Однако в типогенетике, так же как и в настоящей генетике, мы имеем дело с гораздо более сложной схемой. Мы так же начинаем с неких случайных цепочек, подобных аксиомам формальных систем. Но теперь у нас нет «правил вывода» — то есть энзимов. Однако, мы можем перевести каждую цепочку в один или несколько энзимов! Таким образом, сами цепочки будут указывать нам, какие операции должны производиться на них, и эти операции, в свою очередь, произведут новые цепочки, которые укажут на следующие операции, и т. д, и т. п! Вот так смешение уровней! Для сравнения подумайте, насколько изменилась бы головоломка MU, если бы каждая новая теорема могла бы быть превращена в правило вывода при помощи некоего кода.
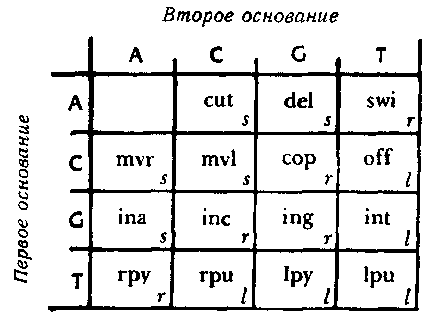
Как же делается подобный «перевод»? Для этого используется типогенетический код, при помощи которого соседние пары оснований — так называемые «дублеты» представляют различные аминокислоты. Существует шестнадцать возможных дублетов АА, AC, AG, AT, CA, СС и т. д. С другой стороны, у нас есть пятнадцать аминокислот. Типогенетический код показан на рис 87.
Рис. 87. Типогенетический код, при помощи которого каждый дублет кодируется как одна из аминокислот (или как знак препинания).
Из таблицы следует, что перевод дублета GC — «vsc» («вставить С»); что AT переводится как «prb» («перебросить энзим на другую цепочку») и так далее. Таким образом, становится ясно, что цепочка может прямо определять энзим. Например, цепочка:
TAGATCCAGTCCACATCGА
разделяется на дублеты следующим образом:
ТА GA ТС CA GT СС AC AT CG А
Последнее А остается без пары. Вот перевод этой цепочки в энзимы:
рmр — vsa — рrр — sdp — vst — sdl — raz — prb — kop
(Заметьте, что оставшееся А ничего не добавляет).
Третичная структура энзимов
Читатель, наверное, обратил внимание на маленькие буквы в нижнем правом углу каждого квадрата. Они очень важны для определения того, к какой букве предпочитает прикрепляться каждый энзим вначале Это определяется довольно необычным способом. Для этого приходится выяснить, какую «третичную структуру» имеет каждый энзим; эта третичная структура, в свою очередь, определена его первичной структурой. Под первичной структурой здесь понимается последовательность в энзиме аминокислот; под третичной структурой — то, каким образом он «уложен» в пространстве. Дело в том, что энзимы не любят располагаться по прямым, как мы их до сих пор представляли. Каждая расположенная внутри цепочки (но не на ее концах) аминокислота может изогнуться; направление изгиба определяется буквами в углах квадратов. Так «l» и «r» обозначают, соответственно, «влево» и «вправо», а буква «s» значит «прямо». Давайте возьмем наш последний пример энзима и постараемся представить себе его третичную структуру. Мы начнем с первичной структуры и будем продвигаться слева направо. После каждого энзима, снабженного в таблице буквой «l», мы будем поворачивать налево, после энзимов с буквой «r» — направо, а после энзимов с «s» поворота не будет. На рис. 88 показана схема (в двух измерениях) нашего энзима:
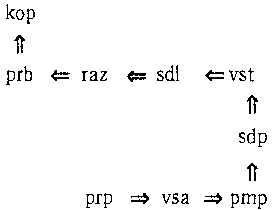
Рис. 88. Третичная структура типоэнзима.
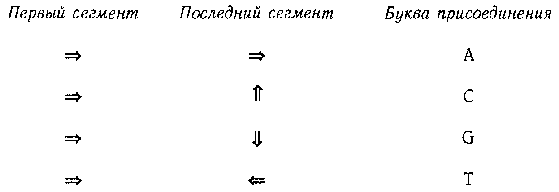
Обратите внимание на левый поворот после «рrр», правый поворот после «prb» и так далее. Заметьте также, что первый сегмент («pmp => vsa») и последний сегмент («prb => kop») расположены перпендикулярно. Это и является ключом к тому, к какой букве присоединяется данный энзим: относительное расположение первого и последнего сегмента третичной структуры энзима определяют, к какой букве он прикрепится. Мы всегда можем повернуть энзим таким образом, чтобы его первый сегмент указывал направо. После этого последний сегмент энзима будет указывать на его «прикрепительные вкусы». Это показано на рис. 89.
