До сих пор мы по умолчанию предполагали, что единственное ограничение, накладываемое на скорость передачи данных, состоит в количестве свободного буферного пространства у получателя. Однако часто это бывает не так. По мере колоссального снижения цен (некогда очень высоких) на микросхемы памяти и винчестеры становится возможным оборудовать хосты таким количеством памяти, что проблема нехватки буферов будет возникать очень редко, если вообще будет возникать, даже если соединение охватывает крупные территории. Конечно же, необходимо, чтобы выбранный размер буфера был достаточно большим; это требование не всегда выполнялось в случае TCP (Zhang и др., 2002).
Если размер буферов перестанет ограничивать максимальный поток, возникнет другое узкое место: пропускная способность сети. Если максимальная скорость обмена кадрами между соседними маршрутизаторами будет x кадров в секунду и между двумя хостами имеется k непересекающихся путей, то, сколько бы ни было буферов у обоих хостов, они не смогут пересылать друг другу больше, чем kx сегментов в секунду. И если отправитель будет передавать с большей скоростью, то сеть окажется перегруженной.
Требуется механизм, который мог бы ограничивать передачу данных со стороны отправителя и основывался не столько на емкости буферов получателя, сколько на пропускной способности сети. В 1975 году Белснес (Belsnes) предложил использовать для управления потоком данных схему скользящего окна, в которой отправитель динамически приводит размер окна в соответствие с пропускной способностью сети. Таким образом, скользящее окно позволяет одновременно реализовать и управление потоком, и контроль перегрузки. Если сеть может обработать c сегментов в секунду, а время цикла (включая передачу, распространение, ожидание в очередях, обработку получателем и возврат подтверждения) равно г, тогда размер окна отправителя должен быть равен cr. При таком размере окна отправитель работает, максимально используя канал. Любое уменьшение производительности сети приведет к его блокировке. Так как пропускная способность сети меняется с течением времени, размер окна должен настраиваться довольно часто, чтобы можно было отслеживать изменения пропускной способности. Как будет показано ниже, в TCP используется похожая схема.
6.2.5. Мультиплексирование
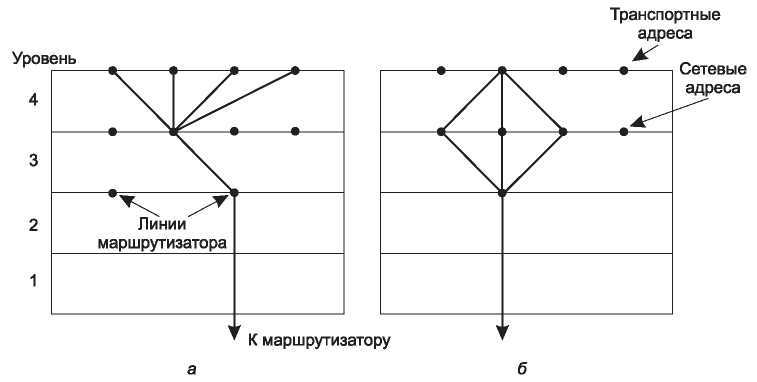
Объединение нескольких разговоров в одном соединении, виртуальном канале и по одной физической линии играет важную роль в нескольких уровнях сетевой архитектуры. Потребность в подобном уплотнении возникает в ряде случаев и на транспортном уровне. Например, если у хоста имеется только один сетевой адрес, он используется всеми соединениями транспортного уровня. Нужен какой-то способ, с помощью которого можно было бы различать, какому процессу следует передать входящий сегмент. Такая ситуация, называемая мультиплексированием, показана на рис. 6.14, а. На рисунке четыре различных соединения транспортного уровня используют одно сетевое соединение (например, один IP-адрес) с удаленным хостом.
