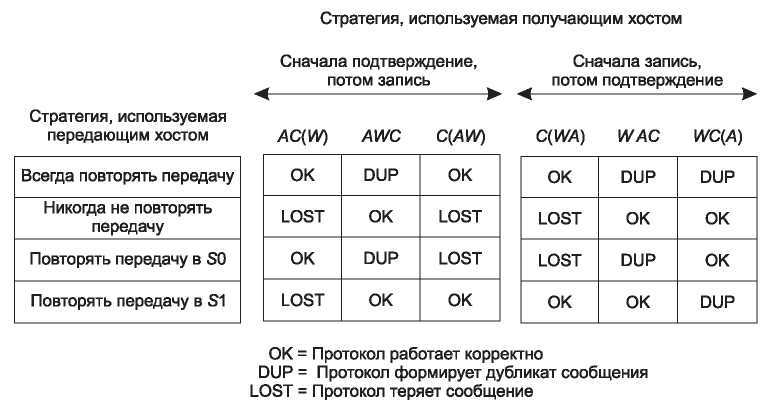
Таким образом, получаем восемь комбинаций, но как будет показано, для каждой комбинации имеется набор событий, заставляющий протокол ошибиться.
На сервере могут происходить три события: отправка подтверждения (А), запись сегмента в выходной процесс (W) и сбой (С). Они могут произойти в виде шести возможных последовательностей: АС( W), AWC, C(AW), C(WA), WAC и WC(A), где скобки означают, что после события С событие А или B может и не произойти (то есть уж сломался, так сломался). На рис. 6.15 показаны все восемь комбинаций стратегий сервера и клиента, каждая со своими последовательностями событий. Обратите внимание, что для каждой комбинации существует последовательность событий, приводящая к ошибке протокола. Например, если клиент всегда передает повторно неподтвержденный сегмент, событие AWC приведет к появлению неопознанного дубликата, хотя при двух других последовательностях событий протокол будет работать правильно.
Рис. 6.15. Различные комбинации стратегий сервера и клиента
Усложнение протокола не помогает. Даже если клиент и сервер обменяются несколькими сегментами, прежде чем сервер попытается записать полученный пакет, так что клиент будет точно знать, что происходит на сервере, у него нет возможности определить, когда произошел сбой на сервере: до или после записи. Отсюда следует неизбежный вывод: при жестком условии отсутствия одновременных событий — это значит, что отдельные события происходят одно за другим, а не одновременно — невозможно сделать отказ и восстановление хоста прозрачными для более высоких уровней.
В более общем виде это может быть сформулировано следующим образом: восстановление от сбоя уровня N может быть осуществлено только уровнем N + 1 и только при условии, что на более высоком уровне сохраняется информация о процессе, достаточная для восстановления его прежнего состояния. Это согласуется с приведенным выше утверждением о том, что транспортный уровень может обеспечить восстановление от сбоя на сетевом уровне, если каждая сторона соединения отслеживает свое текущее состояние.
Эта проблема подводит нас к вопросу о значении так называемого сквозного подтверждения. В принципе, транспортный протокол является сквозным, а не цепным, как более низкие уровни. Теперь рассмотрим случай обращения пользователя к удаленной базе данных. Предположим, что удаленная транспортная подсистема запрограммирована сначала передавать сегмент вышестоящему уровню, а затем отправлять подтверждение. Даже в этом случае получение подтверждения машиной пользователя не означает, что удаленный хост успел обновить базу данных. Настоящее сквозное подтверждение, получение которого означает, что работа была сделана, и, соответственно, отсутствие которого означает обратное, вероятно, невозможно. Более подробно этот вопрос обсуждается в (Saltzer и др., 1984).
6.3. Контроль перегрузки
Если транспортные подсистемы нескольких машин будут отправлять в сеть слишком много пакетов с большой скоростью, сеть окажется перегруженной, и производительность резко снизится, что приведет к задержке и потере пакетов. Контроль перегрузки, направленный на борьбу с такими ситуациями, требует совместной работы сетевого и транспортного уровней. Так как перегрузки происходят на маршрутизаторах, их обнаружением занимается сетевой уровень. Однако в конечном итоге причиной перегрузки является трафик, переданный транспортным уровнем в сеть. Поэтому единственный эффективный способ контролировать перегрузки состоит в более медленной передаче пакетов транспортными протоколами.
