Особыми случаями являются так называемые устанавливаемые и выбираемые признаки (см. ниже). Эти качества можно отнести к аддитивности или к измеримости. Описывать их удобнее, когда рассматривается измеримость, а использовать – как специальный случай аддитивности.
Измеримость
Признаки почерка по тому, как мы их численно оцениваем, делятся на измеряемые, оцениваемые, выбираемые и устанавливаемые.
Измеряемые признаки. В начале XX века, когда графология стала интенсивно развиваться, было введено понятие «графометрия». Так стали называть дисциплину, которая основывалась на непосредственном измерении характеристик почерка. Действительно, так можно добиться и объективности, и точности. О многих (но не обо всех) признаках почерка можно судить на основе измерений. В первую очередь, к измеряемым признакам относятся различные размеры почерка. Такие, как высота и ширина букв, расстояния между буквами, словами, строками, длина верхних и нижних петель, размеры полей. Но измерения участвуют в анализе и таких признаков, как форма полей, наклон букв и линия строк. В них измерения помогают принять решение о значении признака даже тогда, когда он не выражается в сантиметрах и градусах.
Конечно же, лучше всего непосредственно измерить все вхождения признака и затем использовать одну из моделей усреднения. Если мы анализируем размер почерка, то высоту всех букв, по которым судят о размере. Если ведение строк, то угол наклона каждой строки. Хотя на практике это делают не всегда. Опытный графолог очень точно и «на глазок» определяет размер и ведение строк. Особенно, когда почерк достаточно регулярный. Этот феномен исследовал в свое время Теуд Валлнер [65]. Он обобщил несколько экспериментов, поставленных различными исследователями почерка. В них он сравнивал результаты, полученные при непосредственном измерении ряда признаков почерка с оценками графологов. Рассматривались, в частности, уже упомянутые нами признаки – размер почерка, наклон букв, расстояния между строками, ширина полей, ширина букв, введение строк. Корреляция между оценками и измерениями оказалась очень высокой. Только по одному или двум признакам коэффициент корреляции составил порядка 0,7, что тоже достаточно высокое значение. По остальным же он был еще выше.
Обязательно измерять следует тогда, когда признаки оказываются не очень регулярными. То есть, например, когда одни буквы больше, а другие меньше. После измерения всех релевантных вхождений букв (если мы говорим о размере) вычисляют среднюю величину. Для этого используют одну из стандартных моделей.
• Арифметическая средняя: сумма значений для всех элементов делится на их число. Данный подход дает наиболее точный результат. Кроме того, если все значения измерены, то можно попытаться проанализировать дополнительные, характерные особенности данного почерка. Например, для размера букв интерес может представлять то, как отличается одна буква от другой. Всегда ли буква «н» выше остальных. Или изменение размера от начала текста к концу. Иными словами, мы получаем больше информации. Недостаток данной модели – относительная трудоемкость, так как необходимо измерить все элементы.
• Медиана: суммарный размер самого маленького и самого большого элемента делится пополам. Этот подход проще предыдущего. Элементы, по которым измеряются максимальное и минимальное значения, могут достаточно точно выбираться без измерения всех.
• Модальная величина: выбирается наиболее часто встречающийся размер. В этом случае, как и для медианы, не обязательно измерять все элементы.
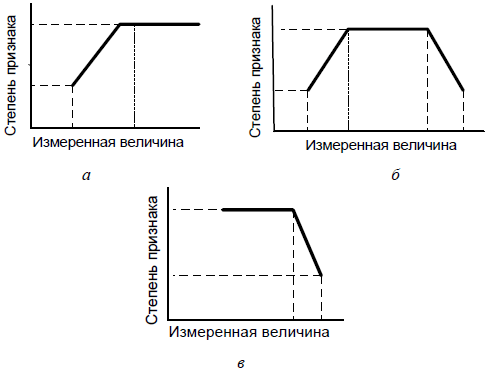
Вычислив тем или иным способом среднюю величину признака, можно количественно оценить степень его присутствия в почерке. Мы договорились представлять ее на интервале от 0 до 1. Так, левое поле считается нормальным при ширине от 15 до 30 мм. При ширине 30 мм и более оно считается большим. Но понятно, что степень присутствия для поля шириной 40 мм должна быть больше, чем для поля в 30 мм. Поэтому нужны правила, которые помогут после измерения оценить сам признак почерка. В своей практике мы используем простую оценочную модель. Суть ее в том, что степень признака сначала изменяется линейно от средней величины. Когда же последняя достигает определенного критического значения, то степень становится постоянной (как правило, равной максимальной величине – единице). Дальнейшая разница становится уже несущественной. При этом оценочная модель может иметь три формы.
