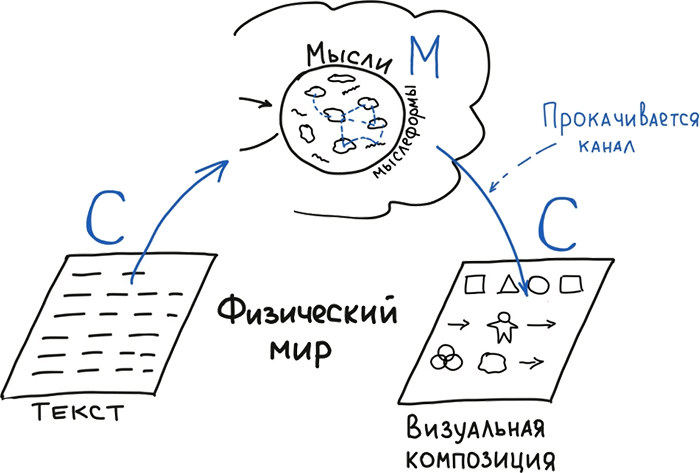
Таким образом, со временем отрезок МС в модели КМС так прокачивается, что у вас не возникает сложностей с прямым переводом мыслей в образы.
Конечно, остаётся вопрос: «Как при тренировке от поля смыслов переходить к образам и визуальной композиции?»
Именно ответу на этот вопрос и посвящены вторая и третья главы книги. Конечно, тренировка мышления непростой процесс. Чтобы его облегчить, мы будем изучать и использовать самые простые приёмы прокачки навыков. И быстро начнём тренироваться применять полученные знания на практике.
1.4. Визуальная система человека и перевод смыслов в визуальные образы
Для работы с визуальными образами разберёмся с тем, как функционирует визуальная система человека. Под визуальной системой будем понимать глаза и мозг человека. Т. е. ответим на вопрос: «Как наши глаза воспринимают мир и как визуальная информация обрабатывается мозгом?»
Здесь я сошлюсь на книгу Дэна Роэма «Визуальное мышление». В книге он со ссылками на научные исследования поясняет, как наша визуальная система считывает, распознаёт и анализирует визуальные образы.
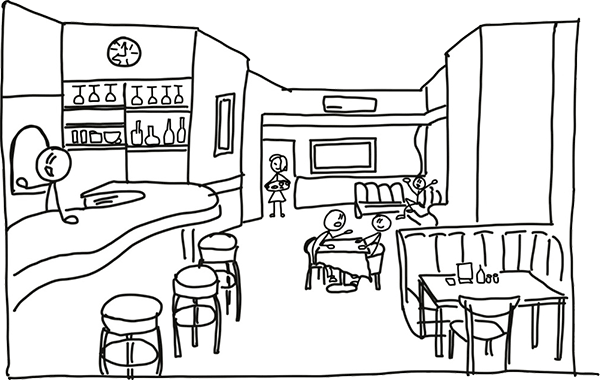
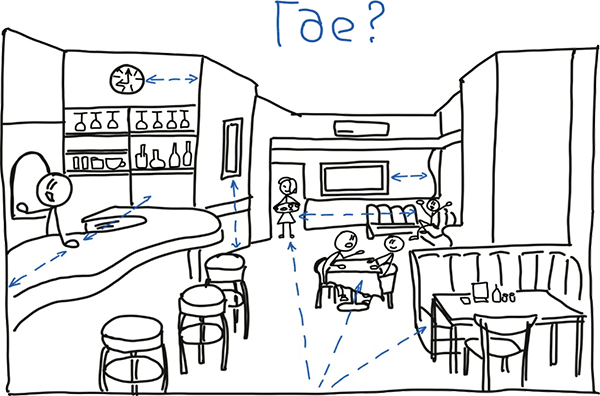
Кратко поясню на примере алгоритм работы нашей визуальной системы, описанный Роэмом. Представьте, что вы пришли в кафе, стоите на входе и анализируете обстановку кафе, нарисованную на картинке ниже.
