Тимур Машнин
Основы SEO. Введение в поисковую оптимизацию
Исходный код
Исходный код к примерам можно скачать с сайта GitHub (https://github.com/novts/seo).
Введение. Поисковые системы
Чтобы действительно понять, почему поисковые системы работают так, как они работают, важно знать историю поисковых систем.
В это уже тяжело поверить, но в начале 2000-х сеть выглядела именно так.
Это был список ссылок, которые поддерживались людьми.
И поиск нужной вам информации был сложным процессом, и обычно он заключался в переходе по ссылке со ссылки в надежде, что вы попадете в нужное вам место.
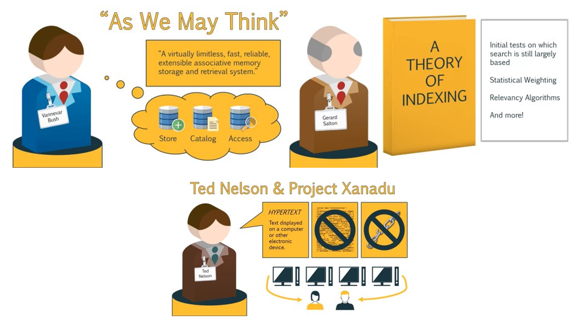
Сама идея Интернета появилась в 1945 году после того, как инженер Буш написал для Time статью «Как мы можем думать».
В этой статье Буш подтолкнул ведущих ученых того времени к созданию практически безграничной, быстрой, надежной, и расширяемой системы хранения и поиска.
Буш понял, что технологии развиваются быстрыми темпами, и поэтому человечеству понадобится способ хранить и легко получать доступ к информации, которая накапливается.
Далее в 1960-м, Джерард Сэлтон, который считается отцом современных поисковых технологий, создал идею поисковой системы и разработал информационно-поисковую систему под названием SMART.
Сэлтон является автором книги под названием «Теория индексации», в которой подробно описываются такие понятия, как статистическое взвешивание, алгоритмы релевантности и многое другое.
Примерно в то же время Тед Нельсон создал проект Project Xanadu, целью которого было создание компьютерной сети с простым пользовательским интерфейсом.
И Тед придумал термин «гипертекст» и был против сложного кода разметки.
Вскоре после этого, в 1969 году, родилась служба ARPANET, которая была создана ARPA, Агентством перспективных исследовательских проектов, относящимся к Министерству обороны США.
ARPANET была безопасной и быстрой компьютерной сетью, которая позволяла передавать информацию на большие расстояния.
И эта служба использовала телефонные линии для передачи информации военной разведки.
Можно с уверенностью сказать, что без создания ARPANET Интернет, каким мы его знаем сегодня, не существовал бы.
В 1990-м, появилась первая поисковая система, созданная Аланом Эмтажем.
Эта поисковая система была известна как Арчи, и она могла извлечь файлы из базы данных, сопоставив запрос пользователя с помощью регулярных выражений.
Алан также создал метод индексации, который позволил Арчи индексировать общедоступные документы, изображения, аудио и сервисы в сети.
Арчи не использовал ключевые слова для поиска связанных документов, как это делают современные поисковые системы.
Чтобы эффективно использовать Арчи, нужно было знать имя файла, который вы ищите, так как Арчи не индексировал содержимое файлов, а только заголовки.
К 1992 году Арчи содержал около 2,6 миллиона файлов, а его сервис обрабатывал около 50 000 запросов в день, генерируемых тысячами пользователей по всему миру.
По мере роста популярности Арчи были созданы две похожие поисковые системы, Veronica и Jughead, с целью индексации текстовых файлов.
И наконец, в 1991 году Тим Бернерс-Ли, независимый подрядчик CERN, создал World Wide Web.
Всемирная паутина была создана на основе концепции гипертекста, чтобы облегчить обмен и обновление информации исследователей CERN.
