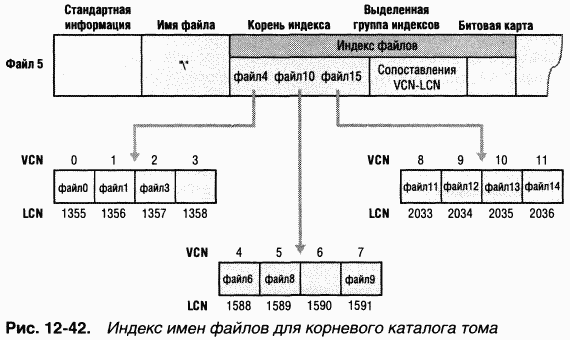
Ha рис. 12–42 в атрибуте «корень индекса» и индексных буферах показаны только имена файлов (например, файл 6), но каждая запись индекса содержит и файловую ссылку на запись MFT, описывающую данный файл, плюс метку времени и информацию о размере файла. NTFS дублирует метку времени и информацию о размере файла из записи MFT для файла. Такой подход, используемый файловыми системами FAT и NTFS, требует записи обновленной информации в два места. Ho даже при этом просмотр каталогов существенно ускоряется, поскольку файловая система может сообщать метки времени и размеры файлов, не открывая каждый файл в каталоге.
Атрибут «выделенная группа индексов» сопоставляет VCN групп индексных буферов с LCN, которые указывают, в каком месте диска находятся индексные буферы, а битовая карта используется для учета того, какие VCN в индексных буферах заняты, а какие свободны. Ha рис. 12–42 на каждый VCN, т. е. на каждый кластер, приходится по одной записи для файла, но на самом деле кластер содержит несколько записей. Каждый индексный буфер размером 4 Кб может содержать 20–30 записей для имен файлов.
Структура данных b+ tree — это разновидность сбалансированного дерева, идеальная для организации отсортированных данных, хранящихся на диске, так как позволяет минимизировать количество обращений к диску при поиске заданного элемента. B MFT атрибут корня индекса для каталога содержит несколько имен файлов, выступающих в качестве индексов для второго уровня b+ tree. C каждым именем файла в атрибуте корня индекса связан необязательный указатель индексного буфера. Этот индексный буфер содержит имена файлов, которые с точки зрения лексикографии меньше данного имени. Например, на рис. 12–42 файл 4 — это элемент первого уровня b+ tree. Он указывает на индексный буфер, содержащий имена файлов, которые лексикографически меньше имени в этом элементе, — файл 0, файл 1 и файл 3. Обратите внимание, что использованные в этом примере имена (файл1, файл2 и др.) не являются буквальными, — они просто иллюстрируют относительное размещение файлов, лексикографически упорядоченных в соответствии с показанной последовательностью.
Хранение имен файлов в структурах вида b+ tree дает несколько преимуществ. Поиск в каталоге выполняется быстрее, так как имена файлов хранятся в отсортированном порядке. A когда высокоуровневое программное обеспечение перечисляет файлы в каталоге, NTFS возвращает уже отсортированные имена. Наконец, поскольку b+ tree имеет тенденцию к росту в ширину, а не в глубину, скорость поиска не уменьшается с увеличением размера каталога.
Кроме индексации имен, NTFS обеспечивает универсальную индексацию данных, и некоторая функциональность NTFS (в том числе идентификации объектов, отслеживания квот и консолидированной защиты) использует индексацию для управления внутренними данными.
Идентификаторы объектов
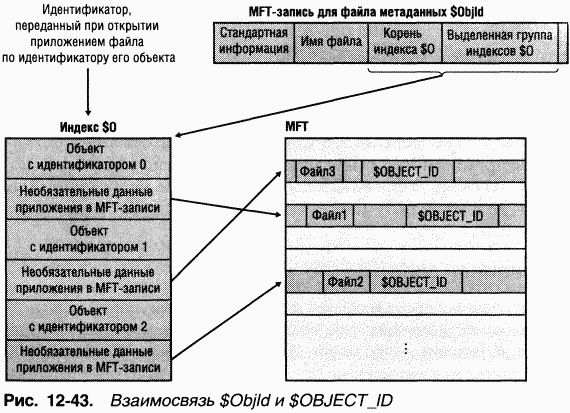
Кроме идентификатора объекта, назначенного файлу или каталогу и хранящегося в атрибуте $OBJECT_ID записи MFT, NTFS также запоминает соответствие между идентификаторами объектов и номерами их файловых ссылок в индексе Ю файла метаданных \$Extend\$ObjId. Элементы индекса сортируются по значениям идентификатора объекта, благодаря чему NTFS может быстро находить файл по его идентификатору. Таким образом, используя недокументированную функциональность, приложения могут открывать файл или каталог по идентификатору объекта. Ha рис. 12–43 показана взаимосвязь между файлом метаданных $Objid и атрибутами $OBJECT_ID в MFT-записях.
Отслеживание квот
NTFS хранит информацию о квотах в файле метаданных \$Extend\$Quota, который состоит из индексов $O и $Q. Структура этих индексов показана на рис. 12–44. NTFS не только присваивает каждому дескриптору защиты уникальный внутренний идентификатор защиты, но и назначает каждому пользователю уникальный идентификатор. Когда администратор задает квоты для пользователя, NTFS создает идентификатор этого пользователя, соответствующий его SID. NTFS создает в индексе $O запись, сопоставляющую SID с идентификатором пользователя, и сортирует этот индекс по идентификаторам пользователей; в индексе $Q создается запись, управляющая квотами (quota control entry). Эта запись содержит лимиты, выделенные пользователю, а также объем дискового пространства, отведенный ему на данном томе.
