По порядку: ирис щетинистый, ирис разноцветный и ирис виргинский.
В зависимости от формы и размеров лепестков и чашелистиков система способна определить, к какому виду принадлежат цветы.
Читатель, возможно, задается вопросом: почему для решения задачи об ирисах нельзя использовать методы статистики? И действительно, эта задача так проста, что ее можно решить классическими методами статистики, к примеру, методом главных компонент. Но обратите внимание, что перцептрон и статистические методы описывают две принципиально различные схемы рассуждений, и описанная перцептроном, возможно, точнее соответствует естественным рассуждениям.
При решении задачи об ирисах методами статистики мы получили бы правила вида «если длина лепестков находится на интервале между указанными значениями, а ширина — между другими указанными значениями, весьма вероятно, что выборка принадлежит к виду Х». Перцептрон же рассуждает следующим образом: «если длина лепестков находится на интервале между указанными значениями, а ширина — между другими указанными значениями, весьма вероятно, что выборка принадлежит к виду X. Но если чашелистики слишком коротки, то размеры лепестков уже не имеют значения, так как выборка будет принадлежать к виду У».
Иными словами, при взвешивании входных значений для принятия решений одни данные могут иметь больший вес, чем другие, однако при достижении предельных значений входные данные, ранее считавшиеся неважными, начинают играть важную роль.
Нейроны группируются…
Несмотря на прорыв, которым стало открытие перцептрона и грандиозные перспективы его применения, ученые вскоре обнаружили: перцептроны нельзя использовать для решения линейно неразделимых задач (к несчастью, именно к этой группе относится большинство задач реальной жизни). По этой причине в 1980-е годы в адрес нейронных сетей прозвучало немало критики, а участники дебатов порой переходили от научных рассуждений к личным оскорблениям оппонентов.
К великому разочарованию ученых, эти споры пришлись на «темные века» в истории искусственного интеллекта — период, отмеченный существенным снижением выделяемых средств на исследования в США и Европе.
Во-первых, общество поняло, что идеи, изображенные в «Космической одиссее 2001 года», еще долго не найдут воплощения. Во-вторых, американские государственные организации, которые возлагали большие надежды на искусственный интеллект, считая, что он поможет одержать верх в холодной войне, постигла неудача. Разочарование ждало и тех, кто связывал свои ожидания с системами автоматического перевода, крайне важными для изучения советских технических документов. Когда стала понятна неэффективность перцептронов для решения линейно неразделимых задач, финансирование исследований в этой области существенно снизилось. Однако ученые продолжили исследования, хотя и опасаясь насмешек со стороны недоброжелателей.
В течение многих лет считалось, что создание сверхразумных компьютеров, подобных HAL 9000 из фильма «Космическая одиссея 2001 года», более чем реально. Увы, вскоре наступило разочарование.
* * *
ЛИНЕЙНАЯ НЕРАЗДЕЛИМОСТЬ
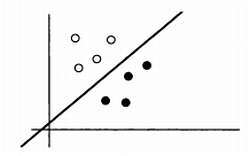
Рассмотрим ситуацию, когда выборки могут принадлежать к одной из двух категорий, каждая из которых описывается двумя дескрипторами (следовательно, двумя входными значениями).
Нарисуем график для восьми выборок.
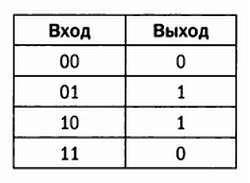
На этом графике кругами белого цвета отмечены выборки категории А, черными — выборки категории В. Нетрудно провести линию, разделяющую категории, — именно эту операцию проводит перцептрон при корректировке порогового значения и весов входных значений. Но что произойдет, если мы рассмотрим синтетическую задачу, предметом которой является операция XOR? XOR — это логическая операция, соответствующая исключающему «или», которая описывается следующим соотношением:
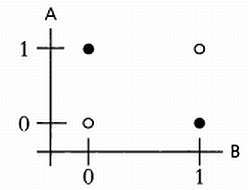
Теперь график будет выглядеть так:
Теперь уже нельзя провести линию, отделяющую белые круги от черных, следовательно, эта задача является линейно неразделимой. Перцептрон нельзя корректно обучить для решения такой простой логической задачи, как задача XOR.
