Серверные фермы
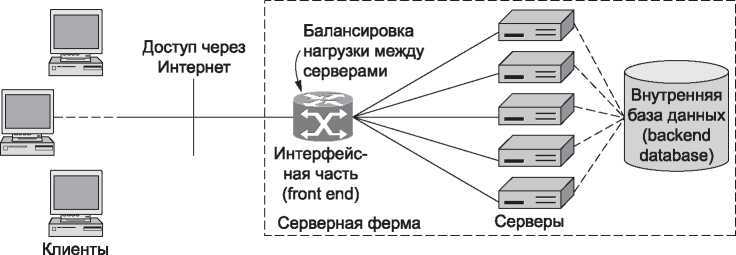
Сколько бы пропускной способности не имела одна машина, она может обслуживать только определенное количество сетевых запросов, затем она будет перегружена. Решение в данном случае — использовать несколько компьютеров, чтобы сделать веб-сервер. Это приводит к модели серверной фермы (server farm), показанной на рис. 7.38.
Рис. 7.38. Серверная ферма
Трудность с этой с виду простой моделью заключается в том, что набор компьютеров, образующих серверную ферму, должен выглядеть для клиентов как единый логический веб-сайт. В противном случае мы имеем дело просто с несколькими вебсайтами, работающими параллельно. Существует несколько возможных решений, чтобы набор серверов выглядел как один веб-сайт. Все решения предполагают, что каждый из серверов может обрабатывать запрос от любого клиента. Для этого каждый сервер должен иметь копию веб-сайта. Пунктирными линиями показано соединение с этой целью серверов с общей внутренней базой данных.
Одно из решений — использовать DNS для распределения запросов по серверам серверной фермы. Когда сделан запрос DNS для URL веб-сайта, DNS-сервер возвращает меняющийся список IP-адресов серверов. Каждый клиент обращается к одному IP-адресу, обычно к первому в списке. Таким образом, разные клиенты обращаются к разным серверам с целью достижения одного и того же веб-узла, как и задумано. Метод DNS лежит в основе технологии CDN, мы снова вернемся к нему позже в этом разделе.
Другие решения основаны на интерфейсной части (front end), которая распределяет поступающие запросы по пулу серверов в серверной ферме, даже если клиент контактирует с серверной фермой, используя один IP-адрес назначения. Интерфейсная часть обычно представляет собой сетевой коммутатор на канальном уровне или IP-маршрутизатор, то есть устройство, которое управляет фреймами или пакетами. Все решения основаны на том, что эти устройства (или серверы) просматривают заголовки сетевого или транспортного уровня или уровня приложений и используют их нестандартным образом. Веб-запрос и ответ переносятся как TCP-соединение. Чтобы работать правильно, интерфейсная часть должна отправить все пакеты одного запроса к одному серверу.
Простая схема интерфейсной части — передавать все входящие запросы всем серверам. Каждый сервер отвечает только на часть запросов по предварительному соглашению. Например, 16 серверов могут смотреть на IP-адрес источника данных и отвечать только на те запросы, последние 4 бита IP-адресов которых соответствуют их определенному селектору. Другие пакеты отбрасываются. Хотя это и расточительно с точки зрения расхода пропускной способности, но так как зачастую ответы намного длиннее, чем запросы, это вовсе не так нелепо, как может показаться.
В более общем варианте структуры, интерфейсная часть, возможно, проверяет IP-, TCP-, и HTTP-заголовки пакетов и произвольно распределяет их по серверам. Распределение называют политикой балансировки нагрузки (load balancing), так как его цель — балансировать рабочую нагрузку серверов. Политика может быть простой или сложной. Простая политика может состоять в том, чтобы использовать серверы один за другим по очереди или по кругу циклически. В этом случае интерфейс должен помнить отображение каждого запроса, чтобы последующие пакеты, являющиеся частью того же запроса, были отправлены к тому же серверу. Кроме того, для того чтобы сделать сайт надежнее, чем один сервер, интерфейс должен получать информацию о случаях отказов серверов и прекращать посылать запросы на отказавшие серверы.
