Такой поток информации называется восходящим (bottom-up), или ведóмым, управляемым данными (data-driven). Навстречу ему движутся нисходящие (top-down), или концептуально управляемые процессы (conceptually-driven processes). Они определяются целями и планами человека, его мотивацией и эмоциональным состоянием, структурой его знаний и понятиями, которые используются здесь и сейчас (скажем, его представлением о текущей ситуации), гипотезами о том, что может случиться в следующий момент времени, и многим другим. Два потока дополняют друг друга, позволяя живому существу (его когнитивной системе) выделять из огромного многообразия значимую для его состояния и поведения информацию и использовать ее.
С точки зрения ранних когнитивных психологов, в приведенном описании не хватает самого интересного и важного: «сырые» данные очень неудобно, а часто и невозможно использовать, поэтому информация в ходе обработки кодируется, т. е. переводится в подходящий вид или формат. Считалось, что основным вариантом такого кодирования выступает набор простых символов или знаков. Его примерами могут служить цифры, буквы и др. Скажем, описать словами то, что вы видите перед собой, или план ваших действий – вариант символьного кодирования. В предельном случае представить информацию можно с помощью минимального набора – двоичного кода, состоящего только из нулей и единиц. Чтобы с символьным кодом было удобно обращаться, требуется добавить еще одну важную опцию: правила сочетания символов, или правила их использования. Такие правила выступают аналогом синтаксиса, существующего в любом языке. Опираясь на них, можно составлять цепочки знаков – пропозиции, и они будут иметь значение. Тогда и точность кодирования, и его возможности резко возрастают.
Появление символьного кодирования приводит к нескольким важным последствиям.
Во-первых, информация не просто организована удобным для работы образом – в виде символов она полностью независима от той формы, в которой была исходно получена. Символьная репрезентация универсальна, т. е. доступна для самых разных операций, в том числе для хранения в памяти.
Во-вторых, это очень компактная форма представления информации. Приблизительно оценить экономию можно, сравнив размеры текстового файла, подробно описывающего какую-нибудь картинку, с размером файла с той же картинкой. Текстовое представление «весит» намного меньше.
Именно с опорой на символьное кодирование возникает ментальная (т. е. «мысленная», или «внутренняя») репрезентация. Это удобное для оперирования компактное представление информации, необходимой для решения задачи или организации своего поведения. Такая форма репрезентации позволяет до начала действия проиграть развитие событий «в уме» и скорректировать план в случае необходимости. Ведь информация доступна для различных манипуляций, в том числе для отмены сделанных преобразований и возвращения в «исходную» точку.
Ментальная репрезентация – одно из центральных понятий ранних когнитивных теорий, не утратившее своего значения до сих пор. Принципиально важно, что ее содержание нельзя свести ни к работе индивидуального мозга (репрезентация не равна мозговой активности, хотя тесно связана с ней[1]), ни к социокультурному окружению (языку, верованиям и традициям, поведенческим практикам и т. д.), в котором живет и с которым взаимодействует человек.
В-третьих, символьное кодирование и ментальная репрезентация открывают доступ к еще одному источнику информации – результатам мыслительных процессов. Мышление можно описать как полностью «внутренний» процесс, который опирается лишь на символьные коды, – так его понимало большинство ранних когнитивистов. В таком случае ментальные репрезентации – это возможный доступ к собственному мышлению и его результатам. Информация, получаемая в результате мысленного оперирования символами на основе четких правил, включается в ментальную репрезентацию и может быть использована наряду с любой другой[2].
При всей привлекательности такой позиции она не свободна от недостатков. Один из самых заметных – отсутствие ответа на вопрос, откуда берутся значения символов. И если применительно к конкретной ситуации еще можно представить процесс получения ситуативных значений, то появление устойчивых постоянных значений (скажем, кошек мы называем кошками независимо от их размера, цвета, времени суток и времени года) представляло собой загадку, которую так и не удалось разгадать.
Описание процессов переработки информации, связанных с кодированием, наталкивает на аналогию с работой компьютера. И это не случайно. Компьютерная метафора – один из самых заметных теоретических тезисов ранней когнитивной психологии. По определению Аристотеля, метафорой является использование слов в переносном значении. Для пояснения сложной мысли мы можем уподобить непонятное чему-то более простому и знакомому. Тогда для пояснения своей мысли мы выстраиваем аналогию между понятным и хорошо известным предметом (его называют источником) и предметом, свойства которого нужно пояснить (целью). Например, «мой адвокат – настоящая акула» или «время – деньги». В первом примере метафора переносит свойства агрессивности и «зубастости» на адвоката, во втором – подчеркивает ценность времени и невосполнимый характер его потери. Компьютерная метафора – это содержательная аналогия между человеческим познанием и переработкой информации компьютером.
Сама эта идея в явном виде была сформулирована в 1948 г. в ходе Хиксоновского симпозиума «Мозговые механизмы поведения», который проходил в Калифорнийском технологическом институте в Лахойе. В своем докладе венгеро-американский математик Джон фон Нейман прямо сопоставил работу электронно-вычислительной машины (ЭВМ) и человеческого мозга. Компьютерное «железо» (hardware) вполне можно уподобить мозгу, учитывая его материальный характер и роль передачи электрических импульсов в обоих случаях. Тогда программное обеспечение ЭВМ (software) соотносится с человеческим сознанием, мышлением или психикой. (В русском языке нет точного аналога английскому слову mind.)
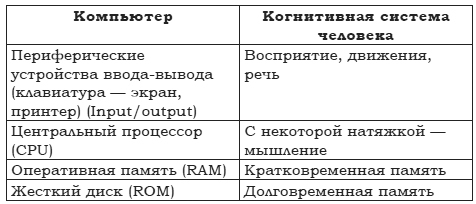
Эту идею несложно развить и расширить. Вслед за фон Нейманом мы можем обнаружить структурное подобие принципиальной архитектуры ЭВМ (компьютера) и организации человеческого познания:
Подобное грубое соответствие кажется чрезмерным упрощением. Его легко раскритиковать (скажем, очень быстро были открыты виды человеческой памяти, отсутствующие у компьютера). Но более тонкие структурные аналогии (например, попытку описывать человеческую память как набор отдельных ячеек) или функциональные аналогии (например, возможность полной перезаписи человеческой памяти на внешний носитель и последующее ее полноценное использование) рассматриваются до сих пор как вполне уместные и продуктивные.
Еще один доклад на Хиксоновском симпозиуме заслуживает звания исторического, как и более ранняя статья тех же авторов. Американские нейрофизиолог Уоррен Мак-Каллок и логик Уолтер Питтс в своем докладе «Почему разум находится в голове?» (Why the Mind Is in the Head?) рассказали, что работа нервной клетки в ее связи с другими нервными клетками может быть описана с помощью логических терминов. «Ответ» (или «молчание») отдельного нейрона можно уподобить исчислению высказываний, где каждое либо истинно, либо ложно. Нейрон, получая сигналы от других нейронов, может просуммировать полученную активацию и, если она превысит какое-то пороговое значение, активировать следующий нейрон. В противном случае ответом будет молчание. Аналогия между логикой и работой нервной системы может быть продемонстрирована в «электрических» терминах: как сигнал, который либо проходит, либо не проходит через электрическую цепь[3]. Эти математически обоснованные идеи, также воплощавшие компьютерную (скорее «информационную») метафору, до поры до времени не были востребованы (точнее – были не слишком объективно раскритикованы), поэтому нейросетевые модели начали свое победное шествие много позже.