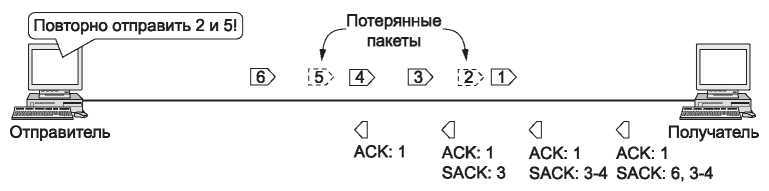
При установлении соединения отправитель и получатель передают друг другу параметр SACK permitted, чтобы показать, что они могут работать с выборочными подтверждениями. Когда выборочные подтверждения включены, обмен данными происходит так, как показано на рис. 6.42. Получатель использует поле Номер подтверждения обычным способом — как накопительное подтверждение последнего по порядку полученного байта. Когда пакет 3 приходит к нему вне очереди (так как пакет 2 потерян), он отправляет SACK option для полученных данных вместе с накопительным подтверждением (дубликатом) для пакета 1. SACK option содержит информацию о диапазонах полученных байтов, которые располагаются после номера самого подтверждения. Первый диапазон — пакет, к которому относится дубликат подтверждения. Следующие диапазоны, если они есть, относятся к последующим блокам. Обычно используется не более трех диапазонов. К моменту прихода пакета 6 в выборочном
подтверждении используется уже два диапазона: первый указывает на получение пакетов 3 и 4, второй — на получение пакета 6 (вдобавок к пакетам, полученным до пакета 1). Основываясь на всех полученных SACK option, отправитель решает, какие пакеты следует передать повторно. В данном случае лучше всего взять пакеты 2 и 5.
Рис. 6.42. Выборочные подтверждения
Выборочные подтверждения содержат рекомендательную информацию. На самом деле, обнаружение потери пакетов по дубликатам подтверждений и изменение окна перегрузки происходят так, как было описано выше. Тем не менее выборочные подтверждения упрощают процесс восстановления в ситуациях, когда несколько пакетов теряются примерно в одно и то же время, так как с их помощью отправитель узнает, какие пакеты не дошли до адресата. Выборочные подтверждения применяются далеко не везде. О них рассказывается в RFC 2883, а контроль управления TCP с использованием выборочных подтверждений описан в RFC 3517.
Второе усовершенствование состоит в использовании явных уведомлений о перегрузке (ECN, Explicit Congestion Notification) в качестве дополнительного сигнала о перегрузке. Явные уведомления о перегрузке представляют собой механизм IP-уровня, позволяющий сообщать хостам о перегрузке (см. раздел 5.3.4). С его помощью TCP-приемник может получать сигналы о насыщении от IP.
Явные уведомления о перегрузке включены для TCP-соединения, если при установке этого соединения отправитель и получатель сообщили друг другу о том, что они могут использовать такие уведомления, с помощью битов ECE и CWR. В таком случае в заголовке каждого пакета с TCP-сегментом указано, что этот пакет может передавать явные уведомления о перегрузке. Тогда при угрозе перегрузки маршрутизаторы, поддерживающие такие уведомления, будут помещать сигналы о перегрузке в пакеты, имеющие соответствующие флаги, вместо того чтобы удалять пакеты, когда перегрузка действительно возникнет.
Если какой-то из прибывших пакетов содержит явное уведомление о перегрузке, TCP-приемник узнает об этом и с помощью флага ECE (ECN-эхо) сообщает отправителю о перегрузке. Отправитель подтверждает получение этого сигнала с помощью флага CWR (Окно перегрузки уменьшено).
На такие сигналы отправитель реагирует точно так же, как и на потерю пакетов. Но теперь результат выглядит лучше: перегрузка обнаружена, хотя ни один пакет не пострадал. Явные уведомления о перегрузке описаны в RFC 3168. Так как им требуется поддержка как хостов, так и маршрутизаторов, в Интернете они не очень широко используются.
Полный список механизмов контроля перегрузки в TCP и их работа описаны в RFC 5681.
