Для отправителя существует быстрый способ узнать, что один из его пакетов потерян. По мере того как пакеты, следующие за потерянным пакетом, прибывают на приемник, они инициируют отправку подтверждений, которые приходят к отправителю. Все они имеют один и тот же номер подтверждения и называются дубликатами подтверждений (duplicate acknowledgements). Каждый раз, когда отправитель получает дубликат подтверждения, есть вероятность, что другой пакет уже пришел, а потерянный — нет.
Так как пакеты могут следовать разными путями, они могут приходить в неправильном порядке. В таком случае дубликаты подтверждений не будут означать потерю пакетов. Однако в Интернете такое случается достаточно редко. Если в результате прохождения пакетов по разным путям порядок пакетов все же нарушается, он нарушается не сильно. Поэтому в TCP условно считается, что три дубликата подтверждений сигнализируют о потере пакета. Также по номеру подтверждения можно установить, какой именно пакет потерян. Это следующий по порядку пакет. Его повторную передачу можно выполнить сразу, не дожидаясь, пока сработает таймер.
Этот эвристический метод получил название быстрый повтор ( fast retransmisson). Когда это происходит, порог медленного старта все равно устанавливается равным половине текущего окна перегрузки, как и в случае тайм-аута. Медленный старт можно начать заново, взяв окно размером в один сегмент. Новый пакет будет отправлен через время, за которое успеет прийти подтверждение для повторно переданного пакета, а также все остальные данные, переданные в сеть до обнаружения потери пакета.
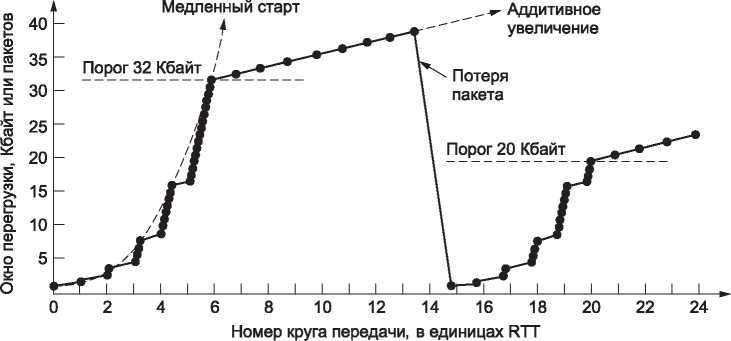
На данный момент мы имеем алгоритм контроля перегрузки, работа которого проиллюстрирована на рис. 6.40. Эта версия называется TCP Tahoe в честь 4.2BSD Tahoe, выпущенного в 1988 году, где эти идеи были реализованы. Максимальный размер сегмента в данном примере равен 1 Кбайт. Сначала окно перегрузки было установлено равным 64 Кбайт, но затем произошел тайм-аут, и порог стал равным 32 Кбайт, а окно перегрузки — 1 Кбайт (передача 0). Затем размер окна перегрузки удваивается на каждом шаге, пока не достигает порога (32 Кбайт). Размер окна увеличивается каждый раз, когда приходит новое подтверждение, то есть не непрерывно, поэтому мы и имеем дискретный ступенчатый график. На каждом круге размер окна увеличивается на один сегмент.
Рис. 6.40. Медленный старт и последующее аддитивное увеличение в TCP Tahoe
Передачи на круге 13 оказываются неудачными (как и положено), и одна из них заканчивается потерей пакета. Отправитель обнаруживает это после получения трех дубликатов подтверждений. После этого потерянный пакет передается повторно, а пороговое значение устанавливается равным половине текущего размера окна (40 Кбайт пополам, то есть 20 Кбайт), и опять происходит медленный старт. До запуска нового медленного старта с окном в один сегмент проходит еще один круг, за который все ранее переданные данные, включая копию потерянного пакета, успевают покинуть сеть. Окно перегрузки снова увеличивается в соответствии с алгоритмом медленного старта до тех пор, пока оно не дойдет до порогового значения в 20 Кбайт. После этого рост размера окна опять становится линейным. Так будет продолжаться до следующей потери пакета, которая будет обнаружена с помощью дубликатов подтверждений или после наступления тайм-аута (или же до заполнения окна получателя).
Версия TCP Tahoe (в которой, кстати, используются хорошие таймеры повторной передачи) реализует работающий алгоритм контроля перегрузки, решающий проблему отказа сети из-за перегрузки. Джекобсон придумал, как сделать его еще лучше. Во время быстрой повторной передачи соединение работает с окном слишком большого размера, но скорость прихода подтверждений продолжает учитываться. Каждый раз, когда приходит дубликат подтверждения, велика вероятность того, что еще один пакет покинул сеть. Таким образом можно считать общее число пакетов в сети и продолжать отправку нового пакета при получении каждого дополнительного дубликата подтверждения.
