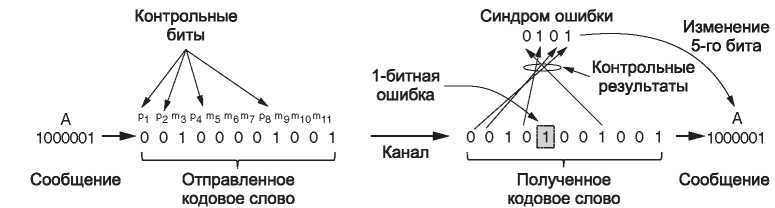
Этот теоретический нижний предел может быть достигнут на практике с помощью метода Хэмминга (1950). В кодах Хэмминга биты кодового слова нумеруются последовательно слева направо, начиная с 1. Биты с номерами, равными степеням 2 (1, 2, 4, 8, 16 и т. д.), являются контрольными. Остальные биты (3, 5, 6, 7, 9, 10 и т. д.) заполняются m битами данных. Такой шаблон для кода Хэмминга (11,7) с 7 битами данных и 4 контрольными битами показан на рис. 3.6. Каждый контрольный бит обеспечивает сумму по модулю 2 или четность некоторой группы бит, включая себя самого. Один бит может входить в несколько вычислений контрольных бит. Чтобы определить, в какие группы контрольных сумм будет входить бит данных в k-й позиции, следует разложить k по степеням числа 2. Например, 11 = 8 + 2 + 1, а 29 = 16 + 8 + 4 + 1. Каждый бит проверяется только теми контрольными битами, номера которых входят в этот ряд разложения (например, 11-й бит проверяется битами 1, 2 и 8). В нашем примере контрольные биты вычисляются для проверки на четность в сообщении, представляющем букву «A» в кодах ASCII.
Расстояние этого кода равно 3, то есть он позволяет исправлять одиночные ошибки (или распознавать двойные). Причина такой сложной нумерации бит данных и контрольных бит становится очевидной, если рассмотреть процесс декодирования. Когда
прибывает кодовое слово, приемник повторяет вычисление контрольных бит, учитывая значения полученных контрольных бит. Их называют результатами проверки. Если контрольные биты правильные, то для четных сумм все результаты проверки должны быть равны нулю. В таком случае кодовое слово принимается как правильное.
Рис. 3.6. Пример кода Хэмминга (11,7), исправляющего однобитную ошибку
Если не все результаты проверки равны нулю, это означает, что обнаружена ошибка. Набор результатов проверки формирует синдром ошибки (error syndrome), с помощью которого выделяется и исправляется ошибка. На рис. 3.6 в канале произошла ошибка в одном бите. Результаты проверки равны 0, 1, 0 и 1 для k = 8, 4, 2 и 1 соответственно. Таким образом, синдром равен 0101 или 4 + 1 = 5. Согласно схеме, пятый бит содержит ошибку. Поменяв его значение (а это может быть контрольный бит или бит данных) и отбросив контрольные биты, мы получим правильное сообщение: букву «A» в кодах ASCII.
Кодовые расстояния полезны для понимания блочных кодов, а коды Хэмминга применяются в самокорректирующейся памяти. Однако в большинстве сетей используются более надежные коды. Второй тип кода, с которым мы познакомимся, называется сверточным кодом. Из всех рассмотренных в данной книге только он не относится к блочному типу. Кодировщик обрабатывает последовательность входных бит и генерирует последовательность выходных бит. В отличие от блочного кода, никакие ограничения на размер сообщения не накладываются, также не существует грани кодирования. Значение выходного бита зависит от значения текущего и предыдущих входных бит — если у кодировщика есть возможность использовать память. Число предыдущих бит, от которого зависит выход, называется длиной кодового ограничения для данного кода. Сверточные коды описываются в терминах кодовой нормы и длины кодового ограничения.