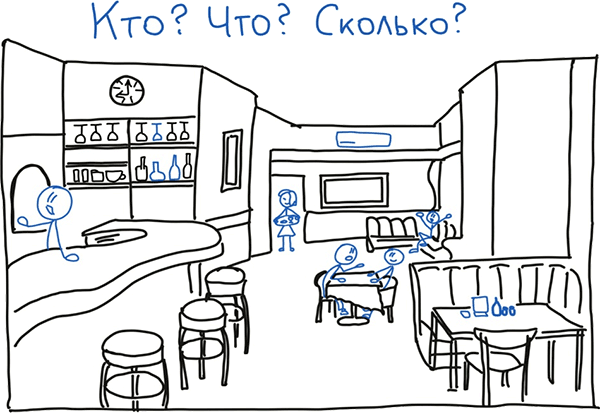
Так вот, ваша визуальная система сначала мгновенно распознаёт и выделяет отдельные объекты и их количество. На каком расстоянии они находятся от нас и между собой. Идентифицирует бармена, бутылки в баре официантку, кондиционер, элементы интерьера и посетителей. Определяет, что бармен находится ближе к нам, чем официантка, что некоторые посетители сидят рядом, а некоторые отдельно и в одиночестве.
Т.е. наша визуальная система как бы отвечает на вопросы «Кто/Что?» здесь находится, «Сколько?» объектов и «Где?» они расположены.
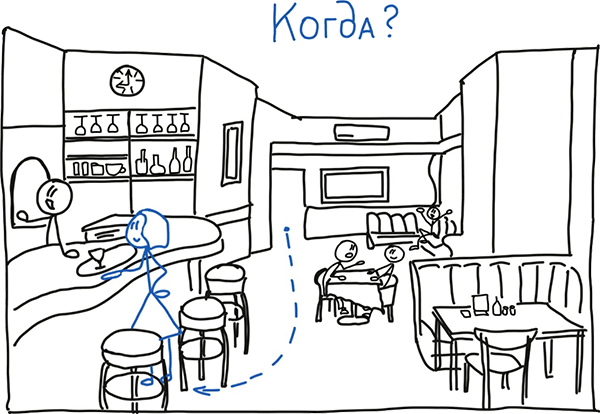
Естественно, мы этого не осознаём, и это происходит мгновенно. Эти три группы вопросов оценивают картинку в статике. Если в нашем баре начинается каким-то образом изменяться обстановка, например, официантка начинает передвигаться, то для анализа динамики в нашей визуальной системе появляется вопрос «Когда?».
Интересно, что для распознавания разных категорий объектов или, по-другому, – ответа на разные вопросы, задействуются разные участки мозга. Но сейчас не будем углубляться в это. Главное на этом этапе понимать, что визуальная система сначала всегда «отвечает» на вопросы «Кто/Что?», «Сколько?», «Где?» и только потом может оценивать последовательность действий (перемещений официантки в пространстве) и отвечает на вопрос «Когда?».
Предположим, ситуация дальше будут развиваться стандартно – официантка принесёт заказ и удалится. Тогда наша визуальная система так и останется в режиме анализа – «Когда?».
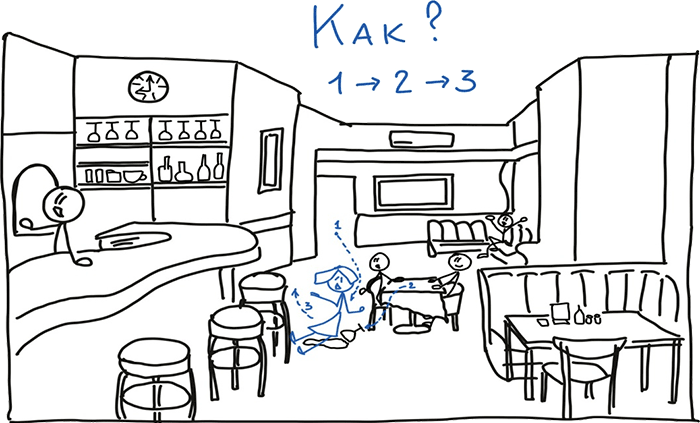
Но если произойдёт нестандартная ситуация, визуальная система активизируется и будет анализировать ситуацию через вопросы «Как?/Почему?» это произошло. Представим, что какой-то посетитель разлил сок, официантка поскользнулась и упала. Т. е. произошла некоторая цепочка действий, которая привела к нестандартной ситуации.
Получается, что наша визуальная система анализирует (осмысливает) визуальную ситуацию, отвечая на шесть групп вопросов. Но и окружающий нас абстрактный мир мы также осмысливаем через задавание вопросов.
