– LeakyReLU:
LeakyReLU функция активации представляет собой вариант ReLU с небольшим отрицательным наклоном для отрицательных значений. Она определяется как f(x) = max(ax, x), где a – маленькое положительное число, называемое параметром утечки (leak). LeakyReLU помогает избежать проблемы "мертвых нейронов", которая может возникнуть при использовании ReLU.
– Tanh (гиперболический тангенс):
Tanh функция активации определена как f(x) = (e^x – e^(-x)) / (e^x + e^(-x)). Она преобразует значения в диапазон от -1 до 1, что позволяет сети учиться симметричным зависимостям в данных. Tanh также обладает свойством сжатия данных, что может быть полезно при обработке данных со значениями в отрезке [-1, 1].
– Sigmoid:
Sigmoid функция активации определена как f(x) = 1 / (1 + e^(-x)). Она преобразует значения в диапазон от 0 до 1. Ранее sigmoid была часто использована в нейронных сетях, но в настоящее время ее применение ограничено из-за проблемы исчезающего градиента (vanishing gradient problem) при обучении глубоких сетей.
Применение функций активации в GAN:
Функции активации используются в различных слоях генератора и дискриминатора для добавления нелинейности в модель. Они вносят нелинейные преобразования в скрытые представления, что позволяет модели извлекать более сложные признаки из данных. Кроме того, использование функций активации помогает избежать проблем слишком простых или линейных моделей, которые не могут обработать сложные зависимости в данных. Выбор конкретной функции активации зависит от задачи, архитектуры сети и типа данных, с которыми работает GAN. Важно экспериментировать с различными функциями активации и выбрать наилучший вариант для конкретной задачи.
7. Слои потокового обучения (Flatten Layers):
Слои потокового обучения (Flatten Layers) представляют собой важный тип слоев в нейронных сетях, включая генеративные нейронные сети (GAN). Их главная задача – преобразовать выходные данные многомерных слоев в одномерные векторы, чтобы передать эти данные последующим слоям, которые ожидают одномерные входы.
Принцип работы слоев потокового обучения:
– Преобразование многомерных данных:
В процессе обработки данных нейронные сети часто используют сверточные слои (Convolutional Layers) и рекуррентные слои (Recurrent Layers), которые могут выводить данные с различными размерами и формами. Например, после применения сверточных слоев на изображении, выходы могут быть трехмерными тензорами (например, ширина х высота х количество каналов), а после применения рекуррентных слоев на последовательности – двумерными (например, длина последовательности х размерность скрытого состояния).
–Приведение к одномерному вектору:
Чтобы передать данные на последующие слои, которые ожидают одномерные входы, необходимо преобразовать многомерные данные в одномерный вектор. Для этого используются слои потокового обучения (Flatten Layers). Эти слои выполняют операцию "распрямления" данных, преобразуя многомерные массивы в одномерные.
–Исключение пространственной структуры:
Применение слоев потокового обучения исключает пространственную структуру данных. Например, после использования сверточных слоев, которые обычно сохраняют пространственные зависимости в изображениях, слои потокового обучения преобразуют эти зависимости в линейный порядок, что может привести к потере некоторой информации о пространственной структуре.
Применение слоев потокового обучения в GAN:
В GAN, слои потокового обучения применяются, когда данные, обрабатываемые в генераторе или дискриминаторе, имеют многомерную форму, например, после применения сверточных слоев. Слои потокового обучения выполняют роль промежуточного шага в обработке данных перед подачей их на полносвязные слои (Fully Connected Layers) или другие слои с одномерными ожиданиями.
После применения слоев потокового обучения выходные данные становятся одномерными векторами, которые затем передаются на последующие слои для дальнейшей обработки и принятия решений. Это позволяет модели GAN справляться с более сложными задачами, такими как генерация высококачественных изображений или дискриминация между реальными и сгенерированными данными.
8. Полносвязный слой (Fully Connected Layer):
Это один из основных типов слоев в искусственных нейронных сетях. Он также называется слоем с плотными связями (Dense Layer) или линейным слоем (Linear Layer). В полносвязном слое каждый нейрон входного слоя связан с каждым нейроном выходного слоя.
Работа полносвязного слоя заключается в линейной комбинации входных данных с весами и применении функции активации к полученным значениям. Количество нейронов в выходном слое определяет размерность выходных данных. Если полносвязный слой имеет N входных нейронов и M выходных нейронов, то это означает, что каждый из N входных нейронов соединен со всеми M выходными нейронами.
Математически, для полносвязного слоя можно представить следующим образом:
```
y = activation(W * x + b)
```
где:
– `x` – входные данные (вектор признаков)
– `W` – матрица весов размерности (N, M), где N – количество входных нейронов, а M – количество выходных нейронов
– `b` – вектор смещений (bias) размерности (M)
– `activation` – функция активации, которая применяется к линейной комбинации входов с весами и смещениями
– `y` – выходные данные (результат работы слоя)
Полносвязные слои обладают большой гибкостью и способны учить сложные нелинейные зависимости в данных. Они широко используются в различных архитектурах нейронных сетей, включая обычные многослойные перцептроны, сверточные нейронные сети, рекуррентные нейронные сети и другие.
В контексте генеративных нейронных сетей (GAN), полносвязные слои могут использоваться как часть архитектур генератора и дискриминатора для обработки данных и создания синтетических или классификации реальных и сгенерированных данных. Они являются основными строительными блоками в многих GAN-архитектурах.
Это только небольшой набор типов слоев, которые можно использовать в архитектурах GAN. В реальности GAN могут быть более сложными и включать комбинации различных типов слоев, а также другие дополнительные слои и техники, такие как слои с разреженной активацией, слои dropout, слои батч-нормализации с применением нормализации по статистике обучающего набора (Instance Normalization) и другие. Архитектуры GAN часто являются предметом исследований и экспериментов для достижения наилучшего качества генерации и дискриминации в зависимости от конкретной задачи.
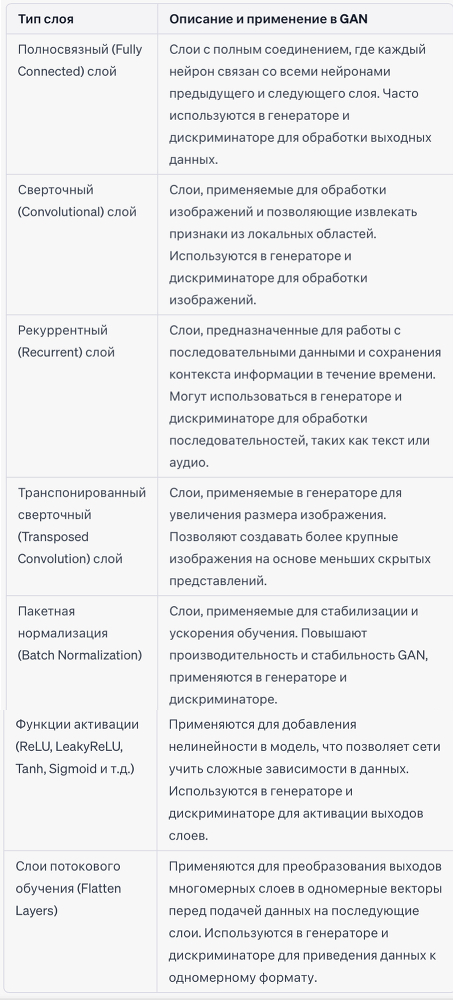
Для удобства понимания приведем таблицу, которая содержит типы слоем и их примеение в GAN:
Приведенная таблица не является исчерпывающим списком всех возможных слоев и их применения в генеративных нейронных сетях (GAN). Архитектуры GAN могут быть очень разнообразными и креативными, и различные задачи могут потребовать различных комбинаций слоев для достижения оптимальных результатов.
Для каждой конкретной задачи или типа данных, с которыми работает GAN, могут быть разработаны уникальные архитектуры, использующие сочетания различных слоев для наилучшего выполнения поставленной задачи. От выбора слоев и их гиперпараметров зависит успешность обучения и качество генерируемых данных.
Помимо уже упомянутых слоев, существуют и другие типы слоев, которые можно использовать в GAN в зависимости от контекста:
– Условные слои: позволяют управлять генерацией данных путем добавления дополнительной информации в виде условий. Это может быть полезно, например, для задач стилизации или модификации изображений.
– Трансформеры (Transformer Layers): представляют собой альтернативную архитектуру для работы с последовательными данными, такими как тексты или временные ряды.
– Residual Blocks: используются в генераторе для создания более глубоких сетей, помогая избежать проблемы затухания градиентов и улучшая процесс обучения.