Составление семантического ядра
Как создается семантическое ядро или поле для подавляющего большинства русскоязычных сайтов?
Обычно все начинается с клиента, который приходит в веб-студию или к штатному специалисту и просит создать сайт, посвященный тому, что продает его бизнес. В лучшем случае к такому заданию будет приложен полный каталог или прайс-лист, в худшем – предложено сделать в точности как у компании N, только лучше.
Семантическое ядро в таких случаях создается стихийно. Это некритично – после того как сайт попадет на продвижение к грамотному специалисту, он все равно получит нормальное семантическое ядро, в соответствии с которым будет осуществляться продвижение. Проблема лишь в том, что в этом случае сложность и стоимость продвижения вырастут. Применительно к порталу рост затрат на продвижение может быть очень значительным, а потому созданием семантического ядра имеет смысл заняться на этапе проектирования сайта.
Почему нельзя составлять семантическое ядро на основе прайс-листа или каталога?
Причин две:
□ ядро будет составляться на основе предложения, а не реального спроса, что даст заметную погрешность в оценке сложности продвижения отдельных запросов;
□ многие сущности, прямо в каталоге не упомянутые, но имеющие к нему отношение, не будут упомянуты и при составлении ядра.
При этом нельзя сказать, что прайс-лист и каталог в принципе бесполезны. Они все же дают общее представление о предмете продвижения, но не более того.
Как собирать семантическое ядро? Для сборки семантического ядра используются два главных инструмента – Excel и wordstat.yandex.ru. Если мы хотим узнать, что и как ищут в «Яндексе», логичнее всего спросить у него самого. Разумеется, данные сервиса необходимо уметь интерпретировать, однако при грамотном подходе он дает массу полезной информации. И, конечно же, не стоит забывать об автоматизации – использовать wordstat.yandex.ru для ручного сбора семантики для портала очень трудоемко. Пригодится также знание предметной области.
Сбор семантики начинают с наиболее общего запроса – пусть это будет «мебель». Компонуем в таблицу все, что дает wordstat.yandex.ru по этому запросу, и одновременно в правой колонке создаем список типов мебели: диваны, кресла и т. д. Собираем запросы по каждому из типов, одновременно вычленяя попадающиеся мебельные бренды. Затем собираем запросы, связанные с мебельными брендами.
Следующий этап – производные прилагательные сначала от слова «мебель» («мебельный», «мебельная»), затем от типов («диванный»). Это даст еще некоторое количество запросов.
Отдельный сегмент – аксессуары. Запросы, связанные с аксессуарами, есть во всех товарных тематиках, но очень часто их просто упускают из виду.
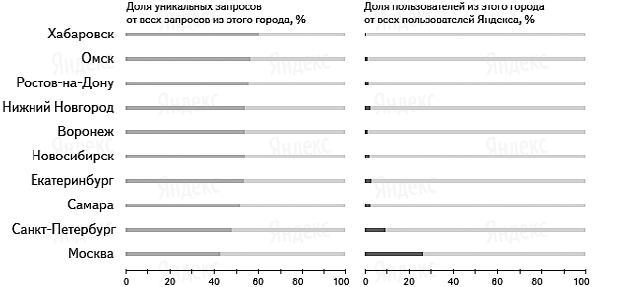
Wordstat.yandex.ru и уникальные запросы. На рис. 3.2 приведен результат довольно масштабного исследования, которое проводили сотрудники «Яндекса». Объектом исследования были пользовательские запросы. Подробнее: http://company.yandex.ru/researches/reports/ ya_regions_search_2010.xml.
Рис. 3.2
Мы видим, что в крупных городах доля трафика по уникальным запросам достигает 50 %. Уникальные запросы – это запросы, которые вводятся в течение суток не больше одного раза: таким образом, их частотность не превышает 30 %. Это означает, что подавляющее большинство таких запросов вообще не фигурирует в wordstat.yandex.ru. Для описанного ранее способа сбора семантики их просто нет, но они дают около 50 % трафика. С точки зрения составления семантического ядра их отсутствие в wordstat.yandex.ru является большим недостатком последнего, но не следует забывать, для чего на самом деле создавался этот сервис.
Возникает вопрос: как охватить эти уникальные запросы?
Прямых и простых решений, позволяющих получить эти запросы, нет, но есть некоторые не самые очевидные возможности:
Сервис ADVSe содержит информацию о запросах, по которым сайты ваших конкурентов продвигаются с помощью контекстной рекламы.
