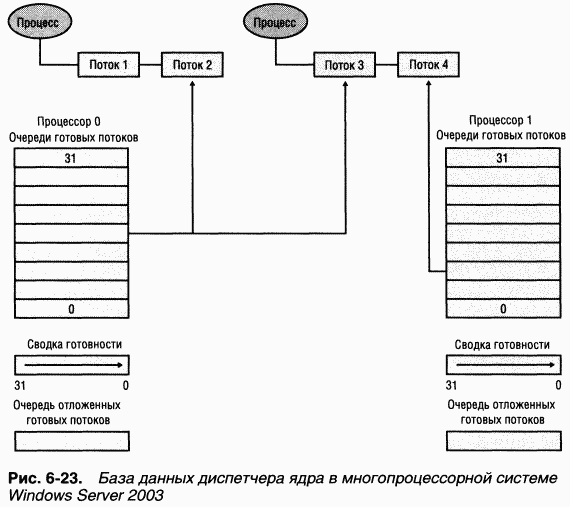
Для каждого процессора создается и список потоков в готовом, но отложенном состоянии (deferred ready state). Это потоки, готовые к выполнению, но операция, уведомляющая в результате об их готовности, отложена до более подходящего времени. Поскольку каждый процессор манипулирует только своим списком отложенных готовых потоков, доступ к этому списку не синхронизируется по спин-блокировке PRCB. Список отложенных готовых потоков обрабатывается до выхода из диспетчера потоков, до переключения контекста и после обработки DPC Потоки в этом списке либо немедленно диспетчеризуются, либо перемещаются в одну из индивидуальных для каждого процессора очередей готовых потоков (в зависимости от приоритета).
Заметьте, что общесистемная спин-блокировка диспетчера ядра по-прежнему существует и используется в Windows Server 2003, но она захватывается лишь на период, необходимый для модификации общесистемного состояния, которое может повлиять на то, какой поток будет выполняться следующим. Например, изменения в синхронизирующих объектах (мьютексах, событиях и семафорах) и их очередях ожидания требуют захвата блокировки диспетчера ядра, чтобы предотвратить попытки модификации таких объектов (и последующей операции перевода потоков в состояние готовности к выполнению) более чем одним процессором. Другие примеры — изменение приоритета потока, срабатывание таймера и обмен содержимого стеков ядра для потоков.
Наконец, в Windows Server 2003 улучшена сихронизация переключения контекста потоков, так как теперь оно синхронизируется с применением спин-блокировки, индивидуальной для каждого потока, а в Windows 2000 и Windows XP переключение контекста синхронизировалось захватом общесистемной спин-блокировки обмена контекста.
Системы с поддержкой Hyperthreading
Как уже говорилось в разделе «Симметричная многопроцессорная обработка» главы 2, Windows XP и Windows Server 2003 поддерживают многопроцессорные системы, использующие технологию Hyperthreading (аппаратная реализация логических процессоров на одном физическом).
1. Логические процессоры не подпадают под лицензионные ограничения на число физических процессоров. Так, Windows XP Home Edition, которая по условиям лицензии может использовать только один процессор, задействует оба логических процессора в однопроцессорной системе с поддержкой Hyperthreading.
2. Если все логические процессоры какого-либо физического процессора простаивают, для выполнения потока выбирается один из логических процессоров этого физического процессора, а не того, у которого один из логических процессоров уже выполняет другой поток.
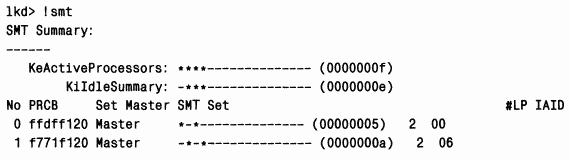
ЭКСПЕРИМЕНТ: просмотр информации, связанной с Hyperthreading
Изучить такую информацию позволяет команда !smt отладчика ядра. Следующий вывод получен в системе с двумя процессорами Xeon с технологией Hyperthreading (четыре логических процессора):
Логические процессоры 0 и 1 находятся на разных физических процессорах (на что указывает ключевое слово «Master»).
Системы NUMA
Другой тип многопроцессорных систем, поддерживаемый Windows XP и Windows Server 2003, — архитектуры памяти с неунифицированным доступом (nonuniform memory access, NUMA). B NUMA-системе процессоры группируются в узлы. B каждом узле имеются свои процессоры и память, и он подключается к системе соединительной шиной с когерентным кэшем (cache-coherent interconnect bus). Доступ к памяти в таких системах называется неунифицированным потому, что у каждого узла есть локальная высокоскоростная память. Хотя любой процессор в любом узле может обращаться ко всей памяти, доступ к локальной для узла памяти происходит гораздо быстрее.
Ядро поддерживает информацию о каждом узле в NUMA-системе в структурах данных KNODE. Переменная ядра KeNodeBlock содержит массив указателей на структуры KNODE для каждого узла. Формат структуры KNODE можно просмотреть командой dt отладчика ядра:
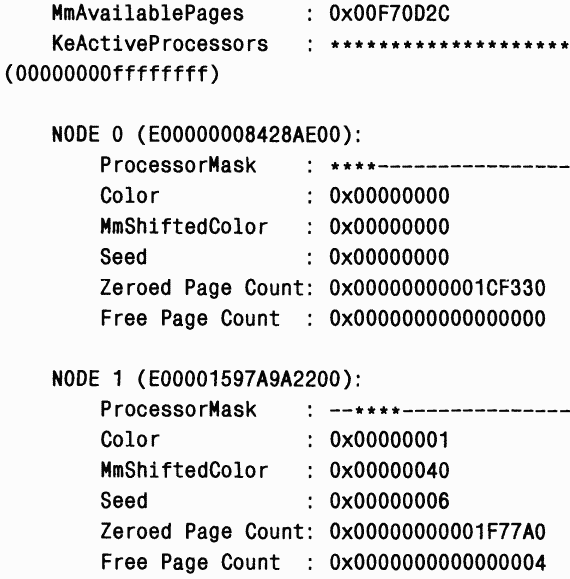
ЭКСПЕРИМЕНТ: просмотр информации, относящейся к NUMA
Вы можете исследовать информацию, поддерживаемую Windows для каждого узла в NUMA-системе, с помощью команды !numa отладчика ядра. Ниже приведен фрагмент вывода, полученный в 32-процессорной NUMA-системе производства NEC с 4 процессорами в каждом узле:
21: kd›!numa NUMA Summary:
—
Number of NUMA nodes: 8 Number of Processors: 32
A это фрагмент вывода, полученный в 64-процессорной NUMA-системе производства Hewlett Packard с 4 процессорами в каждом узле:
Приложения, которым нужно выжать максимум производительности из NUMA-систем, могут устанавливать маски привязки процесса к процессорам в определенном узле. Получить эту информацию позволяют функции, перечисленные в таблице 6-19. (Функции, с помощью которых можно изменять привязку потоков к процессорам, были перечислены в таблице 6-14.)
O том, как алгоритмы планирования учитывают особенности NUMA-систем, см. в разделе «Алгоритмы планирования потоков в многопроцессорных системах» далее в этой главе (а об оптимизациях в диспетчере памяти для использования преимуществ локальной для узла памяти см. в главе 7).
Привязка к процессорам
У каждого потока есть маска привязки к процессорам (affinity mask), указывающая, на каких процессорах можно выполнять данный поток Потоки наследуют маску привязки процесса. По умолчанию начальная маска для всех процессов (а значит, и для всех потоков) включает весь набор активных процессоров в системе, т. е. любой поток может выполняться на любом процессоре.
Однако для повышения пропускной способности и/или оптимизации рабочих нагрузок на определенный набор процессоров приложения могут изменять маску привязки потока к процессорам. Это можно сделать на нескольких уровнях.
• Вызовом функции SetThreadAffintiyMask, чтобы задать маску привязки к процессорам для индивидуального потока;
• Вызовом функции SetProcessAffinityMask, чтобы задать маску привязки к процессорам для всех потоков в процессе. Диспетчер задач и Process Explorer предоставляют GUI-интерфейс к этой функции: щелкните процесс правой кнопкой мыши и выберите Set Affinity (Задать соответствие). Утилита Psexec (с сайта sysinternals.com) предоставляет к той же функции интерфейс командной строки (см. ключ — a).
• Включением процесса в задание, в котором действует глобальная для задания маска привязки к процессорам, установленная через функцию SetInformationJobObject (о заданиях см. раздел «Объекты-задания» далее в этой главе.)
• Определением маски привязки к процессорам в заголовке образа с помощью, например, утилиты Imagecfg из Windows 2000 Server Resource Kit Supplement 1. (O формате образов в Windows см. статью «Portable Executable and Common Object File Format Specification в MSDN Library.)
B образе можно установить и «однопроцессорный» флаг (используя в Imagecfg ключ — u). Если этот флаг установлен, система выбирает один процессор в момент создания процесса и закрепляет его за этим процессом; при этом процессоры меняются от первого и до последнего по принципу карусели. Например, в двухпроцессорной системе при первом запуске образа, помеченного как однопроцессорный, он закрепляется за процессором 0, при втором — за процессором 1, при третьем — за процессором 0, при четвертом — за процессором 1 и т. д. Этот флаг полезен, когда нужно временно обойти ошибку в программе, связанную с неправильной синхронизацией потоков, но проявляющуюся только в многопроцессорных системах.