Рис. 6.14. Мультиплексирование: а — прямое; б — обратное мультиплексирование
Уплотнение может играть важную роль на транспортном уровне и по другой причине. Предположим, например, что хост может использовать несколько различных сетевых путей. Если пользователю требуется большая пропускная способность или большая надежность, нежели может предоставить один сетевой путь, то можно попробовать решить эту проблему путем открытия соединения, распределяющего трафик между путями, используя их поочередно, как показано на рис. 6.14, б. Такой метод называется обратным мультиплексированием. При k открытых сетевых соединениях эффективная пропускная способность может увеличиться в k раз. Примером обратного мультиплексирования является SCTP (Stream Control Transmission Protocol — протокол передачи с управлением потоками), позволяющий устанавливать соединение с множественными сетевыми интерфейсами. TCP, наоборот, использует отдельный сокет. Обратное мультиплексирование используется и на канальном уровне — при этом несколько медленных каналов связи объединяются в один, работающий гораздо быстрее.
6.2.6. Восстановление после сбоев
Если хосты и маршрутизаторы подвержены сбоям или соединения длятся достаточно долго (например, при загрузке мультимедиа или программного обеспечения), вопрос восстановления после сбоев становится особенно актуальным. Если транспортная подсистема целиком помещается в хостах, восстановление после отказов сети и маршрутизаторов не вызывает затруднений. Транспортные подсистемы постоянно ожидают потери сегментов и знают, как с этим бороться: для этого выполняются повторные передачи.
Более серьезную проблему представляет восстановление после сбоя хоста. В частности, для клиентов может быть желательной возможность продолжать работу после отказа и быстрой перезагрузки сервера. Чтобы пояснить, в чем тут сложность, предположим, что один хост — клиент — посылает длинный файл другому хосту — файловому серверу — при помощи простого протокола с остановкой и ожиданием подтверждения. Транспортный уровень сервера просто передает приходящие сегменты один за другим пользователю транспортного уровня. Получив половину файла, сервер сбрасывается и перезагружается, после чего все его таблицы переинициализируются, поэтому он уже не помнит, что с ним было раньше.
Пытаясь восстановить предыдущее состояние, сервер может разослать широковещательный сегмент всем хостам, объявляя им, что он только что перезагрузился, и прося своих клиентов сообщить ему о состоянии всех открытых соединений. Каждый клиент может находиться в одном из двух состояний: один неподтвержденный сегмент (состояние S1) или ни одного неподтвержденного сегмента (состояние S0). Этой информации клиенту должно быть достаточно, чтобы решить, передавать ему повторно последний сегмент или нет.
На первый взгляд, здесь все очевидно: узнав о перезапуске сервера, клиент должен передать повторно последний неподтвержденный сегмент. То есть повторная передача требуется тогда и только тогда, когда клиент находится в состоянии S1. Однако при более детальном рассмотрении оказывается, что все не так просто, как мы наивно предположили. Рассмотрим, например, ситуацию, в которой транспортная подсистема сервера сначала посылает подтверждение, а уже затем передает пакет прикладному процессу. Запись сегмента в выходной поток и отправка подтверждения являются двумя различными неделимыми событиями, которые не могут быть выполнены одновременно. Если сбой произойдет после отправки подтверждения, но до того как выполнена запись, клиент получит подтверждение, а при получении объявления о перезапуске сервера окажется в состоянии S0. Таким образом, клиент не станет передавать сегмент повторно, так как будет считать, что сегмент уже получен, что в конечном итоге приведет к отсутствию сегмента.
В этом месте вы, должно быть, подумаете: «А что если поменять местами последовательность действий, выполняемых транспортной подсистемой сервера, чтобы сначала осуществлялась запись, а потом высылалось подтверждение?» Представим, что запись сделана, но сбой произошел до отправки подтверждения. В этом случае клиент окажется в состоянии S1 и поэтому передаст сегмент повторно, и мы получим дубликат сегмента в выходном потоке.
Таким образом, независимо от того, как запрограммированы клиент и сервер, всегда могут быть ситуации, в которых протокол не сможет правильно восстановиться. Сервер можно запрограммировать двумя способами: так, чтобы он сначала передавал подтверждение, или так, чтобы сначала записывал сегмент. Клиент может быть запрограммирован одним из четырех способов: всегда передавать повторно последний сегмент, никогда не передавать повторно последний сегмент, передавать повторно сегмент только в состоянии S0 и передавать повторно сегмент только в состоянии S1.