* * *
Решение проблемы линейной неразделимости было найдено в конце 80-х годов.
Оно было столь очевидным и естественным, что даже странно, почему никто не додумался до него раньше. Решение нашла сама природа еще несколько миллионов лет назад: достаточно связать между собой различные перцептроны, сформировав так называемую нейронную сеть.
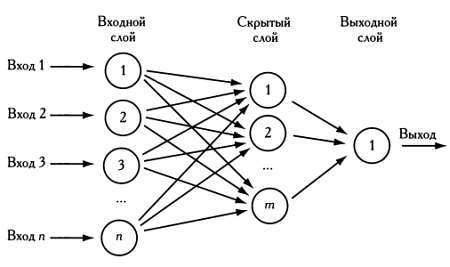
На следующем рисунке изображена нейронная сеть, состоящая из трех слоев нейронов: первый слой — входной, второй — скрытый, третий и последний — выходной. Эта нейронная сеть называется сетью прямого распространения, так как поток данных в ней всегда направлен слева направо, а синапсы не образуют циклов.
Нейронная сеть может быть сколь угодно сложной, иметь произвольное число скрытых слоев и, кроме того, содержать связи, которые идут в обратном направлении и тем самым моделируют некую разновидность памяти. Ученые построили нейронные сети, содержащие до 300 тысяч нейронов — столько, сколько содержит нервная система земляного червя.
В нейронной сети процесс обучения усложняется, поэтому инженеры разработали множество методов обучения. Один из самых простых — метод обратного распространения ошибки, давший название отдельной разновидности нейронных сетей, в которой он используется. Суть этого метода состоит в снижении ошибки выходного значения нейронной сети путем корректировки весов входных значений синапсов в направлении справа налево по методу градиентного спуска. Иными словами, сначала весам всех синапсов нейронной сети присваиваются произвольные значения, после чего на вход сети подается выборка, выходное значение для которой известно (такая выборка называется обучающей). Как и следовало ожидать, в этом случае выходное значение будет случайным. Далее, начиная с нейронов, близких к выходу, и заканчивая нейронами входного слоя, начинается корректировка весов связей.
Цель этой корректировки — приблизить выходное значение нейронной сети к реальному известному значению.
Эта процедура повторяется несколько сотен или тысяч раз для всех обучающих выборок. Когда обучение для всех выборок завершено, говорят, что прошла эпоха обучения. Далее процесс обучения может быть повторен на протяжении еще одной эпохи для тех же обучающих выборок. Как правило, при обучении рассматривается несколько десятков выборок. Этот процесс подобен реальному обучению, когда человек вновь и вновь видит одни и те же данные.
* * *
ОПАСНОСТЬ ПЕРЕОБУЧЕНИЯ
Система прогнозирования, в которой применяется машинное обучение, формулирует прогнозы путем обобщения предшествующего опыта. Следовательно, система, неспособная совершать обобщения, становится бесполезной.
Если процесс обучения повторяется слишком много раз, наступает момент, когда веса подобраны столь точно и система настолько адаптировалась к обучающим выборкам, что прогнозы формулируются не путем обобщения, а на основе запомненных случаев. Система становится способной выдавать корректные прогнозы для обучающих выборок, но всякий раз, когда на вход будет подаваться иная выборка, полученный прогноз окажется некорректным. Такая ситуация называется переобучением.
Нечто похожее происходит с ребенком, который не учится умножать, а запоминает таблицу умножения. Если мы попросим его найти произведение двух чисел из таблицы, он ответит без запинки, но если мы попросим его перемножить два других числа, ребенок задумается.