуля.

Файл имеет формат; иначе говоря, набор правил, определяющих смысл байтов. Например, если файл является текстовым, то первые четыре байта представляют собой первые четыре символа. С другой стороны, если файл хранит бинарное представление целых чисел, то первые четыре байта используются для бинарного представления первого целого числа (раздел 11.3.2). Формат по отношению к файлам на диске играет ту же роль, что и типы по отношению к объектам в основной памяти. Мы можем приписать битам, записанным в файле, определенный смысл тогда и только тогда, когда известен его формат (разделы 11.2 и 11.3).
При работе с файлами поток
ostream
преобразует объекты, хранящиеся в основной памяти, в потоки байтов и записывает их на диск. Поток
istream
действует наоборот; иначе говоря, он считывает поток байтов с диска и составляет из них объект.