Вообще-то я не уверен, что мы сделали правильное предположение. В текстах часто встречаются совпадения и реверсии, особенно если смысл строк при этом не меняется. Средневековый переписчик наверняка не испытывал угрызений совести, изменяя написание, и еще меньше его волновали вставки или удаления знаков, например косой черты. В этом случае информативнее такие изменения, как перестановка слов. В генетике аналогами таких изменений являются “редкие геномные изменения”: крупные вставки, делеции и дупликации ДНК. Мы можем оценить информативность, присвоив большее или меньшее значение (вес) различным типам признаков. Недостоверные или слишком частые изменения при подсчете будут иметь меньший вес. А редкие изменения, которые служат надежными показателями родства, – больший вес. Повышенный вес признака говорит о том, что мы не хотим учитывать его дважды. Таким образом, наиболее экономное древо – то, которое имеет наименьший общий вес.
Метод парсимонии широко используется для поиска эволюционных деревьев. Но в том случае, когда конвергенций и реверсий слишком много – а это случается и с последовательностями ДНК, и с текстами Чосера, – метод парсимонии может оказаться недостоверным. Эта проблема известна как “эффект притяжения длинных ветвей”.
Кладограммы – как укорененные, так и неукорененные – отражают лишь порядок ветвления. Филограммы, или филогенетические деревья, похожи на кладограммы, но в них длина ветвей несет дополнительную информацию. Обычно длина ветвей отражает эволюционное расстояние: длинные ветви обозначают крупные изменения, а короткие – мелкие. На основе первой строки “Кентерберийских рассказов” можно построить следующую филограмму.
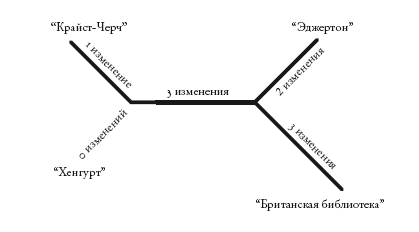
Здесь длина ветвей не слишком различается. Но представьте, что будет, если два манускрипта сильно отличаются от двух других. Тогда ветви первых манускриптов будут очень длинными. Однако изменения могут оказаться не уникальными. Изменения могут случайно оказаться идентичными изменениям в другом месте древа. Но с наибольшей вероятностью (именно в этом заключается проблема) они совпадут с изменениями на другой длинной ветви. Ведь длинные ветви – это те, в которых произошло наибольшее число изменений. И если изменений окажется слишком много, две длинные ветви на филограмме будут отображаться как родственные, даже если это не так. Таким образом, метод парсимонии, основываясь на простом подсчете изменений, может ошибочно сгруппировать две самые длинные ветви, “притянуть” их друг к другу.
Эффект притяжения длинных ветвей – серьезная помеха для систематики. Он проявляется везде, где много конвергенций и реверсий. К сожалению, эту проблему нельзя решить простым увеличением объема рассматриваемого текста. Наоборот, чем больше текст, тем выше вероятность обнаружения случайных совпадений. Про такие деревья говорят, что они лежат в “зоне Фельзенстайна” (звучит устрашающе!), названной в честь американского биолога Джо Фельзенстайна. Увы, ДНК особенно подвержена эффекту притяжения длинных ветвей. Основная причина в том, что в ДНК всего четыре “буквы”. Поскольку большинство изменений затрагивают всего одну “букву”, случайные мутации с высокой вероятностью могут привести к совпадениям. Так возникает притяжение длинных ветвей. Очевидно, что для таких случаев нужна альтернатива методу парсимонии. Она существует – это метод правдоподобия. В последнее время он используется все чаще.
Оценка правдоподобия требует больше вычислительных мощностей, чем метод парсимонии, поскольку здесь мы учитываем длину ветвей. Таким образом, приходится иметь дело с еще большим количеством деревьев: вдобавок к рассмотрению возможных схем ветвления мы должны учитывать возможные длины ветвей. Геркулесов труд! Поэтому, несмотря на упрощенные методы вычисления, компьютеры пока могут подвергнуть анализу небольшое количество видов.
