Коротко о статистике
В этом разделе я вкратце познакомлю читателей с азами статистики, чтобы облегчить им дальнейшее чтение книги.
Я знаю, что не все люди обладают математическими способностями. Я также знаю, что многие считают статистику скучной или невероятно сложной. Между тем в этой книге много статистики. Но хочу вас успокоить: форма ее подачи предельно проста. Это не значит, что данные будут представлены в упрощенном виде; это значит, что я стану их использовать только для того, чтобы проиллюстрировать результаты исследований. Например, если я пишу, что рост оказался значительным, то могу доказать это с помощью таблицы, где будет указана цифра 572 %. Это позволит судить о масштабе произошедших изменений.
Несколько основных терминов
Чтобы успокоить вас еще больше, ниже я объясню некоторые статистические термины, релевантные для нашего контекста. Иногда в книге могут встречаться отклонения от представленных здесь рассуждений, и я обязательно буду обращать ваше внимание на такие моменты.
Статистическая значимость
На протяжении всей книги вам регулярно будет встречаться термин «статистическая значимость». Если результат является статистически значимым, например, на уровне 5 %, значит, вероятность того, что он мог появиться чисто случайно, составляет всего 5 %. В этой книге вы встретите следующие уровни статистической значимости: 1 % (в таблицах обозначается символами ***), 5 % (**) и иногда 10 % (*).
Но из этого основного правила есть исключения. В некоторых случаях, когда я ставлю одну звездочку (*), фактически уровень статистической значимости может находиться где-то между 1 % и 10 %. Иногда я вынужден так делать просто потому, что в оригинальной статье данный показатель не был указан. С этим вы столкнетесь уже в таблице 2.1.
Статистическая значимость также может быть выражена в виде р-уровня. В этом случае используется латинская буква p, что является сокращением слова probability – вероятность. P-уровень, равный 0,01, соответствует статистической значимости в 1 % и означает, что вероятность ошибки – случайного возникновения результата – составляет 1 % и меньше. Это можно записать как p ≤ 0,01. Преимущество такого способа записи по сравнению со звездочками в том, что можно точно указать значение p-уровня, например: p ≤ 0,07. Чем меньше цифра, тем ниже вероятность того, что данный результат появился чисто случайно. Преимущество использования звездочек в том, что они занимают меньше места в таблицах. Вы просто должны знать об обоих способах.
Регрессионный анализ
Многие термины говорят сами за себя, например такой, как «сравнение средних значений». Даже неосведомленный человек может примерно понять, о чем идет речь. Сравнение средних значений будет приводиться во многих таблицах. С другой стороны, термин «регрессионный анализ» у многих вызывает страх – причем абсолютно необоснованно, поскольку за ним скрывается довольно простая вещь. Для пользователей статистики главная проблема состоит в понимании, какой метод что делает и что для этого требуется. Понять результаты, как правило, довольно легко.
В этой книге будет представлено несколько таблиц, содержащих результаты регрессионного анализа. Они могут выглядеть, как таблица 1.1. Ее вы увидите снова в главе 7.
Таблица 1.1. Пример результатов регрессионного анализа
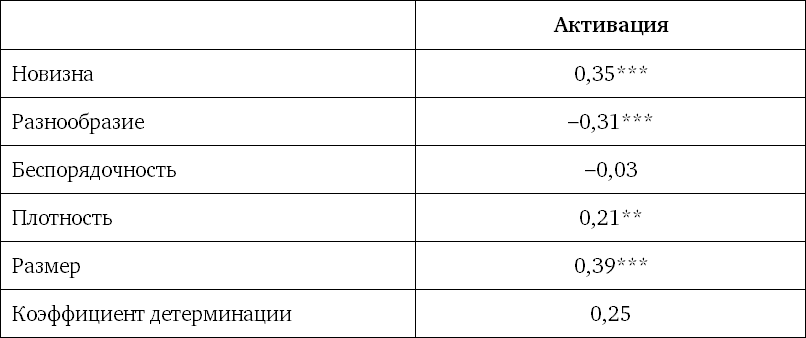
Главное, что вы должны знать о регрессионном анализе: он представляет собой метод моделирования измеряемых данных с целью исследования, как некая независимая переменная или несколько переменных (множественная регрессия) влияют на некую зависимую переменную. В таблице 1.1 в качестве последней выступает «активация». Зависимая переменная почти всегда указывается в верхней строке таблицы. Ниже идут независимые (объясняющие) переменные. Их также называют коэффициентами регрессии. В таблице 1.1 мы видим, что «беспорядочность» не статистически значимая величина, поэтому мы ее просто проигнорируем. Остальные факторы являются статистически значимыми. Значение коэффициента показывает, какое влияние на «активацию» оказывает его увеличение на одну единицу. Если степень новизны повышается на одну единицу, активация возрастает на 0,35. Как видите, все просто. Чем выше значение статистически значимого коэффициента регрессии, тем интереснее для нас этот коэффициент.