Анализ собственного трафика. Для сбора запросов, по которым пользователи пришли на ваш сайт, лучше использовать access.log, в котором гарантированно сохраняются все запросы. Счетчики, построенные на JavaScript, теряют около 20 % запросов, что делает их простым, но не совсем надежным источником. По поводу полноты данных, представляемых метрикой «Яндекса», также есть некоторые сомнения, а вот access.log никогда не обманет вас – необходимо лишь написать модуль, который будет анализировать его и собирать необходимые данные.
Статистика внутреннего поиска. Далеко не все сайты имеют мощный внутренний поиск, но если он есть, вы можете использовать запросы внутреннего поиска для пополнения семантического ядра.
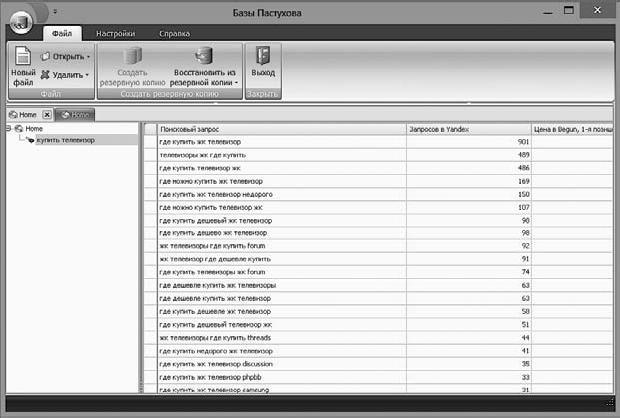
Базы запросов. База Пастухова – это база русскоязычных запросов, состоящая из более чем 210 млн запросов с указанием частотности в основных поисковых системах (рис. 3.3). В отличие от wordstat.yandex.ru база Пастухова учитывает все словоформы, что очень полезно при подборе обширного семантического ядра. База поставляется с собственным интерфейсом (оболочкой) и в виде текстового файла. Работать с таким количеством запросов вручную крайне сложно, поэтому придется задействовать программиста, который может создать собственный интерфейс, подходящий для решения конкретных задач.
База Пастухова – лучшая, но не единственная. Не упускайте возможности купить интересную тематическую базу и пополнить ядро новыми запросами.
Подсказки поисковых систем. Подсказки часто дают свежие актуальные запросы, связанные с недавно возникшими пользовательскими интересами. Зачастую такие запросы низкоконкурентны, но дают хороший трафик.
Рис. 3.3
FastKeywords.biz – сервис, предоставляющий базы запросов, введенных в течение дня (рис. 3.4). Можно использовать как дополнительный источник данных.
Подбор запросов в «Яндекс.Директ» (не в сервисе wordstat.yandex.ru, а при создании объявления непосредственно в аккаунте). Ассоциативный подбор родственных запросов, размещенный там, предлагает такие запросы, которые никогда не найдет wordstat.yandex.ru.
Предсказание запросов. Если вы получили запрос «как работает экспозамер в Nikon D7000», есть некоторые шансы, что в природе существуют также запросы «как работает экспозамер в…». Поскольку моделей фотоаппаратов много, запросов тоже получается много. К слову, закрыть их можно автоматическим созданием контента – необходимо лишь, чтобы формулу для генерирования создавал кто-то, знакомый с предметной областью.
В результате такого массированного сбора семантики мы получаем обширный список, который может содержать несколько десятков тысяч (в отдельных случаях несколько миллионов) запросов. Разумеется, в этом списке велика доля пустых запросов, которые никогда не принесут трафика. Поэтому следующий этап – чистка семантического ядра.
Чистка семантического ядра
Необходимость чистки семантического ядра связана с наличием в статистике wordstat.yandex.ru пустых, накрученных и неконверсионных запросов.
Рис. 3.4
Пустые запросы – это запросы, которые не приносят трафика, но при этом имеют неплохие показатели в статистике wordstat.yandex.ru.
Большое количество пустых запросов в этом сервисе связано с его назначением и механизмом работы. Ведь предназначен wordstat.yandex.ru не для формирования семантического ядра, а для работы с контекстной рекламой. Специфика же контекстной рекламы заключается в том, что система пытается обеспечить максимальный охват по ключевому слову. Таким образом, покупая клики по ключевому слову «мебель», мы получим показы по всем запросам с вхождением этого слова вплоть до «какую мебель любил Петр Великий». Это составляет определенную проблему для специалистов по контексту, однако с точки зрения сбора семантики для нас важно другое – то, что wordstat.yandex.ru работает аналогичным образом. Говоря иными словами, показатель просмотров по результату запроса «мебель» представляет собой сумму всех просмотров с вхождением этого слова. При этом собственно запрос может приносить очень мало трафика или не приносить вообще. В случае если трафик очень мал, а статистика показывает большие цифры, мы можем говорить о пустом запросе.