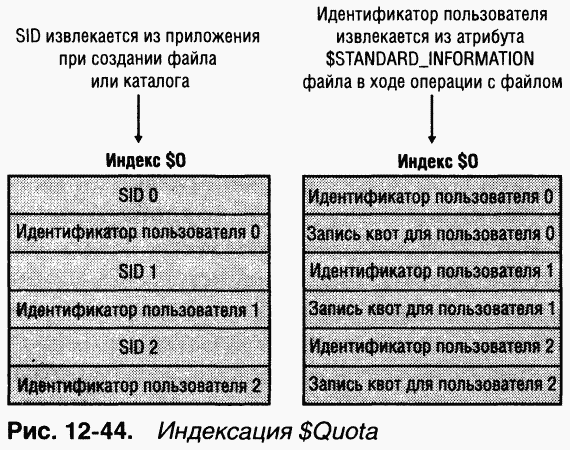
Когда приложение создает файл или каталог, NTFS получает SID пользователя этого приложения и ищет соответствующий идентификатор пользователя в индексе $O. Этот идентификатор записывается в атрибут $STANDARD_INFORMATION нового файла или каталога. Затем NTFS просматривает запись квот в индексе $Q и определяет, не превышает ли выделенное дисковое пространство установленные для данного пользователя лимиты. Когда новое дисковое пространство, выделяемое пользователю, превышает пороговое значение, NTFS предпринимает соответствующие меры, например, записывает событие в журнал System (Система) или отклоняет запрос на создание файла или каталога.
Консолидированная защита
NTFS всегда поддерживала средства защиты, которые позволяют администратору указывать, какие пользователи могут обращаться к определенным файлам и каталогам, а какие — не могут. B версиях NTFS до Windows 2000 каждый файл и каталог хранит дескриптор защиты в своем атрибуте защиты. Ho в большинстве случаев администратор применяет одинаковые пара метры защиты к целому дереву каталогов, что приводит к дублированию дескрипторов защиты во всех файлах и подкаталогах этого дерева каталогов. B многопользовательских средах, например в Windows 2000 Server со службой Terminal Services, такое дублирование может потребовать слишком большого пространства на диске, поскольку дескрипторы защиты будут содержать элементы для множества учетных записей. NTFS в Windows 2000 и более поздних версиях OC оптимизируют использование дискового пространства дескрипторами защиты за счет применения централизованного файла метаданных $Secure, в котором хранится только один экземпляр каждого дескриптора защиты на данном томе.
Файл $Secure содержит два атрибута индексов ($SDH и $SIJ), а также атрибут потока данных $SDS, как показано на рис. 12–45. NTFS назначает каждому уникальному дескриптору защиты на томе внутренний для NTFS идентификатор защиты (не путать с SID, который уникально идентифицирует учетные записи компьютеров и пользователей) и хэширует дескриптор защиты по простому алгоритму. Хэш является потенциально неуникальным «стенографическим» представлением дескриптора. Элементы в индексе $SDH увязывают эти хэши с местонахождением дескриптора защиты внутри атрибута данных $SDS, а элементы индекса $SII сопоставляют NTFS-идентификаторы защиты с местонахождением дескриптора защиты в атрибуте данных $SDS.
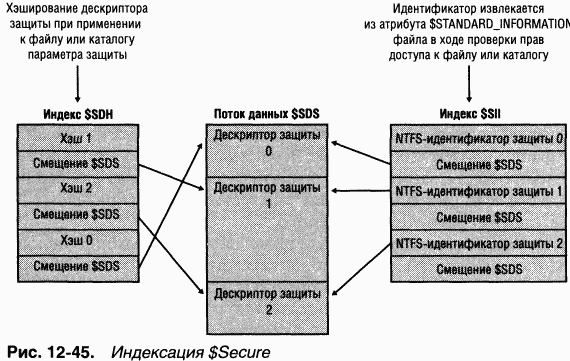
Когда вы применяете дескриптор защиты к файлу или каталогу, NTFS получает хэш этого дескриптора и просматривает индекс $SDH, пытаясь найти совпадение. NTFS сортирует элементы индекса $SDH по хэшам дескрипторов защиты и хранит эти элементы в структуре вида b+ tree. Обнаружив совпадение для дескриптора в индексе $SDH, NTFS находит смещение дескриптора защиты от смещения элемента и считывает дескриптор из атрибута $SDS. Если хэши совпадают, а дескрипторы — нет, NTFS ищет следующее совпадение в индексе $SDH. Когда NTFS находит точное совпадение, файл или каталог, к которому вы применяете дескриптор защиты, может ссылаться на существующий дескриптор в атрибуте $SDS. Тогда NTFS считывает NTFS-идентифика-тор защиты из элемента $SDH и сохраняет его в атрибуте $STANDARD_ INFORMATION файла или каталога. Атрибут $STANDARD_INFORMATION, имеющийся у всех файлов и каталогов, хранит базовую информацию о файле, в том числе его атрибуты, временные метки и идентификатор защиты.