Как выглядит этот адрес? Согласно некоторым моделям, он представляет собой своего рода неструктурированный список, фиксирующий последовательность букв З-Р-Е-Н-И-Е. Другие модели предполагают, что мозг опирается на абстрактный и условный код, похожий на случайный шифр: скажем, [1296] – это слово «зрение», а [3452] – это «трение». Однако современные исследования говорят в пользу другой гипотезы. Каждое написанное слово, по всей вероятности, кодируется иерархическим деревом. В нем буквы объединены в более крупные единицы, которые, в свою очередь, сгруппированы в слоги и слова. Точно так же человеческое тело можно представить в виде совокупности ног, рук, туловища и головы, состоящих из более простых частей. В мозге человека каждое написанное слово кодируется иерархическим деревом, в котором буквы объединены в более крупные единицы, а те, в свою очередь, сгруппированы в слоги и слова.
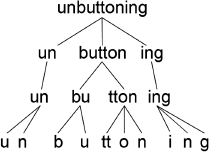
В качестве примера мысленного разложения слов на значимые единицы разберем английское слово «unbuttoning» («отстегивание», «расстегивание»). Сначала уберем приставку un- и характерный суффикс или грамматическое окончание – ing. Оба обрамляют центральный элемент – корень «button». Все три компонента называются морфемами – мельчайшими единицами, несущими некий смысл. На этом уровне каждое слово характеризуется особой комбинацией составляющих его морфем. Разбиение слова на морфемы позволяет нам понимать даже те слова, которые мы никогда раньше не видели, например «reunbutton» (буквально – «снова отстегивать»; приставка re- предполагает повтор действия) или «deglochization» (приставка de- обозначает отмену, прекращение чего-либо; значит, «deglochization» – это аннулирование действия «gloching», в чем бы оно ни заключалось). В некоторых языках, таких как турецкий или финский, морфемы могут быть сгруппированы в очень длинные слова, которые передают столько же информации, сколько целое английское предложение. В этих языках, как и в английском, разложение слова на морфемы является важным шагом на пути от визуального восприятия к смыслу.
Экспериментальные данные показывают, что наша зрительная система очень быстро и абсолютно бессознательно отсекает морфемы слов. Например, если на мониторе компьютера на мгновение высветится слово «поезд», то позже, увидев слово «отъезд»[33], вы произнесете его немного быстрее. Предъявление слова «поезд», по-видимому, заранее активирует морфему – езд, тем самым облегчая к ней доступ в будущем. В таких ситуациях психологи говорят об эффекте прайминга (предшествования) – чтение одного слова стимулирует распознавание родственных ему слов. Примечательно, что эффект прайминга зависит не только от зрительного сходства: слова, которые выглядят совершенно по-разному, но имеют общую морфему, например «мог» и «может», ускоряют распознавание друг друга, в то время как похожие, но не имеющие тесной морфологической связи, например «аспирант» и «аспирин»[34], – нет. Кроме того, эффект прайминга не требует сходства на уровне смысла. Такие слова, как «речь» и «речка» или «нос» и «носить»[35], могут стимулировать друг друга, даже если их значения по существу никак не связаны[36]. Переход к морфемному уровню, по-видимому, имеет столь важное значение для нашей системы чтения, что она охотно строит догадки относительно морфемного состава слов. Наш считывающий аппарат разбивает слово «носить» на нос- + – ить[37] в надежде, что это облегчит задачу операторам, вычисляющим его значение[38]. Неважно, что это работает не всегда. Например, «горец» не обязательно горюет, а «лукавый» не имеет никакого отношения к растениям[39]. Такие ошибки будут исправлены на последующих стадиях процесса анализа слова.
Продолжим разбирать английское слово «unbuttoning». Сама по себе морфема – button- тоже не является неделимым целым. Она состоит из двух слогов, – b- и – ton-, каждый из которых может быть разбит на отдельные согласные и гласные: [b] [] [t] [o] [n]. Здесь кроется еще одна важная единица для нашей системы чтения: графема. Графема – это буква или ряд букв, которые соответствуют одной фонеме. Обратите внимание: в нашем примере две буквы «tt» соотносятся с одним звуком [t][40]. Очевидно, что процесс преобразования графем в фонемы не всегда носит прямой характер. Во многих языках графемы могут состоять из нескольких букв. Английский язык, например, может похвастаться особенно обширной коллекцией сложных графем, таких как «ough», «oi» и «au».
Наша зрительная система научилась воспринимать эти комбинации как определенные единицы, а потому почти не обращает внимания на их фактический буквенный состав. Чтобы в этом убедиться, проведем простой эксперимент. Изучите список ниже и отметьте слова, которые содержат букву «а»:
garage
metal
people
coat
please
meat
Вы заметили, что вам пришлось чуть-чуть «сбросить скорость» на последних трех словах: «coat» [kut], «please» [pli: z] и «meat» [mi: t]? Все они содержат букву «а», но она встроена в сложную графему, которая не произносится как [a]. Полагайся мы исключительно на детекторы букв, разбиение слова на составляющие его графемы не имело бы значения. Однако фактические измерения скорости реакции ясно показывают, что наш мозг не останавливается на уровне одной буквы. Поскольку зрительная система автоматически перегруппирует буквы в графемы более высокого уровня, заметить, что такие сочетания букв, как «ea», на самом деле содержат букву «a», не так-то просто[41].
В свою очередь, графемы автоматически группируются в слоги. Проведем еще один эксперимент. Ниже вы увидите слова из пяти букв. Одни буквы напечатаны жирным шрифтом, другие – обычным. Сосредоточьтесь исключительно на средней букве и попытайтесь определить, каким шрифтом она напечатана[42]:
Список 1: ВОЙНА АКТЕР СКАЛА ОТДЕЛ
Список 2: ВОДКА МЕТРО ЛОДКА СУПЕР
Вам не показалось, что первый список немного сложнее, чем второй? В нем знаки, выделенные жирным шрифтом, не совпадают с делением на слоги – например, в слове «АКТЕР» буква «Т» напечатана жирным шрифтом, а остальная часть слога – обычным. Поскольку наш ум склонен автоматически группировать буквы в слоги, возникает конфликт, который приводит к существенному замедлению реакции[43]. Это свидетельствует о том, что наша зрительная система не может не разбивать слова на их элементарные составляющие, причем даже в тех случаях, когда лучше этого не делать.
Изучение природы этих составляющих – одно из важнейших направлений научных исследований. Казалось бы, множественные уровни анализа вполне могут сосуществовать друг с другом: сначала одна буква, затем пара букв (или биграмма, важная единица, к которой мы вернемся чуть позже), графема, слог, морфема и все слово целиком. На последней стадии зрительной обработки слово оказывается разбитым на иерархическую структуру, похожую на дерево. Это дерево состоит из постепенно утолщающихся ветвей с буквами вместо листьев.
Таким образом, лишенная всех своих несущественных свойств вроде шрифта, регистра и размера, буквенная цепочка разбивается на элементарные компоненты. Именно они будут использованы остальной частью мозга для вычисления звука и значения.