• Односторонний интервал сверху: степень признака линейно растет от установленной величины до 1 и затем становится постоянной. Широкое левое поле служит примером. При ширине от 30 до 40 мм степень признака линейно растет от начальной величины до 1. При измеренном среднем значении, превышающем 40 мм, она остается равной 1. Начальную величину устанавливают, естественно, эмпирически. Она изменяется от одного признака почерка к другому. В случае левого поля мы используем 0,75.
• Односторонний интервал снизу: степень признака равняется максимальной величине, а затем начинает линейно снижаться по мере увеличения измеренного среднего значения до установленной минимальной величины. Примером служит признак «маленькое левое поле». Степень равна 1 при величине поля от 0 до 10 мм. На интервале от 10 до 15 мм она линейно уменьшается.
• Двусторонний интервал: комбинация обоих вариантов, приведенных выше. Примером служит признак «Нормальный размер левого поля» (т. е. от 15 до 30 мм). Сначала степень линейно растет, затем остается постоянной на максимальном уровне, а в конце уменьшается.
Графически эти три формы выглядят следующим образом (рис. 2.4).
Рис. 2.4. Оценочная модель признаков почерка: а – односторонний интервал сверху; б – двусторонний интервал; в – односторонний интервал снизу
Оцениваемые признаки. Оценивают то, что не удается непосредственно измерить. Это касается, главным образом, формы букв и их элементов. Оценки заведомо несут в себе субъективность. Хотя если следовать строгим правилам, то ее можно серьезным образом уменьшить. Для этого можно использовать, в частности, частотную модель. Число случаев, когда то или иное значение признака встречается, делят на общее число наблюдений. Это отношение и выступает базой для количественного представления степени признака. Для оцениваемых признаков оно также лежит в интервале от 0 до 1. Например, форма овалов в буквах «а», «о», «д» и «в». Упрощенно говоря, они могут быть закрытыми и открытыми. Так вот, большее число букв с закрытыми овалами по отношению к общему числу букв с овалами может служить хорошей оценкой. И это уже вполне объективно.
Устанавливаемые признаки. Устанавливаемые признаки либо присутствуют в тексте, и тогда мы присваиваем им оценку 1, либо отсутствуют и оцениваются как 0. Как правило, к ним относятся достаточно специфические особенности почерка, для которых бессмысленно использовать частотную модель. Даже если формально и попытаться, то их оценка будет всегда или очень низкой, близкой к 0, или очень высокой. Например, такой признак, как длинный верхний штрих, который перекрывает несколько букв. В русском языке этот признак может быть только у заглавной буквы «Б». В латинском алфавите это и буквы «T» и «t», и заглавная «F». В тексте могут встретиться одна-две заглавных буквы «Б». Для оценки устанавливаемых признаков используют пороговую модель. В ней решение о том, присутствует признак или нет, принимают, когда число его появлений превышает некоторую пороговую величину. Как правило, эта пороговая величина мала – два-три проявления. Устанавливаемый признак может иметь и несколько возможных значений, но часто ни одно из них в почерке не присутствует.
Выбираемые признаки. Выбираемые признаки похожи на устанавливаемые признаки в том смысле, что они принимают значение либо 0, либо 1. Например, форма левого поля. Она может быть прямой, расширяющейся, сужающейся, вогнутой, выгнутой, ступенчатой или просто неровной. Но какую-то форму она имеет всегда. То есть сумма всех значений признака будет всегда равной 1. Иными словами, признак является аддитивным. Это отличает выбираемые признаки от устанавливаемых. Одно значение присутствует всегда, если признак можно вообще рассматривать. Мы уже упоминали, что поля, например, можно анализировать не по всякому рукописному тексту.