И фермеры продолжили дележку ряда: первую четвертинку разбили на две осьмушки, первую осьмушку – на две шестнадцатых и так далее, пока кусочек ряда не съежился до одного-двух арбузов. Этот кусочек они отсортировали моментально и пружина стала раскручиваться в обратную сторону. В конце концов, они вернулись к оставленным ранее частям ряда и отсортировали вторую осьмушку, вторую четвертинку и вторую половинку.
– Готово! – радостно выдохнул Райт. – Гляди-ка, ещё утренняя роса не просохла!
– Нич-ч-чо не понимаю, – сдался Лефт, – но ты, похоже, гений!
И приятели отправились завтракать.
Процедура быстрой сортировки
Друзья заслужили отдых, и теперь наш черед. Возьмем алгоритм Райта и проверим, так ли он хорош?
В целом алгоритм ясен, неясно лишь, как выбрать средний арбуз? В идеале его вес должен быть таким, чтобы половина арбузов в сортируемой части массива была легче среднего, а другая половина – тяжелее. Только тогда массив будет разрублен строго пополам. Увы! У нас нет простого способа найти вес такого арбуза! Даже усреднив веса арбузов в сортируемой части, мы можем не угадать это число.
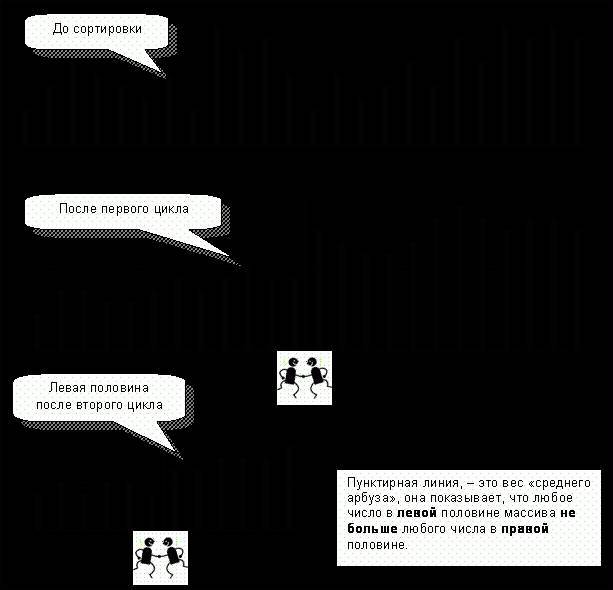
К счастью, все не так уж плохо. Опыт показал, что делить массив строго пополам совсем не обязательно. Например, при делении ряда в пропорции 1/3 и 2/3 сортировка почти не ухудшится. Значит, можно оценивать вес среднего арбуза «на глазок» (как это делал Райт). Будем вычислять его как среднее арифметическое для трех арбузов: двух крайних и того, что лежит в середине сортируемой части массива.
Тогда формула для определения веса среднего арбуза будет такой:
Средний вес := (Вес[L] + Вес[(L + R)/2] + Вес [R]) / 3;
Здесь L и R – индексы элементов для начала и конца сортируемой части массива. Повторяю, – это лишь один из возможных вариантов определения среднего веса.
Рис. 95 – Изменения массива при «быстрой» сортировке
Вы принимаете эту формулу? Тогда перейдем к процедуре быстрой сортировки по имени QuickSort (Quickly – «быстро», Sort – «сортировка»). Вот она вместе с проверяющей её программой.
{ P_43_2 QuickSort – Быстрая сортировка }
const CSize=10; { размер массива }
type TNumbers = array [1..CSize] of Integer;
var Arr : TNumbers;
{ Процедура быстрой сортировки }
procedure QuickSort(var arg: TNumbers; aL, aR: Integer);
var
L, R : integer; { левый и правый индексы }
M, T : Integer; { среднее значение и временное хранилище }
begin
{ Начальные значения левого и правого индексов }
L:= aL; R:= aR;
{ Вычисляем среднее по трём (порог для сравнения ) }
M:= (arg[L] + arg[(L + R) div 2] + arg[R]) div 3;
repeat { Цикл встречного движения }
{ Пока левый элемент меньше среднего,
двигаем левый индекс вправо }
while arg[L] < M do L:=L+1;
{ Пока правый элемент больше среднего,
двигаем правый индекс влево }
while arg[R] > M do R:=R–1;
{ После остановки сравниваем индексы }
if L <= R then begin
{ Здесь индексы ещё не "встретились", поэтому,
если левый элемент оказался больше правого,
меняем их местами }
if arg[L]>arg[R] then begin
t:= arg[L]; arg[L]:= arg[R]; arg[R]:= t;
end;
{ Индексы «делают шаг» навстречу друг другу }
L:=L+1; R:=R-1;
end;
until L > R; { пока индексы не "встретятся" }
{ если левая часть не отсортирована, то сортируем её }
if R > aL then QuickSort(arg, aL, R);
{ если правая часть не отсортирована, то её тоже сортируем }
if L < aR then QuickSort(arg, L, aR);
{ выход после сортировки обеих частей }
end;
{ Процедура распечатки массива, arg – строка сообщения }
procedure ShowArray(const arg: string);
var i: integer;
begin
Writeln(arg);
for i:=1 to CSize do Writeln(Arr[i]);
Readln;
end;
var i: integer;
begin {--- Главная программа ---}
{ Заполняем массив случайными числами }
for i:=1 to CSize do Arr[i]:=1+Random(1000);
ShowArray('До сортировки:');
QuickSort(Arr, 1, CSize);
ShowArray('После сортировки:');
end.
Взгляните на параметры процедуры QuickSort. Вместе со ссылкой на массив, в процедуру передаются левая (aL) и правая (aR) границы сортируемой части массива (индексы). В процедуре вычисляется вес среднего арбуза по выбранной нами формуле и организуется поочередное встречное движение левого и правого индексов.
Самое интересное происходит после «встречи» индексов, когда массив разбит на две части. Удивительно, что теперь снова дважды вызывается та же самая процедура QuickSort: сначала для левой части массива, а затем – для правой (эти операторы выделены курсивом). Вспомните, – точно так же поступали и фермеры при сортировке арбузов.
«Так там фермеры, а здесь Паскаль! Позволено ль процедуре вызывать саму себя?» – слышу недоверчивый вопрос. Мы свыклись с тем, что из одной процедуры вызывают другую, из второй, – третью и так далее. Но чтобы саму себя? Это ж змея, глотающая свой хвост! Не оттого ли запутался фермер Лефт?
О рекурсии и стеке
Такой самовызов процедур называют рекурсией. «У попа была собака…» – помните? Это рекурсия, познакомимся с нею ближе (с рекурсией, а не собакой).
Легко заметить, что повторные вызовы процедуры QuickSort выполняются с другими значениями левой и правой границ. Чем глубже вызов, тем уже эти границы. С некоторого момента условия (R > aL) и (L < aR) перестают выполняться, и происходит выход из процедуры, – здесь фермеры возвращаются к несортированным частям массива. Таким образом, при выходе мы снова попадаем в эту же процедуру, но в другое место – следующее за вызовом. Окончательный выход из процедуры в главную программу случится только по завершении сортировки всего массива!
Напрашивается вопрос: какова судьба локальных переменных и параметров при повторных входах в процедуру? Ведь они изменятся, а это должно нарушить работу процедуры. Параметры и локальные переменные действительно изменяются, но это не путает алгоритм. Почему?
Разгадка в том, что при каждом входе в процедуру для её параметров и локальных переменных выделяется новый участок памяти. Теперь это будут уже другие параметры и локальные переменные, но с прежними названиями. Однако предыдущие их значения не теряются, а сохраняются в памяти, называемой стеком (Stack).
Что такое стек и как он работает? Случалось ли вам паковать рюкзак или глубокую сумку? Тогда вы знакомы со стеком. Все, что уложено в рюкзак, будет извлекаться из него в обратном порядке. Так же устроен и стек: при каждом вызове процедуры память для параметров и локальных переменных выделяется на его вершине. Эти новые значения временно закрывают предыдущие значения параметров, и так происходит при каждом входе в процедуру.
При выходе из неё последние значения параметров и локальных переменных удаляются с вершины стека, и тогда вновь открываются ранее скрытые. Так процедура «вспоминает» о неоконченной работе, и продолжает действия с параметрами, сохраненными в стеке ранее. В некоторый момент стек пустеет (когда все вещи из рюкзака вынуты), и тогда происходит окончательный выход из процедуры в главную программу.