На мой взгляд, этих качеств более чем достаточно, чтобы OpenMP стал таким же стандартом для параллельного программирования, которым является C/C++ для программирования обычного.
Недостатков у OpenMP два. Первый - только сейчас появляющаяся поддержка сообщества Open Source. Второй - относительно жесткая модель программирования, навязываемая программисту[К примеру, совсем не очевидно, как заставить OpenMP-программу работать в режиме «системы массового обслуживания», когда некий «главный» поток принимает поступающие извне задания (скажем, запрос к БД или обращение с веб-серверу) по отдельным потокам. А вручную подобная система делается элементарно].
OpenMP
В их основу положена идея использования специальных компиляторов («знающих» про параллельное программирование), для которых в коде программы расставляются специальные пометки-примечания, указывающие, что и где следует делать параллельно, а что - последовательно. Программист же пишет что-то вроде
# ВыполниЭтотУчастокКодаПараллельно
а компилятор пытается по его замечаниям сориентироваться. Скажем, встретив указание «разбей этот цикл по двум потокам» перед кодом, в котором перебором по всем объектам вычисляется физика и AI, компилятор пробует сгенерировать такой код, в котором будет действительно ровно два потока, каждый из них будет выполнять примерно половину общего объема работы. Язык замечаний в OpenMP развит хорошо, и на нем можно внятно растолковывать те или иные особенности исполнения данного участка программы, добиваясь нужного эффекта[OpenMP позволяет делать практически все то же самое, что доступно пользователю при работе непосредственно с операционной системой, и даже немного больше (вплоть до определения атомных операций над участками кода)]. А можно и не растолковывать, положившись целиком на компилятор - к начинающим OpenMP весьма либерален. Прибавьте сюда поддержку этого начинания корпорацией Intel, являющейся одним из ведущих производителей компиляторов для своих CPU, - и вам станет понятно, почему OpenMP превратился в стандарт де-факто, ожидающий утверждения в комитете по стандартизации ANSI.
***
Впрочем, я отвлекся. Обещал рассказать о проблемах параллельного программирования, а рассказываю про то, как все замечательно разрабатывается вместе с OpenMP. Так что дифирамбы ему выношу во врезку и возвращаюсь к нашим баранам.
Проблемы параллельного программирования
В сущности, главная трудность при параллельном программировании - вовсе не в написании кода, а в том, чтобы заставить его нормально работать. «Граблей» здесь, к сожалению, очень много, и обойти их удается далеко не всегда.
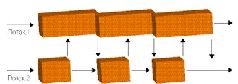
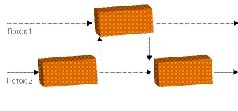
Грабли первые, самые простые и очевидные, - это необходимость балансировки загрузки потоков. Скажем, если один поток считает физику, другой - AI, а третий выводит на экран текущую сцену, то вполне возможно, что первые два потока управятся со своими делами гораздо раньше третьего[В играх со сложной графикой так обычно и происходит - «графическая» подсистема тормозит все остальное] и будут вынуждены его дожидаться. И если вычисления в первом потоке составляют 90% общего объема работы, а во втором - 10%, то больше чем 11-процентного увеличения производительности мы от программы не дождемся.
Замечание из этой же серии: если 80% программного кода поддаются распараллеливанию, а 20% - нет, то получить больше 40% прироста производительности от добавления второго ядра (равно как и более чем пятикратный выигрыш при любом числе процессоров) невозможно. Прибавьте сюда принципиально неразделимые ресурсы - например, оперативную память[Если программу тормозила в первую очередь она и если 90% времени CPU ожидал, пока в кэш не будет залита очередная порция данных, то установка двух процессоров приведет в лучшем случае к тому, что каждый из CPU будет простаивать 95% времени, а выигрыш в быстродействии составит… 5%], - и сразу станет ясно, почему выжать из двухъядерного процессора двукратное превосходство в производительности даже в специализированных программах удается через раз, а в среднем все ограничивается 40-80%. Это не проблема, а скорее, особенность параллельного программирования; тем не менее следует помнить, что параллельность - отнюдь не панацея и что от порядка распределения данных по потокам может зависеть многое.
Грабли вторые - существование разделяемых между потоками данных. Представим простейшую модельную ситуацию, когда танк попадает под обстрел во время ремонта. В текущий тик времени «в танк ударила болванка, вот-вот рванет боекомплект» - с танка снимается 70 единиц «здоровья», гибнет водитель и выходит из строя двигатель. Но в тот же тик механику, вторую минуту заменяющему разбитый трак, удается-таки справиться со своей задачей, поэтому танку добавляется 10 единиц «здоровья» и снимаются все ранее полученные повреждения[Знаю, что звучит дико, но в играх и не такое бывает]. И если все происходит действительно одновременно, то окончательное состояние танка получается недетерминированным - у него с равной вероятностью может и убавиться 70 очков, и прибавиться 10; могут и сохраниться все прежние повреждения, и бесследно сгинуть новые - все зависит только от того, «кто последний» записывал «правильные» по его мнению данные в область памяти, соответствующую танку. Вполне может получиться так, что, к примеру, 70 единиц жизни с танка снимут, а повреждения будут устранены. Или наоборот. И это еще в лучшем случае: а что будет, если в ходе попадания той болванки игра посчитает танк уничтоженным и сотрет его из памяти, а тут откуда ни возьмись прибежит механик и заявит, что несуществующему танку нужно прибавить 10 единиц «здоровья»? Катастрофа и вылет программы!
***
Поэтому для защиты разделяемых между несколькими потоками переменных в параллельных программах вводятся специальные объекты синхронизации, которые позволяют заблокировать изменение того или иного объекта двумя потоками одновременно. Делается это примерно так: объект[Объект синхронизации, но вместе с ним - и весь объект (тот же наш игровой танк, например), который этот объект синхронизации защищает] отдается какому-то одному конкретному потоку, а другие желающие получить объект в пользование ставятся в очередь и ждут, пока нужный объект не освободится. Программисты, забывающие это сделать, как раз и наступают на те самые вторые грабли, обладающие пренеприятным свойством незаметно ломать программу. И ломать так, что она обрушивается не в момент «поломки», а минуты через три, когда «сомнительное место» давным-давно затерялось в пучинах кода, причем происходит это каждый раз в новом месте и в новое время.