Коэффициент детерминации (R2) показывает, какая доля вариаций зависимой переменной объясняется моделью. Вероятно, не все поняли эту фразу, поэтому ниже я постараюсь объяснить ее значение.
Чтобы немного упростить, используем следующий пример. Предположим, большое количество покупателей заполняет анкету о степени активации. Ответы даются по шкале от 1 до 7. Также при помощи шкалы они оценивают, в какой степени воспринимаемая ими обстановка в магазине является «новой», «разнообразной» и т. д. (см. таблицу 1.1). Окажется, что одни люди испытывают более высокую степень активации, другие – более низкую. Эта величина будет в разной степени коварьировать с разными объясняющими переменными. Например, если большинство тех, кто указал высокую степень активации, также отметили, что воспринимают пространство магазина как большое, то ковариация будет высокой. Если нет никакой взаимосвязи между объясняющей переменной и зависимой – например, обстановка в магазине охарактеризована как «беспорядочная», а степень активации названа высокой, – ковариация будет низкой.
В этом случае высокая степень активации может быть вызвана другими причинами, неуказанными в анкете (и, соответственно, не включенными в модель в качестве объясняющих переменных). Возможно, здесь сыграли роль личные психологические факторы, стало быть, изменение данной величины не будет определяться объясняющими переменными. Как показано в таблице 1.1, коэффициент детерминации (объясняющее значение) модели составляет 25 % (R2 = 0,25). Другими словами, 25 % вариаций степени активации объясняются независимыми переменными, включенными в модель. Остальные 75 % зависят от других факторов. Исследователи в сфере розничной торговли всегда стремятся достичь максимально высокого значения коэффициента R2.
Как организована эта книга
Книга состоит из четырех частей. Первая проливает свет на то, как покупатели принимают решения, находясь непосредственно в магазине (глава 2). Задача главы 2 – заложить фундамент для восприятия книги. Без ее прочтения нельзя извлечь максимум пользы из остального материала. В других частях книги вы, например, узнаете, что можно повысить продажи зубных щеток, если разместить их под зубной пастой (глава 3), можно заставить покупателей платить больше, если расположить товар на синем фоне (глава 8), и что люди будут покупать больше, если заставить их ходить по магазину против часовой стрелки (глава 8). Если вы не прочитаете главу 2, то попросту не поймете, почему эти приемы действуют таким образом.
В остальном книга похожа на сборную солянку. Разные главы являются более-менее самостоятельными, и их можно читать в любой очередности. В конце имеется несколько приложений, цель которых – снабдить читателей дополнительными сведениями в тех случаях, когда я счел это необходимым. Идея состоит в том, чтобы вам не нужно было рыться в других книгах в поисках дополнительной информации; кроме того, здесь же приводится краткий обзор литературы на соответствующую тему.
После вводной первой части, посвященной процессу принятия решений покупателями, следует вторая, состоящая из четырех глав. Здесь будет рассмотрена, пожалуй, самая важная тема – «содержание» магазина, т. е. его ассортимент, а также вопросы, связанные с выкладкой товара, расположением, ролью цвета и т. д.