Термин “правдоподобие” здесь имеет вполне точное значение. Возьмем древо определенной формы (с учетом длины ветвей). Из всех возможных эволюционных траекторий, посредством которых может сформироваться филогенетическое древо данной формы, всего несколько могут привести к тому тексту, который мы сейчас видим. "Правдоподобие” данного древа – это ничтожно малая вероятность получения реально существующих текстов, а не каких-нибудь текстов, которые могут появиться на таком древе. Величина правдоподобия для древа очень мала, однако это не мешает сравнить одну малую величину с другой, чтобы выбрать нужную.
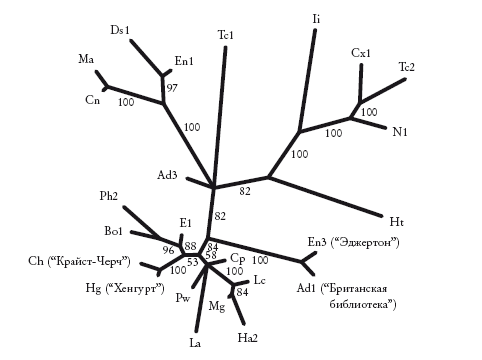
Неукорененное филогенетическое древо первых 250 строк 24 списков "Кентерберийских рассказов". Здесь представлен набор списков, изученный в рамках проекта "Кентерберийские рассказы". Сокращения соответствуют тем, что использованы в проекте. Схема построена методом парсимонии, на каждой ветви указаны индексы бутстреп-поддержки. Для четырех списков, которые обсуждаются нами, указаны их полные названия.
Выбирать "лучшее” древо методом правдоподобия можно по-разному. Самый простой способ – искать наиболее правдоподобное древо. Это метод максимального правдоподобия. Однако то, что это наиболее правдоподобное древо, вовсе не означает, что другие деревья не окажутся почти столь же правдоподобными. Совсем недавно было предложено не искать одно самое правдоподобное древо, а рассматривать все возможные. При этом степень "доверия” к древу должна зависеть от его правдоподобия. Этот подход представляет собой альтернативу методу правдоподобия и известен как байесовский метод. Если схема ветвления подтверждается большим количеством правдоподобных деревьев, мы заключаем, что эта схема с высокой вероятностью верна. Конечно, как и в методе максимального правдоподобия, мы не можем проверить все деревья. Но существуют способы упрощения вычислений, и они довольно неплохо работают.
Степень нашего доверия древу, которое мы в итоге выберем, зависит от того, насколько мы уверены в правильности каждого разветвления. Поэтому возле точек ветвления часто указывают степень “уверенности” в них. При использовании байесовского метода правдоподобие точек ветвления вычисляется автоматически, однако для других методов, таких как парсимония или максимальное правдоподобие, необходимы альтернативные способы подсчета. Чаще всего используют метод бутстрепа: многократно обсчитываются выборки данных, и оценки сравниваются с результатами для всего древа. Так мы можем понять, насколько древо устойчиво к ошибкам. Чем больше индекс бутстреп-поддержки, тем надежнее точка ветвления. Правда, точно интерпретировать полученные индексы бывает непросто. По сходному алгоритму работают методы “складного ножа” (jackknife) и “поддержки Бремера”. Все они служат для оценки достоверности точек ветвления.
Прежде чем оставить литературу, рассмотрим итоговое древо, построенное для первых 250 строк в 24 манускриптах Чосера. Это филограмма, на которой информативна не только схема ветвления, но и длина ветвей. На схеме видно, какие списки почти идентичны, а какие сильно отличаются от остальных. Эта филограмма неукорененная, то есть не указывает на то, какой из 24 манускриптов ближе всех к “оригиналу”.
Вернемся к гиббонам. Принцип парсимонии предполагает существование четырех групп. Ниже приведена укорененная диаграмма, основанная на морфологических признаках. Здесь виды рода Hylobates (настоящие гиббоны) группируются вместе, как и виды рода Nomascus. Обе группы поддерживаются высокими индексами бутстреп-поддержки (указаны над ветвями). Однако в нескольких местах порядок ветвлений не определен. Хотя Hylobates и Bunopithecus вроде бы формируют группу, индекс бутстреп-поддержки (63) представляется неубедительным для тех, кто умеет читать подобные руны. Морфологических признаков для построения древа недостаточно.