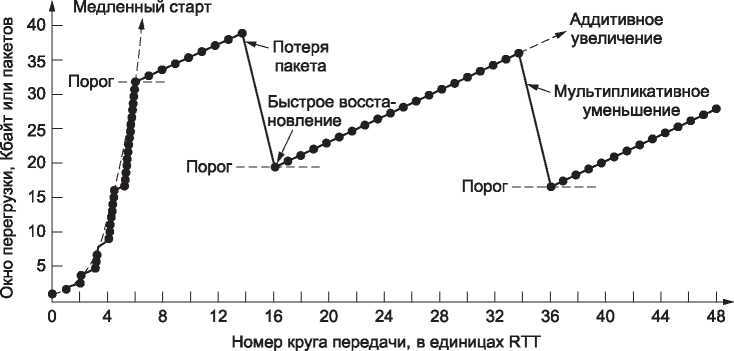
Эвристический метод, реализующий эту идею, получил название быстрое восстановление (fast recovery). Это временный режим, позволяющий не останавливать учет скорости прихода подтверждений в тот момент, когда порогом медленного старта становится текущий размер окна или его половина (во время быстрой повторной передачи). Для этого считаются дубликаты подтверждений (включая те три, которые инициировали быструю повторную передачу) до тех пор, пока число пакетов в сети не снизится до нового порогового значения. На это уходит примерно половина круговой задержки. Начиная с этого момента для каждого полученного дубликата подтверждения отправитель может передавать в сеть новый пакет. Через один круг после быстрой повторной передачи получение потерянного пакета подтвердится. В этот момент дубликаты подтверждений перестанут приходить сплошным потоком, и алгоритм выйдет из режима быстрого восстановления. Окно перегрузки станет равным новому порогу медленного старта и начнет увеличиваться линейно.
В итоге этот метод позволяет избежать медленного старта в большинстве ситуаций, за исключением случаев установления нового соединения и возникновения таймаутов. Последнее может произойти, если теряется более чем один пакет, а быстрая повторная передача не помогает. Вместо того чтобы снова и снова начинать с медленного старта, окно перегрузки активного соединения перемещается по линиям аддитивного увеличения (на один сегмент за круг) и мультипликативного уменьшения (в два раза за круг), имеющим пилообразный вид. Это и есть правило AIMD, которое мы с самого начала хотели реализовать.
Такое пилообразное движение показано на рис. 6.41. Данный метод используется в TCP Reno, который назван в честь выпущенного в 1990 году 4.3BSD Reno. По сути, TCP Reno — это TCP Tahoe с быстрым восстановлением. После начального медленного старта окно насыщения увеличивается линейно, пока отправитель не обнаружит потерю пакета, получив нужное количество дубликатов подтверждения. Потерянный пакет передается повторно, и далее алгоритм работает в режиме быстрого восстановления, который дает возможность не останавливать учет скорости прихода подтверждений до тех пор, пока не прибудет подтверждение о доставке повторно переданного пакета. После этого окно перегрузки принимает значение, равное новому порогу медленного старта, а не 1. Это продолжается неопределенно долго. Почти все время размер окна перегрузки близок к оптимальному значению произведения пропускной способности и времени задержки.
Механизмы выбора размера окна, использующиеся в TCP Reno, более чем на два десятилетия стали основой контроля перегрузки в TCP. В течение этих лет механизмы претерпели ряд незначительных изменений — в частности, появились новые способы выбора начального окна, были устранены неоднозначные ситуации. Усовершенствования коснулись и механизмов восстановления после потери двух или более пакетов. К примеру, версия TCP RenoNew использует номера частичных подтверждений, полученных после повторной передачи одного из потерянных пакетов, для восстановления другого потерянного пакета (Hoe, 1996) (см. RFC 3782). С середины 1990-х годов стали появляться варианты описанного выше алгоритма, основанные на других законах управления. К примеру, в системе Linux используется CUBIC TCP (Ha и др., 2008), а Windows включает вариант Compound TCP (Tan и др., 2006).
Рис. 6.41. Быстрое восстановление и пилообразный график для TCP Reno
Два более серьезных нововведения касаются реализаций TCP. Во-первых, сложность этого алгоритма заключается в том, что по дубликатам подтверждений необходимо определить, какие пакеты были потеряны, а какие — нет. Номер накопительного подтверждения не содержит такой информации. Простым решением стало использование выборочных подтверждений (SACK, Selective ACKnowledgement), в которых может содержаться до трех диапазонов успешно полученных байтов. Такая информация позволяет отправителю более точно определить, какие пакеты следует передать повторно, и следить за еще не доставленными пакетами.