Во многом, как и NAT, эта общая схема является опасной или, как минимум, хрупкой, так как мы только что создали устройство, которое нарушает самый основной принцип многоуровневых протоколов: каждый уровень должен использовать свой собственный заголовок для целей управления и не может проверять или использовать информацию из полезной нагрузки для каких бы то ни было целей. Но люди все равно проектируют такие системы и склонны удивляться, когда они выходят из строя вследствие изменений в более высоких уровнях. Интерфейс в данном случае — сетевой коммутатор или маршрутизатор, но он может действовать основываясь на информации транспортного или более высокого уровня. Такое устройство называется «промежуточным узлом» (middlebox), потому что оно вставлено в середине сетевого пути, где у него нет никакого дела согласно стеку протоколов. В этом случае интерфейс лучше всего рассматривать как внутреннюю часть серверной фермы, которая заканчивает все уровни вплоть до прикладного уровня (и поэтому может использовать всю информацию заголовков этих уровней).
Тем не менее, как и NAT, эта схема полезна на практике. Причина для просмотра TCP-заголовков заключается в том, что в этом случае можно достигнуть лучшего баланса загрузки, чем имея только информацию IP. Например, один IP-адрес может представлять целую компания и делать много запросов. И только просматривая TCP или информацию более высоких уровней, можно направить эти запросы на различные серверы.
Причина для просмотра заголовков HTTP несколько иная. Очень много вебвзаимодействий являются доступом к базам данных и их модификацией, например когда клиент просматривает свою самую недавнюю покупку. Серверу, который получит этот запрос, придется запросить общую внутреннюю базу данных. Полезно направить последующие запросы от этого же пользователя на тот же сервер, потому что он уже имеет информацию о пользователе в кэше. Самый простой путь для этого — использовать веб-куки (или другую информацию для различения пользователей) и просматривать заголовки HTTP для их обнаружения.
В заключение заметим, что хотя мы описали этот проект для веб-сайтов, серверная ферма может быть построена и для других видов серверов. Примером могут быть серверы потокового медиа поверх UDP. Единственное изменение, которое потребуется, — интерфейс должен быть способен поддерживать баланс нагрузки этих запросов (у которых будут другие поля заголовка протокола, чем у веб-запросов).
Веб-прокси
Сетевые запросы и ответы посылаются с использованием HTTP. В разделе 7.3 мы описали, как браузеры могут кэшировать ответы и использовать их многократно для ответов на последующие запросы. Различные поля заголовков и правила используются браузером, чтобы определить, является ли кэшированная копия веб-страницы все еще актуальной. Здесь мы не будем повторять этот материал.
Кэширование улучшает работу, сокращая продолжительность времени ответа и загруженность сети. Если браузер может сам определить, что кэшированная страница актуальна, он может немедленно выбрать ее из кэша, вообще без сетевого трафика. Однако, даже если браузер должен запросить сервер о подтверждении актуальности страницы, продолжительность времени ответа сокращена и сетевая нагрузка меньше, особенно для больших страниц, так как посылается только маленькое сообщение.
Тем не менее лучшее, что может сделать браузер, — кэшировать все веб-страницы, которые посетил пользователь. Из нашего обсуждения популярности, вы, возможно, помните, что кроме небольшого количества популярных страниц, которые неоднократно посещает много людей, существует очень много непопулярных страниц. На практике это ограничивает эффективность кэширования браузером, потому что существует большое количество страниц, которые данный пользователь посетит только один раз. Эти страницы всегда надо получать с сервера.
Единственный способ использовать кэш более эффективно — сделать его общим для нескольких пользователей. Таким образом страница, уже полученная для одного пользователя, может быть возвращена другому пользователю, когда он сделает такой же запрос. Без кэширования браузером обоим пользователям необходимо получить страницы с сервера. Конечно, этот общий доступ не может быть сделан для зашифрованного трафика, страниц, которые требуют аутентификацию, и некэшируемых страниц (например, текущие биржевые цены), которые возвращаются программами. Динамические страницы, особенно созданные программами, — это тот растущий случай, для которого кэширование не эффективно. Однако есть большое количество веб-страниц, которые видимы для многих пользователей и выглядят одинаково, независимо от того, кто к ним обращается (например, изображения).