6.5.11. Будущее TCP
TCP — «рабочая лошадка» Интернета — используется многими приложениями; с течением времени разработчики видоизменяют и дополняют этот протокол, стараясь добиться высокой производительности в различных сетях. На сегодняшний день существует много версий, каждая из которых добавляет что-то новое к классическим алгоритмам, описанным здесь; особенно это касается контроля перегрузки и устойчивости к сетевым атакам. По всей вероятности, TCP будет развиваться параллельно с Интернетом. Здесь мы рассмотрим два частных вопроса.
Во-первых, протокол TCP не решает проблем транспортной семантики, актуальных для многих приложений. К примеру, некоторые приложения хотят, чтобы границы передаваемых ими сообщений или записей сохранялись. Другие приложения хотят работать с группами взаимосвязанных сообщений — как, например, веб-браузер, загружающий несколько объектов с одного сервера. Некоторым приложениям нужны дополнительные возможности управления сетевыми путями. TCP со своим стандартным интерфейсом сокетов не в состоянии выполнить эти требования. В результате каждое приложение вынуждено самостоятельно решать проблемы, которые не по силам TCP. Это привело к возникновению новых протоколов со слегка измененным интерфейсом. Среди них SCTP (Stream Control Transmission Protocol, протокол передачи с управлением потоками), описанный в RFC 4960, и SST (Structured Stream Transport, иерархическая поточная транспортировка данных) (Ford, 2007). Но, как известно, всегда, когда кто-то предлагает изменить проверенный веками механизм, возникает два противоборствующих лагеря: «Пользователи хотят новых возможностей» и «Если ничего не сломано, не надо ничего чинить».
Второй вопрос касается контроля перегрузки. После такого подробного обсуждения различных механизмов и их усовершенствований этот вопрос мог показаться решенным. Это не так. Форма контроля перегрузки, описанная выше и достаточно популярная, использует в качестве сигнала о перегрузке потерю пакетов. При моделировании пропускной способности с помощью пилообразной схемы Padhye и его коллеги (1998) обнаружили, что при увеличении скорости частота потери пакетов должна резко снижаться. Чтобы добиться пропускной способности 1 Гбит/с при круговой задержке 100 мс и размере пакета 1500 байт, один пакет может теряться каждые 10 минут. Это соответствует частоте потери пакетов 2 х 10 - 8, а это очень мало. Потеря пакетов будет происходить слишком редко, так что этот параметр не может служить хорошим сигналом о перегрузке; число пакетов, потерянных по другой причине (например, ошибки при передаче происходят с частотой 10 - 7), может легко превысить это значение, что приведет к снижению пропускной способности.
До сих пор это не представлялось актуальным, но по мере того как сети становятся все более быстрыми, разработчики возвращаются к вопросу контроля перегрузки. Один из возможных вариантов — использовать новый алгоритм, в котором потеря пакетов вообще не учитывается. Несколько примеров было приведено в разделе 6.2. Сигналом перегрузки может быть, например, круговая задержка, которая растет при перегрузках, как в FAST TCP (Wei и др., 2006). Возможны и другие подходы; какой из них лучше — покажет время.
6.6. Вопросы производительности
Вопросы производительности играют важную роль в компьютерных сетях. Когда сотни или тысячи компьютеров соединены вместе, их взаимодействие становится очень сложным и может привести к непредсказуемым последствиям. Часто эта сложность приводит к низкой производительности, причины которой довольно трудно определить. В следующих разделах мы рассмотрим многие вопросы, связанные с производительностью сетей, определим круг существующих проблем и обсудим методы их разрешения.
К сожалению, понимание производительности сетей — это скорее искусство, чем наука. Теоретическая база, допускающая хоть какое-то практическое применение, крайне скудна. Лучшее, что мы можем сделать, это представить несколько практических методов, полученных в результате долгих экспериментов, а также привести несколько реально действующих примеров. Мы намеренно отложили эту дискуссию до того момента, когда будет изучен транспортный уровень в сетях TCP, чтобы иметь возможность иллюстрировать некоторые места примерами из TCP.