Фон:……….
После воздействия:……….
Распределение частот (числá пораженных мишеней)
Уже при первом взгляде на полученные ряды можно заметить, что многие данные принимают одни и те же значения, причем одни значения встречаются чаще, а другие — реже. Поэтому было бы интересно вначале графически представить распределение различных значений с учетом их частот. При этом получают следующие столбиковые диаграммы:
Такое распределение данных по их значениям дает нам уже гораздо больше, чем представление в виде рядов. Однако подобную группировку используют в основном лишь для качественных данных, четко разделяющихся на обособленные категории (см. дополнение Б.1).
Что касается количественных данных, то они всегда располагаются на непрерывной шкале и, как правило, весьма многочисленны. Поэтому такие данные предпочитают группировать по классам, чтобы яснее видна была основная тенденция распределения.
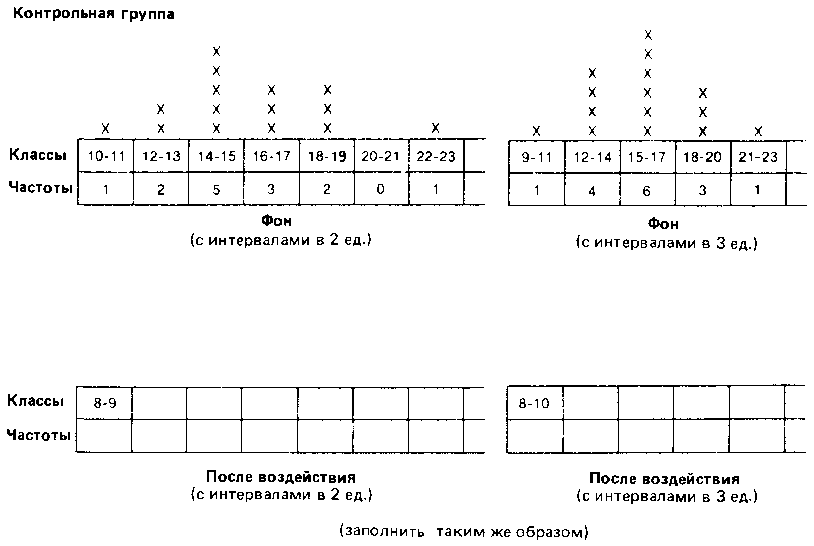
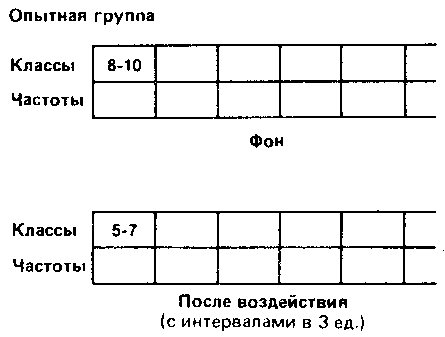
Такая группировка состоит в основном в том, что объединяют данные с одинаковыми или близкими значениями в классы и определяют частоту для каждого класса. Способ разбиения на классы зависит от того, что именно экспериментатор хочет выявить при разделении измерительной шкалы на равные интервалы. Например, в нашем случае можно сгруппировать данные по классам с интервалами в две или три единицы шкалы:
Выбор того или иного типа группировки зависит от различных соображений. Так, в нашем случае группировка с интервалами между классами в две единицы хорошо выявляет распределение результатов вокруг центрального «пика». В то же время группировка с интервалами в три единицы обладает тем преимуществом, что дает более обобщенную и упрощенную картину распределения, особенно если учесть, что число элементов в каждом классе невелико [209]. Именно поэтому в дальнейшем мы будем оперировать классами в три единицы.
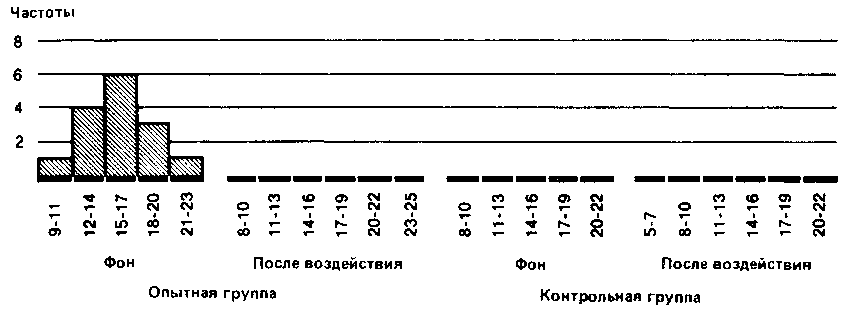
Данные, разбитые на классы по непрерывной шкале, нельзя представить графически так, как это сделано выше. Поэтому предпочитают использовать так называемые гистограммы — способ графического представления в виде примыкающих друг к другу прямоугольников:
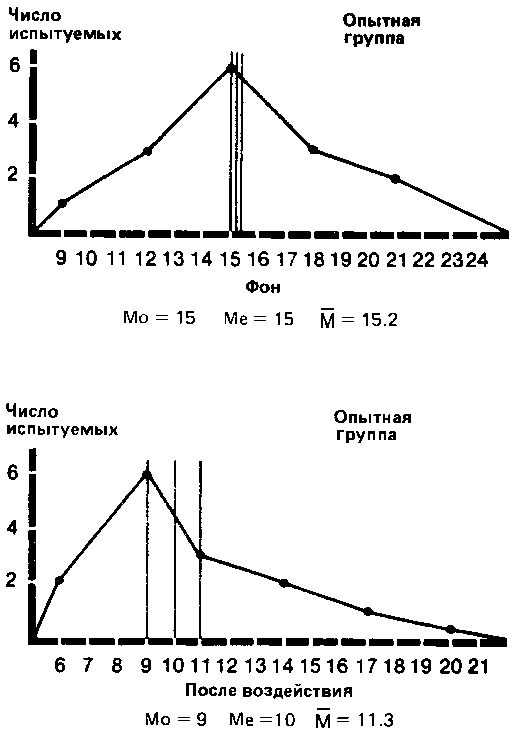
Наконец, для еще более наглядного представления общей конфигурации распределения можно строить полигоны распределения частот. Для этого отрезками прямых соединяют центры верхних сторон всех прямоугольников гистограммы, а затем с обеих сторон «замыкают» площадь под кривой, доводя концы полигонов до горизонтальной оси (частота = 0) в точках, соответствующих самым крайним значениям распределения. При этом получают следующую картину:
Если сравнить полигоны, например, для фоновых (исходных) значений контрольной группы и значений после воздействия для опытной группы, то можно будет увидеть, что в первом случае полигон почти симметричен (т. е. если сложить полигон вдвое по вертикали, проходящей через его середину, то обе половины наложатся друг на друга), тогда как для экспериментальной группы он асимметричен и смещен влево (так что справа у него как бы вытянутый шлейф).
