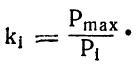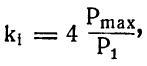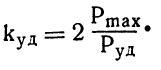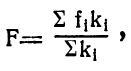Однако самая большая разница в информативности звуков слова вызвана обстоятельством, которое мы, казалось бы, не замечаем, а именно — разницей в частотности, или встречаемости, звукобукв в речи. Опять-таки, как и часто повторяющиеся события становятся обычными, теряют информативность, как слова от частого повторения «в привычку входят, ветшают, как платье», так и часто встречающиеся в речи звуки тоже оказываются малоинформативными, не задерживают на себе внимания, а значит, и незначительно влияют на восприятие слова, на формирование его фоносемантического ореола.
Редкие события высокоинформативны, они останавливают на себе внимание, выделяются из общего потока. И если в слове встречается редкий звук, он переключает на себя внимание воспринимающего, его содержательность становится доминирующей. И чем больше разница в частоте встречаемости между частыми и редкими звуками слова, тем выше информативность редких звуков, тем больше нужно увеличивать вес их средних оценок по сравнению со средними оценками остальных звуков.
Все эти расчеты компьютер выполнит легко, но ему для этого нужны данные об употребительности звукобукв. Те сведения, которые имелись в печати, не совсем подходили — ведь нужны данные именно о звукобуквах, а не о звуках или о буквах, да еще и отдельно по ударным и безударным гласным, да еще в какой-то нейтральной «усредненной» речи. Пришлось вести подсчеты по разным текстам, записывать на диктофоны разговорную речь в разных ситуациях. Работа большая, однообразная, изнурительная. Но что делать, других путей не было.
Забегая вперед, следует сказать, что теперь и эту работу смог бы выполнить сам компьютер. Когда мы перешли от отдельных слов к целым текстам (о чем будет рассказано ниже), компьютер все равно подсчитывал вероятности звукобукв. Не удержусь и похвастаю: компьютерные подсчеты, проведенные на гигантском материале, мало что изменили в наших данных, полученных вручную тяжелым трудом на выборках несравненно более скромного размера. Но это так, к слову, и не в укор машине. Ведь сколько времени и сил пришлось потратить на эту в общем-то подсобную, подготовительную работу! А компьютер выполнил ее походя, играючи.
Но наконец готово все. Многократно выверена, уточнена и перепроверена основная таблица, содержащая средние оценки всех русских звукобукв по 20 признаковым шкалам. Готова и таблица вероятностей звукобукв. Теперь слово за компьютером. Вот тут уж с ним вручную не потягаешься. Ручной расчет фоносемантического ореола даже для одного слова по всем шкалам — дело длинное, а печать машины стрекочет безостановочно, успевай только перфокарты загружать. А если работать с дисплеем, то время расчета — это фактически время набора слова на алфавитной клавиатуре. Иначе говоря, компьютер, как и человек, моментально «схватывает» фоносемантику слова.
Для тех, кому нравится более строгое изложение схемы вычислений, приведем формулы, по которым работает компьютер.
Если частотность (вероятность) любого (i-того) звука слова обозначить как Рi, а максимальную частотность звука в данном слове как Рmax, то коэффициент, учитывающий разницу частотностей звуков слова ki , можно вычислить как отношение:
Теперь нужно учесть место каждого звука в слове. Для этого коэффициент первого звука слова (ki) увеличим в четыре раза:
а для ударного (Куд) — в два раза:
После этих приготовлений напишем основную формулу:
где F — фонетическая содержательность слова (его фоносемантика) ;
fi — фонетическая содержательность очередного (i-того) звука слова;
ki — коэффициент для очередного (i-того) звука слова;
Σ — знак суммы.
Последняя «примерка на манекенах» показывает, что все в порядке — схема расчета в общем верна. Информанты считают, что «слово» незич звучит как нечто «маленькое» и «нежное», а фрыш — как нечто «плохое, грубое, страшное», и компьютер дает примерно те же характеристики. По мнению информантов, хифель и уршух страшное, а лимень и нитис — безопасное; компьютер того же мнения. Вробар и вакам кажутся информантам сильными, и компьютер выдал для них тот же признак.
Значит, способ расчета можно переносить и на настоящие слова. Конечно, спасительная оглядка на информантов теперь невозможна, но компьютер уже научился правильно имитировать человеческое восприятие фоносе-мантического ореола слов. Использовать эти свои умения он может разнообразно, и некоторые из возможностей мы ниже обсудим.
В результате вычислений слово по каждой шкале получает суммарную оценку фоносемантики, выраженную в единицах пягиранговой измерительной шкалы, то есть такую же оценку, как и средняя оценка содержательности отдельного звука. По суммарной оценке, опять-таки точно так же, как и по средней оценке для отдельного звука, слово получает характеристику в терминах шкалы. Например, для слова дом по шкале «хороший — плохой» компьютер получил суммарную оценку 2,3. Оценка находится в левой («хорошей») значимой зоне шкалы «хороший — плохой», поэтому компьютер выбирает для характеристики фоносемантического ореола этого слова признак «хорошее». Другими словами, по «мнению» компьютера, имитирующего наше с вами восприятие фоносемантики, звучание этого слова (точнее, его звукобуквенная форма) производит впечатление чего-то «хорошего». А для слова хам вычислена суммарная оценка 3,8. Она располагается в правой («плохой») значимой зоне шкалы, поэтому компьютер «полагает», что звучание этого слова производит впечатление чего-то «плохого». И так по всем 20 шкалам.
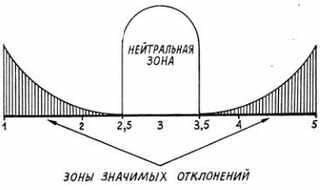
Значимые зоны школы определяются так, как показано на рисунке:
Если слово получает среднюю оценку от 1 до 2,5, то для характеристики качественного ореола слова выбирается левый признак шкалы (например, «хорошее»); если средняя оценка от 3,5 до 5, то в качестве характеристики выбирается правый признак (например, «плохое»); если оценка от 2,6 до 3,4, то никакого признака по данной шкале слово не получает.
На печать или на экран дисплея информацию можно вывести по-разному. Если нужно побольше информации, то лучше всего вывести и суммарные оценки, и выбранные характеристики. Можно также , для наглядности изобразить величину отклонений суммарных оценок от среднего (нейтрального) деления шкал.
Вся эта информация на экране дисплея имеет следующий вид:
РОБОТ
____________________________________________________
шкалы оценки признаки
хорошее 2,6
большое 1,9 большое
нежное 4,0 грубое
женственное 4,2 мужественное
светлое 3,2
активное 2,0 активное
сильное 1,8 сильное
быстрое 2,3 быстрое
красивое 2,7
гладкое 3,2
легкое 3,3
безопасное 3,7 страшное
величественное 2,0 величественное
яркое 2,1 яркое
округлое 3,2
радостное 2,7
громкое 1,9 громкое