И, на мой взгляд, гениальность модели Дэна Роэма как раз и состоит в том, что он связал смысловые вопросы с визуальными образами, которые лучше подходят для ответа на эти вопросы в визуальном виде.
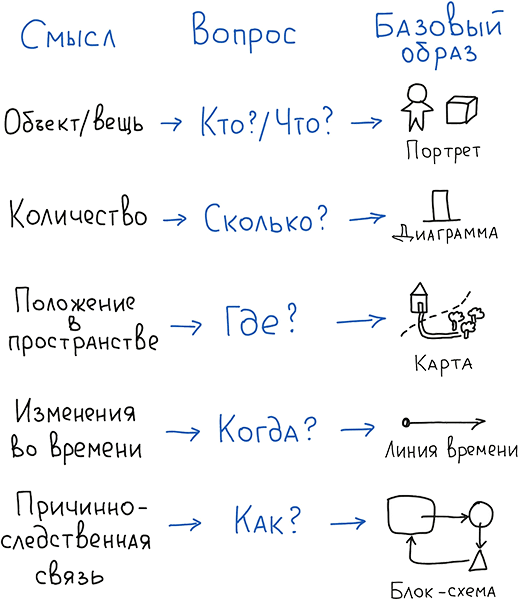
Он назвал свою модель 6W по числу групп вопросов, в английском языке все эти вопросы начинаются с W. К каждому вопросу подобрал базовый смысл и базовый визуальный образ.
Для вопросов «Кто?/Что?» базовый смысл – объект (вещь), а базовый визуальный образ – Портрет.
При ответе на вопрос «Сколько?» базовый смысл – количество, базовый образ – Диаграмма.
Мы отвечаем на вопрос «Где?», когда анализируем пространственную или концептуальную связь объектов. И в качестве базового образа можно использовать Карту.
Чтобы понять причинно-следственную цепочку каких-то действий, мы отвечаем вопрос «Как?» и базовый образ здесь – Блок-схема.
Дэн в отдельную категорию выделяет вопросы «Зачем?/Почему?». Но на практике при обучении людей я не смог чётко отделить и объяснить разницу между «Как?» и «Почему?». На мой взгляд, они оба используются для анализа причинно-следственных цепочек действий, которые приводят к какому-то результату. Дэн при ответе на вопрос «Зачем?/Почему» предлагает в качестве базового образа Уравнение.
Моя практика показала, что при ответе на вопрос «Зачем?/Почему?» всегда рисуется какая-то сложная картинка (визуальная композиция), совмещающая в себе разные вопросы. Поэтому в книге я буду ссылаться на эту модель в варианте 5W. И далее мы подробно рассмотрим каждую категорию вопросов и варианты применения связки смысл – вопрос – образ на практике. Вопросы первого уровня «Кто?/Что?» и «Сколько?» пригодятся при формировании визуального словаря. Вопросы второго уровня «Где?», «Когда?» и «Как?» помогут при сборке визуальных композиций.
2. Готовим визуальный словарь
2.1. Визуализируем реальное: простые формы и магия подписи
С детства для познания мира мы набираем свой понятийный словарь. Нам показывают стул и присваивают ему название. Мы связываем понятие с визуальным образом стула. Т. е. какая-то библиотека визуальных образов существует у каждого человека. Причём, образ стула на базовом уровне распознавания достаточно прост – это поверхность с четырьмя ножками и спинкой. Чтобы сказать, что это стул, нам не нужно думать о материалах, текстуре ткани и уникальностях разных форм. Достаточно нескольких простых признаков.
При формировании своего визуального словаря можно использовать тот же механизм – совмещения образа и понятия. И не заморачиваться красивой отрисовкой, достаточно нарисовать основные признаки. А это может сделать каждый, кто сумеет нарисовать набор простых форм: круг, квадрат, треугольник и линию.
Понятия можно разделить на реальные и абстрактные. В этой главе мы сосредоточимся на приёмах рисования реальных понятий. Реальные – это те, что присвоены объектам, существующим в окружающем нас визуальном мире.
Чтобы изобразить объект из реального мира, нам достаточно вспомнить, как он выглядит в реальном мире, и очень упрощенно его нарисовать.