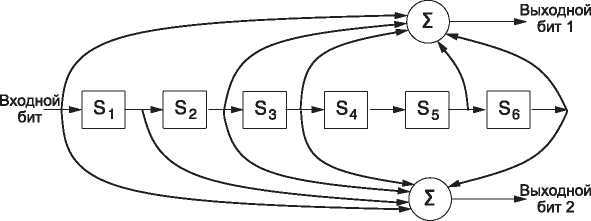
Сверточные коды широко применяются в развернутых сетях. Например, входят в мобильную телефонную систему GSM, спутниковые сети и сети 802.11. В качестве примера можно рассмотреть популярный сверточный код, показанный на рис. 3.7. Он называется сверточным кодом NASA с r = 1/2 и k = 7 (впервые этот код был использован при подготовке космического полета станции Voyager, запущенной в 1977 году). С тех пор он постоянно используется в других приложениях, таких как сети 802.11.
На рис. 3.7 для каждого входного бита слева создается два выходных бита справа. Эти выходные биты получаются путем применения операции исключающего ИЛИ к входному биту и внутреннему состоянию. Так как кодирование работает на уровне бит и использует линейные операции, это двоичный линейный сверточный код. Поскольку один входной бит создает два выходных бита, кодовая норма r равна 1/2. Этот код не систематический, так как входные биты никогда не передаются на выход напрямую, без изменений.
Рис. 3.7. Двоичный сверточный код NASA применяется в сетях 802.11
Внутреннее состояние хранится в шести регистрах памяти. При поступлении на вход очередного бита значения в регистрах сдвигаются вправо. Например, если на вход подается последовательность 111, а в первоначальном состоянии в памяти только нули, то после подачи первого, второго и третьего бита оно будет меняться на 100000, 110000 и 111000 соответственно. На выходе получатся значения 11, затем 10 и затем
01. Для того чтобы полностью подавить первоначальное состояние регистров (тогда оно не будет влиять на результат), требуется семь сдвигов. Длина кодового ограничения для данного кода k, таким образом, равна 7.
Декодирование сверточного кода осуществляется путем поиска последовательности входных битов, с наибольшей вероятностью породившей наблюдаемую последовательность выходных битов (включающую любые ошибки). Для небольших значений k это делается с помощью широко распространенного алгоритма, разработанного Витерби (Forney, 1973). Этот алгоритм проходит по наблюдаемой последовательности, сохраняя для каждого шага и для каждого возможного внутреннего состояния входную последовательность, которая породила бы наблюдаемую последовательность с минимальным числом ошибок. Входная последовательность, которой соответствует минимальное число ошибок, и есть наиболее вероятное исходное сообщение.
Сверточные коды были очень популярны для практического применения, так как в декодировании очень легко учесть неопределенность значения бита (0 или 1). Например, предположим, что -1 В соответствует логическому уровню 0, а +1 В соответствует логическому уровню 1. Мы получили для двух бит значения 0,9 В и -0,1 В. Вместо того чтобы сразу определять соответствие — 1 для первого бита и 0 для второго, — можно принять 0,9 В за «очень вероятную единицу», а -0,1 В за «возможный нуль» и скорректировать всю последовательность. Для более надежного исправления ошибок к неопределенностям можно применять различные расширения алгоритма Витерби. Такой подход к обработке неопределенности значения бит называется декодированием с мягким принятием решений (soft-decision decoding). И наоборот, если мы решаем, какой бит равен нулю, а какой единице, до последующего исправления ошибок, то такой метод называется декодированием с жестким принятием решений (hard-decision decoding).
Третий тип кода с исправлением ошибок, с которым мы познакомимся, называется кодом Рида—Соломона. Как и коды Хэмминга, коды Рида—Соломона относятся к линейным блочным кодам; также многие из них систематические. Но в отличие от кодов Хэмминга, которые применяются к отдельным битам, коды Рида—Соломона работают на группах из m-битовых символов. Разумеется, математика здесь намного сложнее, так что применим аналогию.
Коды Рида-Соломона основываются на том факте, что каждый многочлен п-й степени уникальным образом определяется п + 1 точкой. Например, если линия задается формулой ax + b, то восстановить ее можно по двум точкам. Дополнительные точки, лежащие на той же линии, излишни, но они полезны для исправления ошибок. Предположим, что две точки данных представляют линию. Мы отправляем по сети эти две точки данных, а также еще две контрольные точки, лежащие на той же линии. Если в значение одной из точек по пути закрадывается ошибка, то точки данных все равно можно восстановить, подогнав линию к полученным правильным точкам. Три точки окажутся на линии, а одна, ошибочная, будет лежать вне ее. Обнаружив правильное положение линии, мы исправили ошибку.