Полигон для фоновых данных контрольной группы сравнительно близок к идеальной кривой, которая могла бы получиться для бесконечно большой популяции. Такая кривая — кривая нормального распределения — имеет колоколообразную форму и строго симметрична. Если же количество данных ограничено (как в выборках, используемых для научных исследований), то в лучшем случае получают лишь некоторое приближение (аппроксимацию) к кривой нормального распределения. Если вы построите полигон для фоновых значений опытной группы и значений после воздействия для контрольной группы, то вы наверняка заметите, что так же будет обстоять дело и в этих случаях.
Оценка центральной тенденции
Если распределения для контрольной группы и для фоновых значений в опытной группе более или менее симметричны, то значения, получаемые в опытной группе после воздействия, группируются, как уже говорилось, больше в левой части кривой. Это говорит о том, что после употребления марихуаны выявляется тенденция к ухудшению показателей у большого числа испытуемых.
Для того чтобы выразить подобные тенденции количественно, используют три вида показателей моду, медиану и среднюю.
1. Мода (Mo) — это самый простой из всех трех показателей. Она соответствует либо наиболее частому значению, либо среднему значению класса с наибольшей частотой. Так, в нашем примере для экспериментальной группы мода для фона будет равна 15 (этот результат встречается четыре раза и находится в середине класса 14-15-16), а после воздействия — 9 (середина класса 8-9-10).
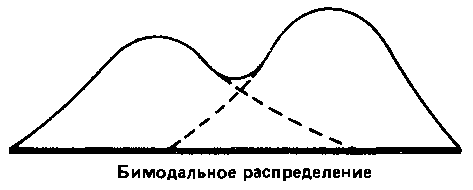
Мода используется редко и главным образом для того, чтобы дать общее представление о распределении. В некоторых случаях у распределения могут быть две моды; тогда говорят о бимодальном распределении. Такая картина указывает на то, что в данном совокупности имеются две относительно самостоятельные группы (см., например, данные Триона, приведенные в документе 3.5).
2. Медиана (Me) соответствует центральному значению в последовательном ряду всех полученных значений. Так, для фона в экспериментальной группе, где мы имеем ряд
10, 11, 12, 13, 14, 14, 15, 15, 15, 15, 17, 17, 19, 20, 21;
медиана соответствует 8-му значению, т. е. 15. Для результатов воздействия в экспериментальной группе она равна 10.
В случае если число данных n, четное, медиана равна средней арифметической между значениями, находящимися в ряду на n/2-м и n/2+1-м местах. Так, для результатов воздействия для восьми юношей опытной группы медиана располагается между значениями, находящимися на 4-м (8/2 = 4) и 5-м местах в ряду. Если выписать весь ряд для этих данных, а именно
7, 8, 9, 11, 12, 13, 14, 16;
то окажется, что медиана соответствует (11 + 12)/2 = 11,5 (видно, что медиана не соответствует здесь ни одному из полученных значений).
3. Средняя арифметическая (
) (далее просто «средняя») — это наиболее часто используемый показатель центральной тенденции. Ее применяют, в частности, в расчетах, необходимых для описания распределения и для его дальнейшего анализа. Ее вычисляют, разделив сумму всех значений данных на число этих данных. Так, для нашей опытной группы она составит 15,2 (228/15) для фона и 11,3 (169/15) для результатов воздействия.
Если теперь отметить все эти три параметра на каждой из кривых для экспериментальной группы, то будет видно, что при нормальном распределении они более или менее совпадают, а при асимметричном распределении — нет.
Прежде чем идти дальше, полезно будет вычислить все эти показатели для обеих распределений контрольной группы — они пригодятся нам в дальнейшем: