Не всегда имеет значение объем трафика. Например, во время бума IP-телефонии, даже до Skype, запущенного в 2003 году, она всегда оставалась незначительным всплеском на диаграмме, потому что требования пропускной способности для звука на два порядка величины ниже, чем для видео. Тем не менее IP-телефония нагружает сеть в другом аспекте, потому что она чувствительна ко времени ожидания. Другой пример, он-лайновые социальные сети, растущие неистово, начиная с Fаcebook, запущенного в 2004 году. В 2010 году Fаcebook впервые получил больше пользователей в день, чем Google. Даже не рассматривая трафик (а трафик там очень большой), социальные сети важны, потому что они меняют способ взаимодействия людей через Интернет.
Вывод, который мы делаем: «сейсмические сдвиги» — существенные изменения в интернет-трафике — происходят быстро и с некоторой регулярностью. Что будет следующим? Мы обязательно сообщим вам об этом в 6-м издании нашей книги.
Второй существенный факт об интернет-трафике — он чрезвычайно ассиметрич-ный. Многие значения, с которыми мы имеем дело, близки к своей средней величине. Например, рост большинства взрослых людей близок к среднему. Есть некоторое количество высоких людей и некоторое количество низких и совсем мало очень высоких или очень низких. При таких свойствах можно найти диапазон, который захватит большую часть населения.
Интернет-трафик устроен не так. В течение длительного времени было известно, что есть небольшой ряд веб-узлов с большим трафиком и большая часть сайтов с намного меньшим трафиком. Эта особенность стала частью языка создания сетей. Раньше в статьях говорилось о движении в терминах поездов пакетов (pocket trains), об идее существования экспресс-поездов с большим количеством пакетов, внезапно проходящем через связь (Jain и Routhier, 1986), что было формализовано как понятие самоподобия (selfsimilarity), которое для наших целей можно понимать как сетевой трафик, который представляет собой много коротких и много длинных промежутков даже при рассмотрении в различных масштабах времени (Lebnd и др., 1994). Более
поздние работы называют длинные потоки трафика слонами (elephants), а короткие — мышами (mice). Идея заключается в том, что есть лишь несколько слонов и много мышей, но слоны имеют значение, потому что они такие большие.
Возвращаясь к веб-контенту, очевидна аналогичная ассиметрия. Опыт работы с пунктами видеопроката, библиотеками и другими подобными организациями показывает, что не все фильмы (книги) одинаково популярны. Экспериментально доказано, что если в пункте проката есть N фильмов, то доля заявок на конкретный фильм, стоящий на k-м месте в списке популярности, примерно равна
Здесь
C —
это число, дополняющее сумму долей до 1, а именно:
Таким образом, например, самый популярный фильм берут примерно в семь раз чаще, чем седьмой в списке популярности. Такая зависимость называется законом Ципфа (Zipf’s law) (Zipf, 1949). Он назван в честь Джоржа Ципфа, профессора лингвистики в Гарвардском университете, который заметил, что частота использования слова в большом тексте инверсионно пропорциональна его рангу. Например, сороковое в списке самых частотных слов используется в два раза чаще, чем восьмидесятое, и в три раза чаше, чем сто двадцатое.
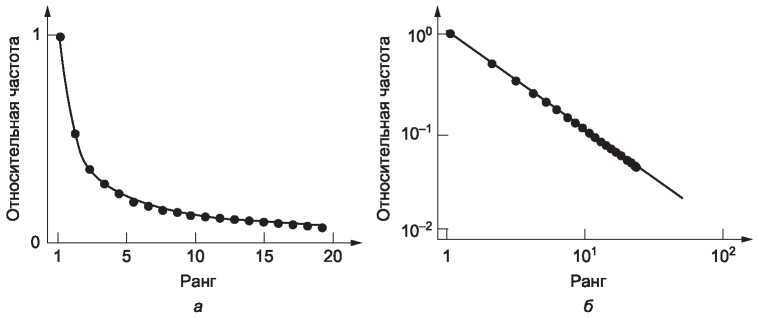
Распределение Ципфа показано на рис. 7.37, а. Он иллюстрирует утверждение о том, что существует небольшое количество популярных элементов и огромное — непопулярных. Чтобы опознавать распределения такого вида, удобно размещать данные в логарифмическом масштабе по обеим осям, как показано на рис. 7.64, б. В результате должна получаться прямая.