Рис. 89. Таблица «прикрепительных вкусов» типоэнзимов.
Таким образом, наш энзим предпочитает букву С. Иногда, складываясь, энзим пересекает сам себя — ничего страшного, просто представьте, что он проходит над или под собой. Обратите внимание, что все аминокислоты энзима играют роль в определении его третичной структуры.
Пунктуация, гены и рибосомы
Остается объяснить только одно. Почему в углу квадрата АА Типогенетического Кода нет никакой буквы? Дело в том, что дуплет АА действует как знак препинания внутри цепочки, указывая на конец кода для данного энзима. Это означает, что в одной цепочке может быть закодировано несколько энзимов, если она содержит один или несколько дуплетов АА. Например, в цепочке:
CG GA ТА СТ АА AC CG А
закодировано два энзима:
кор — vsa — pmp — byk
и
raz — кор
АА разделяет цепочку на два «гена». Ген — это кусок цепочки, в котором закодирован один энзим. Заметьте, что не всякое АА является знаком препинания, например, CAAG делится на энзимы «sdp — str». АА начинается с четного подразделения и, таким образом, не составляет дуплета! Механизм, читающий цепочки и производящий закодированные в них энзимы, называется рибосомой. (Играя в типогенетику, мы проделываем работу рибосом.) Рибосомы не отвечают за третичную структуру энзимов, поскольку она полностью определена их первичной структурой. Процесс перевода всегда происходит от цепочек к энзимам, а не наоборот.
Головоломка: типогенетический авто-реп
Теперь вы знаете правила типогенетики и можете поэкспериментировать с этой игрой. В частности, весьма интересно было бы попытаться получить самовоспроизводящуюся цепочку. Вот что это означало бы: дана некая цепочка; рибосома действует на нее, производя закодированные там энзимы. Затем эти энзимы вступают в контакт с первоначальной цепочкой и начинают с ней работать. Получается множество дочерних цепочек. Сами дочерние цепочки взаимодействуют с рибосомами, вследствие чего получаются новые энзимы, действующие на дочерние цепочки, и цикл продолжается. Наша надежда в том, что рано или поздно среди полученных цепочек мы найдем две копии первоначальной цепочки (на самом деле, одна из копий может оказаться самой первоначальной цепочкой.)
Центральная Догма типогенетики
Схема типогенетических процессов представлена на следующей диаграмме.
Рис. 90. «Центральная Догма типогенетики.» пример «Запутанной Иерархии».
На этой диаграмме показана Центральная Догма типогенетики. Из нее видно, как цепочки определяют энзимы (через Типогенетический Код) и как энзимы, в свою очередь, действуют на породившие их цепочки; в результате этого получаются новые цепочки. Таким образом, левая стрелка показывает, как старая информация подается наверх (ведь энзим является трансляцией цепочки и, следовательно, содержит ту же информацию, но в другой, активной форме). Правая стрелка, однако, не показывает движение информации вниз; вместо этого она указывает на то, как создается новая информация: передвижением символов в цепочке.
Энзим в типогенетике, подобно правилу вывода в формальной системе, механически переставляет символы в цепочке, не принимая во внимание никакого «значения», которое может заключаться в этих символах. Таким образом, здесь наблюдается интересное смешение уровней. С одной стороны, цепочки, поскольку на них воздействуют энзимы, играют роль данных (на это указывает правая стрелка); с другой стороны, они также диктуют, какие операции должны быть проделаны с данными и, таким образом, играют роль программ (на это указывает левая стрелка). Играющий в типогенетику действует как интерпретатор и процессор. «Круговая порука», связывающая «верхний» и «нижний» уровни в типогенетике, показывает, что нельзя сказать, что цепочки или энзимы находятся выше (или ниже) уровнем по сравнению друг с другом. С другой стороны. Центральная Догма системы MIU выглядит так: