В чем же тут подвох? В том, как и чем приходится за это расплачиваться. Вопрос лег в основу нашей первой истории, познакомившей читателя с основополагающей для ИИ концепцией глубокого обучения.
Глубокое обучение – прорыв в области искусственного интеллекта. Среди многих подобластей ИИ машинное обучение – это область, которая привела к наиболее успешным приложениям, а в машинном обучении самым большим достижением является направление под названием «глубокое обучение» – настолько, что термины «ИИ», «машинное обучение» и «глубокое обучение» иногда используются взаимозаменяемо (хотя это и неточно). В 2016 году глубокое обучение вызвало ажиотаж после впечатляющей победы AlphaGo над конкурентом-человеком в игре го, самой популярной интеллектуальной настольной игре в Азии. После этого нашумевшего поворота глубокое обучение стало важной частью большинства коммерческих приложений ИИ, и оно фигурирует в большинстве историй в AI 2041.
В «Золотом слоне» описан потрясающий потенциал глубокого обучения и его ловушки вроде воспроизведения социальных предрассудков в цифровых технологиях.
Так что же такое глубокое обучение? Каковы его ограничения? Какую роль в нем играют данные? Почему интернет и финансы считаются наиболее перспективными отраслями для применения ИИ на ранних этапах? Какие условия оптимальны для глубокого обучения? И почему кажется, что это работает чертовски хорошо – но только когда оно действительно работает? Каковы недостатки и недочеты ИИ?
ЧТО ТАКОЕ ГЛУБОКОЕ ОБУЧЕНИЕ?
Глубокое обучение вдохновлено сложнейшей сетью нейронов нашего мозга, оно строит программные многослойные искусственные нейронные сети с входными, скрытыми и выходными слоями. Данные поступают на входной слой – вход, а результат, соответственно, появляется на выходном слое. Между ними могут находиться тысячи других скрытых слоев – отсюда и «глубокое обучение».
Многие считают, что ИИ «программируется» или «обучается» людьми посредством указания конкретных правил и действий. Например, человек сообщает ИИ, что «у кошек заостренные уши и усы». Но на самом деле глубокое обучение работает лучше без внешних «человеческих» правил. Вместо того чтобы запоминать правила, данные людьми, на вход глубокой нейросети подается множество примеров, а на выход – правильные ответы для каждого из них. Таким образом, сеть между входом и выходом может быть «обучена», чтобы максимизировать шансы получить правильный ответ на заданный вход.
Есть множество примеров, когда человек не подсказывает, а передает информацию на входной слой и «правильный ответ» – на выходной слой.
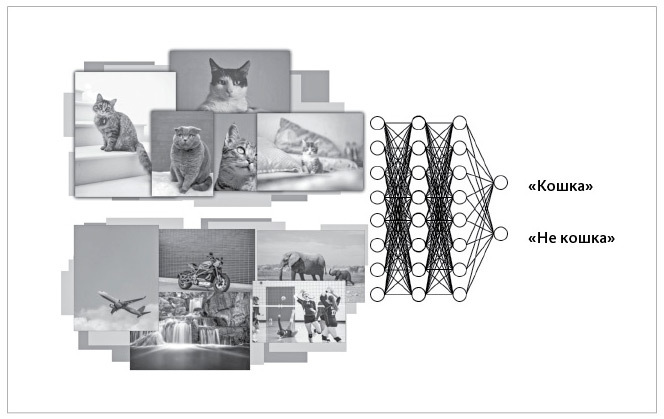
Представим, что исследователи хотят, чтобы сеть глубокого обучения отличала фотографии кошек от любых других изображений. Для начала исследователь может подать на входной слой миллионы разных фото, маркированных «кошка» или «не кошка»; при этом на выходном слое метки «кошка» или «не кошка» уже должны быть заданы.
Сеть обучается определять, какие признаки в миллионах изображений наиболее информативны для отделения «кошек» от «не кошек». Это обучение представляет собой математический процесс, настраивающий в сети глубокого обучения миллионы (а иногда и миллиарды) параметров, для того чтобы максимизировать вероятность того, что для изображения кошки на входе будет выдана метка «кошки», а для другого изображения – метка «не кошка». На рисунке ниже вы видите такую нейронную сеть глубокого обучения для «распознавания кошек».
Нейронная сеть глубокого обучения, обученная отличать фото кошек от фотографий, на которых изображено что-то другое
В ходе этого процесса глубокая нейросеть математически обучается (или «тренируется») максимизировать значение «целевой функции». В нашем примере с распознаванием кошки такой целевой функцией является вероятность правильного распознавания «кошка» – «не кошка».
После такой тренировки сеть глубокого обучения, по сути, становится гигантским математическим уравнением; его можно протестировать на изображениях, которых она до этого не видела, и убедиться, что сеть путем «умозаключений» способна определить наличие или отсутствие в этих изображениях кошки.
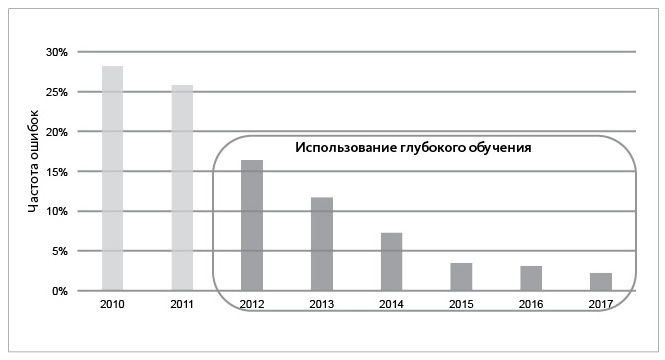
С появлением глубокого обучения совершенно непрактичные ранее возможности ИИ стали пригодными для применения во многих областях и сферах. На следующей диаграмме наглядно показано, как резко сократилось число ошибок распознавания образов, когда начали использовать технологии глубокого обучения.
Глубокое обучение – это технология универсального применения, ее можно использовать практически в любой области для распознавания образов, прогнозирования, классификации данных, принятия решений или синтеза. Возьмем сферу страхования, о которой идет речь в рассказе «Золотой слон».
ИИ в приложениях Ganesh Insurance предобучили оценивать вероятность развития у клиента компании серьезных проблем со здоровьем и соответствующим образом корректировать его страховой взнос.
Чтобы сеть научилась отделять тех, у кого с большой вероятностью возникнут такие проблемы, от тех, у кого они, скорее всего, не возникнут, ИИ «тренируют» на обучающих данных, включающих в себя информацию обо всех прошлых заявителях на получение страховки, обо всех их обращениях в медицинские учреждения с разными жалобами и об их семьях. Каждый случай маркируют на выходном слое меткой «обращался с серьезными медицинскими проблемами» или «не обращался с серьезными медицинскими проблемами».
Использование глубокого обучения привело к существенному снижению частоты ошибок при распознавании объектов компьютерным зрением
Впитав в себя в процессе предобучения весь этот набор данных, ИИ может делать предсказания вероятности возникновения у заявителя серьезных проблем со здоровьем и решать, одобрять заявку на страхование или нет, и если да, то каким при этом должен быть страховой взнос.
Обратите внимание: в данном сценарии ни одному человеку не придется маркировать претендента на оформление страховки как объект, имеющий риски с точки зрения здоровья или же не имеющий таковых. Эти метки основываются исключительно на «достоверной информации» (например, были ли у претендента на оформление страховки серьезные жалобы на здоровье в прошлом).
ГЛУБОКОЕ ОБУЧЕНИЕ: ПОТРЯСАЮЩИЕ ВОЗМОЖНОСТИ. НО – С ОГРАНИЧЕНИЯМИ
Первая научная статья о глубоком обучении вышла еще в 1967 году. Потребовалось более полувека, чтобы эта технология проявила себя. Это заняло так много времени, потому что для обучения искусственной нейронной сети требуется огромное количество данных и вычислительных мощностей. И если вычислительные мощности – двигатель ИИ, то данные – его топливо.
Вычисления стали достаточно быстрыми для эффективного применения технологии глубокого обучения только в последнее десятилетие, и мы наконец научились собирать достаточное количество данных. Смартфон, которым вы пользовались сегодня, обладает в миллионы раз большей вычислительной мощностью, чем компьютеры НАСА, отправившие Нила Армстронга на Луну в 1969 году. А интернет 2020 года почти в триллион раз больше интернета 1995 года.
Глубокое обучение – результат озарения человеческого мозга, но работают они совершенно по-разному. Глубокому обучению требуется гораздо больше данных, чем человеку, но после обучения работе с ними технология значительно превосходит людей в решении многих задач, особенно связанных с количественной оптимизацией (например, выбор рекламного объявления для максимизации вероятности покупки или поиск нужного лица среди миллионов других).
Люди могут одновременно сосредоточиваться на ограниченном количестве объектов, а алгоритм, предобученный на океане информации, выявляет корреляции между неявными признаками, слишком незаметными или сложными для человека.