Рис. 7.37. Распределение Ципфа: а — линейный масштаб; б — логарифмический
по обеим осям масштаб
Изучение популярности веб-страниц показало ее приблизительное соответствие законам Ципфа (Bresku и др., 1999). Распределение Ципфа — это одно из распределений, известных как степенные законы (power laws). Степенные законы очевидны во многих сферах человеческой деятельности, например распределение городского населения и распределение богатства. Они также описывают ситуацию, когда имеются несколько больших игроков и много более мелких игроков, и они представляют собой прямую линию на логарифмическом по обеим осям масштабе. Вскоре было обнаружено, что топология Интернета может быть приблизительно описана с помощью степенных законов (Fаloutsos и др., 1999). Затем исследователи начали изображать все мыслимые свойства Интернета на логарифмическом масштабе и, увидев прямую линию, восклицали: «Степенной закон!»
Однако более важным, чем прямая линия на логарифмическом масштабе, было то, что эти распределения означают для проектирования и использования сетей. Так как большое количество контента имеет распределение Ципфа или подчиняется степенным законам, кажется фундаментальным, что популярность веб-узлов в Интернете подчиняется похожим законам. Это, в свою очередь, означает, что понятие «средний сайт» — это не удачное представление. Сайты лучше описывать как популярные и непопулярные. И те и другие значимы для рассмотрения. Популярные сайты, очевидно, значимы, так как небольшое количество популярных сайтов могут отвечать за большую часть интернет-трафика. Возможно, это покажется удивительным, но непопулярные сайты тоже значимы. Причина в том, что суммарное количество трафика, направленного к непопулярным сайтам, может составлять большую долю в общем трафике. Потому что непопулярных сайтов очень много. Это понятие — суммарное значение многих непопулярных вариантов было популяризировано, например, книгой The Long Tail («длинный хвост») (Anderson, 2008a).
Кривые, показывающие убывание, такое как на рис. 7.37, а, типичные, но все-таки не все одинаковые. В частности, ситуации, в которых уровень убывания пропорционален оставшемуся количеству материала (как например с нестойкими радиоактивными атомами) представляют собой экспоненциальное убывание (exponential decay), которое убывает намного быстрее, чем закон Ципфа. Число элементов, скажем атомов, оставшихся после момента времени t, обычно выражается, как e-t/a, где константа а показывает, насколько быстро происходит убывание. Разница между экспоненциальным убыванием и законом Ципфа заключается в том, что в первом случае можно пренебречь концом хвоста, а в случае закона Ципфа общий вес хвоста существенен и его нельзя проигнорировать.
Чтобы эффективно работать в этом ассиметричном мире, мы должны уметь строить оба вида веб-узлов. Непопулярные сайты легки в управлении. С использованием DNS, много различных сайтов могут фактически указывать на один и тот же компьютер в Интернете, который управляет ими всеми. С другой стороны, популярные сайты трудно поддерживать. Для этого нет ни одного достаточно мощного компьютера; кроме того, использование одного компьютера приведет к тому, что в случае его поломки сайт окажется недоступным для миллионов пользователей. Чтобы управлять этими сайтами, мы должен построить системы распределения контента. Мы приступим к этому далее.
7.5.2. Серверные фермы и веб-прокси
Сетевые проекты, которые мы до сих пор рассматривали, состояли из одной серверной машины, общающейся со многими клиентскими машинами. Чтобы построить большие веб-узлы с хорошими характеристиками, мы можем увеличивать скорость обработки или на серверной стороне, или на клиентской стороне. На серверной стороне более мощный веб-сервер может быть построен путем организации серверной фермы, в которой кластер компьютеров действует как единый сервер. На клиентской стороне лучшая производительность может быть достигнута с применением лучших методов кэширования. В частности, кэширующий прокси (веб-прокси) обеспечивает большой общий кэш для группы клиентов. Мы опишем каждый из этих методов. Заметим, однако, что ни один из этих способов не достаточен для построения самых больших веб-сайтов. Для самых популярных сайтов необходимы методы распределения контента, использующие компьютеры, находящиеся в различных местах; эти методы мы опишем в следующих разделах.