В главе 5 мы говорили о механизмах контроля перегрузки на сетевом уровне. В этом разделе мы расскажем о другой части этого процесса — механизмах контроля перегрузки на транспортном уровне. После обсуждения основных задач контроля перегрузки мы перейдем к описанию методов, позволяющих хостам регулировать скорость передачи пакетов в сеть. Контроль перегрузки в сети Интернет опирается во многом на транспортный уровень; для этого в TCP и другие протоколы встроены специальные алгоритмы.
6.3.1. Выделение требуемой пропускной способности
Перед тем как перейти к описанию методов регулирования трафика, необходимо понять, чего мы хотим от алгоритма контроля перегрузки. То есть мы должны определить, какое состояние сети должен поддерживать такой алгоритм. В его задачи входит не только предотвращение перегрузок: он должен правильно распределять пропускную способность между транспортными подсистемами, работающими в сети. Правильное распределение пропускной способности должно обеспечивать сети хорошую производительность (так как при этом сеть должна работать с использованием всей доступной мощности без перегрузок), следовать принципу равноправия конкурирующих транспортных подсистем и быстро отслеживать изменения в запросах на выделение ресурсов. Мы рассмотрим каждый из этих критериев отдельно.
Эффективность и мощность
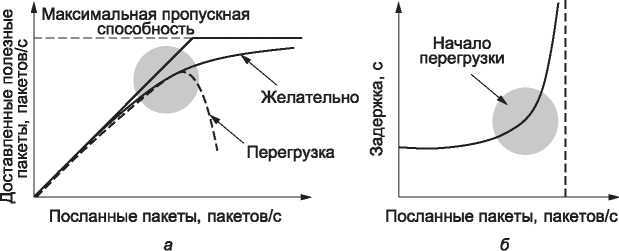
Эффективное распределение пропускной способности между транспортными подсистемами должно использовать все возможности сети. Однако это не значит, что в случае канала со скоростью 100 Мбит/с каждая из пяти транспортных подсистем должна получить по 20 Мбит/с. Для хорошей производительности им необходимо выделить меньшую мощность. Причина в том, что трафик часто бывает неравномерным. В разделе 5.3 мы определили эффективную пропускную способность (goodput, скорость, с которой полезные пакеты прибывают к получателю) как функцию нагрузки на сеть. Эта кривая и соответствующая ей кривая задержки (как функция нагрузки) приведены на рис. 6.16.
Рис. 6.16. Эффективная пропускная способность (а); задержка как функции нагрузки (б)
Сначала с ростом нагрузки на сеть эффективная пропускная способность увеличивается с постоянной скоростью (рис. 6.16, а), но когда значение нагрузки приближается к значению пропускной способности, рост эффективной пропускной способности замедляется. Этот спад необходим для того, чтобы предотвратить переполнение буферов сети и потерю данных в случае всплесков трафика. Если транспортный протокол выполняет повторную передачу задерживающихся, но не потерянных пакетов, может произойти отказ сети из-за перегрузки. В таком случае отправители продолжают передавать все больше и больше пакетов, а пользы от этого все меньше и меньше.
График задержки пакетов приведен на рис. 6.16, б. Сначала задержка является постоянной и соответствует задержке распространения в сети. Когда значение нагрузки приближается к значению пропускной способности, задержка возрастает, причем сначала медленно, а затем все быстрее и быстрее. Это происходит опять же из-за всплесков трафика, которые возрастают при высокой нагрузке. В действительности задержка не может уходить в бесконечность, если только модель не предполагает использование бесконечных буферов. Вместо этого пакеты будут теряться при переполнении буферов.
Для достижения хорошей эффективной пропускной способности и задержки производительность должна начать снижаться в момент возникновения перегрузки. Логично, что для достижения лучшей производительности сети можно выделять пропускную способность до тех пор, пока задержка не пойдет резко вверх. Эта точка находится ниже пропускной способности сети. Чтобы ее определить, Кляйнрок (Klein-rock) в 1979 году предложил ввести метрику мощность (power), которая вычисляется по формуле:
мощность = нагрузка/задержка.
Пока задержка достаточно мала и почти постоянна, мощность растет с ростом нагрузки на сеть; при резком повышении задержки она достигает максимума и резко снижается. Нагрузка, при которой мощность достигает максимума, и является наиболее эффективной нагрузкой, которую транспортная подсистема может передавать в сеть.