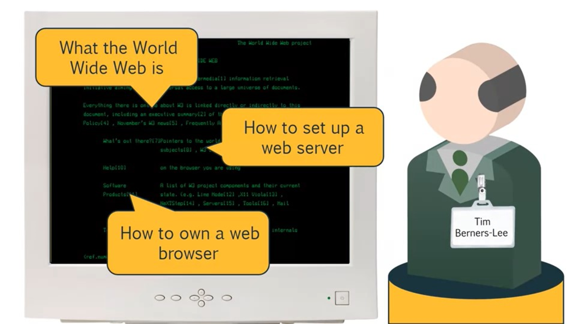
В 1991 году был создан и размещен в сети первый веб-сайт.
В нем содержалось объяснение того, что такое Всемирная паутина, и как можно настроить веб-сервер и пользоваться браузером.
В 1993 году был создан первый робот-паук. Этот бот назывался World Wide Web Wanderer и был предназначен для измерения роста сети.
Вскоре бот был обновлен для сбора активных URL-адресов и сохранения их в базе данных WANDEX.
Но робот вскоре стал скорее проблемой, чем решением.
Он сканировал веб-сайты и обращался к страницам сотни раз в день, создавая большую задержку на серверах и иногда вызывая сбои веб-сайтов.
Это создало большое недоверие к роботам среди веб-мастеров и широкой публики.
Поэтому был создан робот ALIWEB.
ALIWEB расшифровывался как Archie-подобная индексация Интернета, и он сканировал метаинформацию страниц.
И ALIWEB разрешил владельцам предоставлять свой сайт для включения в поисковый индекс вместе с описанием веб-страниц.
Недостатком было то, что многие люди не знали, что они должны предоставить свой сайт для индексации.
И все современные поисковые системы создали программы, известные как роботы.
И каждая поисковая система использует своего уникального робота.
Эти роботы сканируют Интернет, пытаясь обнаружить новые веб-страницы и документы.
Один из способов, с помощью которого роботы открывают новые сайты, – это ссылки.
Если другой веб-сайт ссылается на ваш сайт, это упрощает путь для робота.
В первые дни Интернета веб-мастерам приходилось размещать свой сайт в поисковых системах, чтобы его могли обнаружить роботы.
Теперь роботы найдут ваш сайт самостоятельно.
И добавление вашего сайта в бесплатных службах, таким как Инструменты Google, поможет в этом процессе обнаружения.
Как только робот обнаруживает новую страницу или сайт, он анализирует весь контент и данные на странице, чтобы определить, о чем идет речь.
Затем сайт добавляется в базу данных.
Каждая страница находится в каталоге, поэтому поисковые системы могут быстро ссылаться на данные при необходимости и возвращать соответствующие результаты в ответ на поисковый запрос пользователя.
Чтобы ускорить процесс, по всему миру расположены центры обработки данных, которые позволяют быстро получать доступ к большому количеству информации.
И работа SCO заключается в том, чтобы понять, что делает веб-сайт релевантным для поискового запроса.
В прошлом поисковые системы смотрели только контент на вашей странице или какие ключевые слова, использовались наиболее часто.
Сейчас поисковые системы стали намного умнее.
И сегодня существуют сотни факторов, влияющих на релевантность результатов поиска.
В свое время был создан стандарт исключения роботов, который устанавливает стандарты того, как поисковые системы должны индексировать или не индексировать контент.
И используя стандарт исключения роботов, веб-мастера могут указывать поисковым системам, какой контент они хотят сканировать и какой контент они хотят, чтобы поисковые системы оставили в покое.
Вы можете заблокировать просмотр роботом всего сайта или только определенных страниц.
По умолчанию вся публичная информация сканируется и публикуется.
К концу 1993 года были созданы три поисковых системы.
Хотя ни одна из них не показала себя достаточно хорошо, чтобы сохраниться.
Jumpstation собирала заголовки веб-страниц и извлекала их с помощью простого линейного поиска.
WWW Worm индексировала заголовки и URL, но отображала результаты только в том порядке, в котором они были обнаружены.
Третья система Spider Based Software Engineering или RBSE, не имела никакой системы ранжирования.
И по сути, чтобы пользоваться любой из этих поисковых систем, вам нужно было знать точное название того, что вы искали.
Примерно в то же время шесть старшекурсников из Стэнфорда создали поисковую систему, которая оценивала результаты на основе статистического анализа взаимосвязей слов.